Spark RDD(Resilient Distributed Dataset)
基于数据集的处理:从物理存储上加载数据,然后操作数据,然后写入物理存储设备。比如Hadoop的MapReduce。
缺点:1.不适合大量的迭代 2. 交互式查询 3. 不能复用曾经的结果或中间计算结果
基于工作集的处理:如Spark的RDD。
RDD具有如下的弹性:
1. 自动的进行内存和磁盘数据存储的切换
2. 基于Lineage的高效容错
3. Task如果失败会自动进行特定次数的重试
4. Stage如果失败会自动进行特定次数的重试,而且只会计算失败的分片
5. Checkpoint和persist (用于计算结果复用)
6. 数据分片的高度弹性
RDD的写操作是粗粒度的,读操作既可以是粗粒度的也可以是细粒度的.
RDD是分布式函数式编程的抽象。
RDD通过记录数据更新的方式为何高效?
1. RDD是不可变的 + lazy
创建RDD的几种方式:1. 程序中的集合(主要用于测试) 2. 使用本地文件系统(主要用于测试较大量的数据) 3. 使用HDFS 4. 基于DB。5. 基于S3 6. 基于数据流
RDD 依赖分为宽依赖和窄依赖
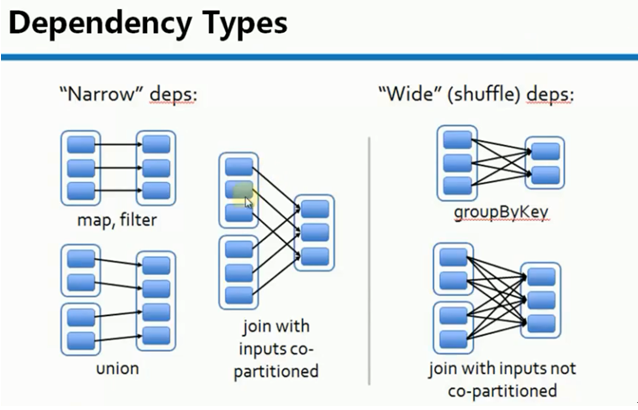
1. 窄依赖是指每个父RDD的Partition最多被子RDD的一个Partition使用。例如:map, filter等会产生窄依赖
2. 宽依赖是指一个父RDD的Partition会被多个子RDD的Partition使用。例如:groupByKey,reduceByKey等会产生宽依赖
宽依赖会产生Shuffle
特别说明:对于join操作有两种情况,如果说join的时候,每个Partition仅仅和已知的Partition进行join,则此时的join操作就是窄依赖;其它情况是宽依赖.
窄依赖不仅包含一对一的窄依赖,还包含一对固定个数的窄依赖(也就是说对父RDD的依赖的Partition的数量不会随着RDD数据规模的改变而改变)
Stage的划分:
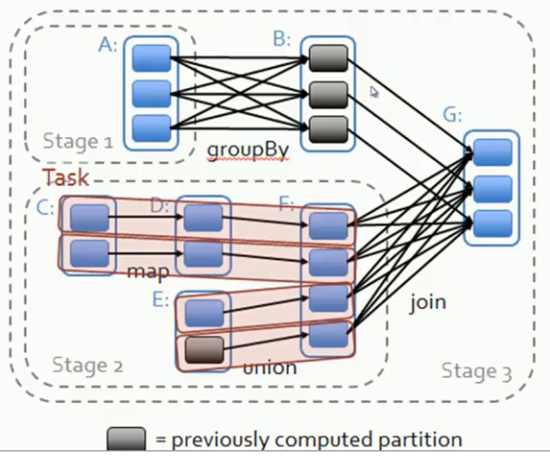
1. 从后往前推,遇到宽依赖就断开,遇到窄依赖就把当前RDD加入到Stage中
2. 每个Stage里面的Task的数量是由该Stage中最后一个RDD的Partition的数量所决定的。
3. 最后一个Stage里面的任务类型是ResultTask,前面其它所有的Stage里面的任务的类型是ShuffleMapTask
窄依赖的物理执行内幕:
一个Stage内部的RDD都是窄依赖,窄依赖计算本身,从逻辑上看是从Stage内部最左侧的RDD开始立即计算的,根据Computing Chain,数据从一个计算步骤流动到下一个计算步骤,以此类推,直到计算到Stage内部的最一个RDD来产生计算结果。
Computing Chain的构建是从后往前回溯构建而成的,而实际的物理计算则是让数据从前往后在算子上流动,直到流动到不能再流动位置才开始计算下一个Record。这就导致了一个美好的结果:后面的RDD不需要等待前面的RDD全部计算完毕才进行计算,极大的提高了计算效率。
宽依赖物理执行内幕:
必须等到依赖的父Stage中最后一个RDD把全部数据计算完毕才能够经过Shuffle来计算当前的Stage.
Spark RDD(Resilient Distributed Dataset)的更多相关文章
- 【Spark】RDD(Resilient Distributed Dataset)究竟是什么?
目录 基本概念 官方文档 概述 含义 RDD出现的原因 五大属性 以单词统计为例,一张图熟悉RDD当中的五大属性 解构图 RDD弹性 RDD特点 分区 只读 依赖 缓存 checkpoint 基本概念 ...
- spark RDD,DataFrame,DataSet 介绍
弹性分布式数据集(Resilient Distributed Dataset,RDD) RDD是Spark一开始就提供的主要API,从根本上来说,一个RDD就是你的数据的一个不可变的分布式元素集合,在 ...
- 2. RDD(弹性分布式数据集Resilient Distributed dataset)
*以下内容由<Spark快速大数据分析>整理所得. 读书笔记的第二部分是讲RDD.RDD 其实就是分布式的元素集合.在 Spark 中,对数据的所有操作不外乎创建RDD.转化已有RDD以及 ...
- [bigