scrapy中对于item的把控
其实很简单,就是想要存储的位置发生改变。直接看例子,然后触类旁通。
以大众点评 评论的内容为例 ,位置:http://www.dianping.com/shop/77489519/review_more?pageno=1
数据存储形式由A 变成B
A:
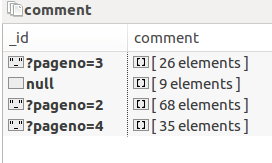
展开的话这样子:
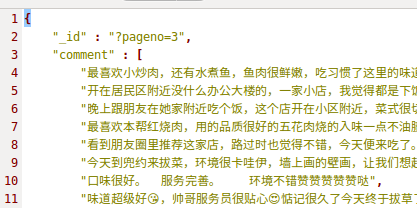
B:
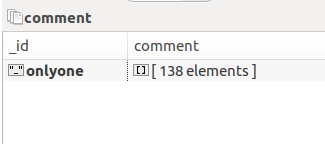
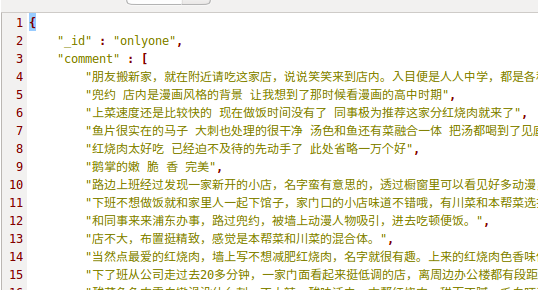
本质上看,就是多个相同类型的item可以合并,不需要那么多,分别来看下各自的代码:
A:
class GengduopinglunSpider(scrapy.Spider):
name = 'gengduopinglun'
start_urls = ['http://www.dianping.com/shop/77489519/review_more?pageno=1'] def parse(self, response):
item=PinglunItem()
comment = item['comment'] if "comment" in item else []
for i in response.xpath('//div[@class="content"]'):
for j in i.xpath('.//div[@class="J_brief-cont"]/text()').extract():
comment.append(j.strip())
item['comment']=comment
next_page = response.xpath(
'//div[@class="Pages"]/div[@class="Pages"]/a[@class="NextPage"]/@href').extract_first()
item['_id']=next_page
# item['_id']='onlyone'
if next_page != None:
next_page = response.urljoin(next_page)
# yield Request(next_page, callback=self.shop_comment,meta={'item': item})
yield Request(next_page, callback=self.parse,)
yield item
B:
class GengduopinglunSpider(scrapy.Spider):
name = 'gengduopinglun'
start_urls = ['http://www.dianping.com/shop/77489519/review_more?pageno=1'] def parse(self, response):
item=PinglunItem()
comment = item['comment'] if "comment" in item else []
for i in response.xpath('//div[@class="content"]'):
for j in i.xpath('.//div[@class="J_brief-cont"]/text()').extract():
comment.append(j.strip())
item['comment']=comment
next_page = response.xpath(
'//div[@class="Pages"]/div[@class="Pages"]/a[@class="NextPage"]/@href').extract_first()
# item['_id']=next_page
item['_id']='onlyone'
if next_page != None:
next_page = response.urljoin(next_page)
yield Request(next_page, callback=self.shop_comment,meta={'item': item})
# yield Request(next_page, callback=self.parse,)
# yield item def shop_comment(self, response):
item = response.meta['item']
comment = item['comment'] if "comment" in item else []
for i in response.xpath('//div[@class="content"]'):
for j in i.xpath('.//div[@class="J_brief-cont"]/text()').extract():
comment.append(j.strip())
item['comment']=comment
next_page = response.xpath(
'//div[@class="Pages"]/div[@class="Pages"]/a[@class="NextPage"]/@href').extract_first()
if next_page != None:
next_page = response.urljoin(next_page)
yield Request(next_page, callback=self.shop_comment,meta={'item': item})
yield item
B里面是有重复代码的,这个无关紧要,只是演示,注意看两个yield 的区别
以上只是演示scrapy中yield的用法,用来控制item,其余pipline,setting未展示.
scrapy中对于item的把控的更多相关文章
- Scrapy中的item是什么
这两天看Scrapy,看到item这个东西,觉得有点抽象,查了一下,有点明白了. Item 是保存爬取到的数据的容器:其使用方法和python字典类似, 并且提供了额外保护机制来避免拼写错误导致的未定 ...
- 关于ListView中item与子控件抢夺焦点的解决方法
1.在开发中,listview可以说是我们使用最频繁的控件之一了,但是关于listview的各种问题也是很多.当我们使用自定义布局的Listview的时候,如果在item的布局文件里面存在Button ...
- 手把手教你进行Scrapy中item类的实例化操作
接下来我们将在爬虫主体文件中对Item的值进行填充. 1.首先在爬虫主体文件中将Item模块导入进来,如下图所示. 2.第一步的意思是说将items.py中的ArticleItem类导入到爬虫主体文件 ...
- 第十七节:Scrapy爬虫框架之item.py文件以及spider中使用item
Scrapy原理图: item位于原理图的最左边 item.py文件是报存爬取数据的容器,他使用的方法和字典很相似,但是相比字典item多了额外的保护机制,可以避免拼写错误或者定义错误. 1.创建it ...
- Scrapy中使用cookie免于验证登录和模拟登录
Scrapy中使用cookie免于验证登录和模拟登录 引言 python爬虫我认为最困难的问题一个是ip代理,另外一个就是模拟登录了,更操蛋的就是模拟登录了之后还有验证码,真的是不让人省心,不过既然有 ...
- scrapy中的request
scrapy中的request 初始化参数 class scrapy.http.Request( url [ , callback, method='GET', headers, body, cook ...
- [转]scrapy中的request.meta
作者:知乎用户链接:https://www.zhihu.com/question/54773510/answer/146971644 meta属性是字典,字典格式即{'key':'value'},字典 ...
- 论Scrapy中的数据持久化
引入 Scrapy的数据持久化,主要包括存储到数据库.文件以及内置数据存储. 那我们今天就来讲讲如何把Scrapy中的数据存储到数据库和文件当中. 终端指令存储 保证爬虫文件的parse方法中有可迭代 ...
- 使用scrapy中xpath选择器的一个坑点
情景如下: 一个网页下有一个ul,这个ur下有125个li标签,每个li标签下有我们想要的 url 字段(每个 url 是唯一的)和 price 字段,我们现在要访问每个li下的url并在生成的请求中 ...
随机推荐
- js正则表达式----replace
1.分组 '442665319@qq.com'.replace(/(\d+)(@)(\w+)(\.com)/,'[$1]$2[$3]$4') //"[442665319]@[qq].com& ...
- RACCommand
RACCommand是ReactiveCocoa中用于表示UI操作的一个类.它包含一个代表了UI操作的结果的信号以及标识操作当前是否被执行的一个状态. 1.创建新的RACCommand self.ex ...
- java.lang.NoClassDefFoundError: org/hibernate/service/ServiceRegistry] 类似问题
使用Hibernate时出现以上错误,在Java Project中运行无误,但是来到Dynamic Web Project中却出现了如下错误: hibernate 报错:java.lang.NoCla ...
- 2017 清北济南考前刷题Day 6 morning
T1 贪心 10 元先找5元 20元 先找10+5,再找3张5 #include<cstdio> using namespace std; int m5,m10,m20; int main ...
- 2016/1/2 Python中的多线程(1):线程初探
---恢复内容开始--- 新年第一篇,继续Python. 先来简单介绍线程和进程. 计算机刚开始发展的时候,程序都是从头到尾独占式地使用所有的内存和硬件资源,每个计算机只能同时跑一个程序.后来引进了一 ...
- hive介绍
我最近研究了hive的相关技术,有点心得,这里和大家分享下. 首先我们要知道hive到底是做什么的.下面这几段文字很好的描述了hive的特性: 1.hive是基于Hadoop的一个数据仓库工具,可以将 ...
- soj1011. Lenny's Lucky Lotto
1011. Lenny's Lucky Lotto Constraints Time Limit: 1 secs, Memory Limit: 32 MB Description Lenny like ...
- PartyPlay发布版
发布版本在beta版本的基础之上修改了pose王中的显示函数部分,使其可以正常的多次显示不同图片,不会出现卡在一张图片的问题上. 因此总的发布版本内容: 1.谁是卧底: 点击进入谁是卧底,进入游戏前的 ...
- 【转】 jquery easyui datagrid使用,分页、排序、查询
$('#dg').datagrid({ url: "xxx.ashx", pagination: true, p ...
- Python概念-定制自己的数据类型(包装)
包装:python为大家提供了标准数据类型,以及丰富的内置方法,其实在很多场景下我们都需要基于标准数据类型来定制我们自己的数据类型,新增/改写方法,这就用到了我们刚学的继承/派生知识(其他的标准类型均 ...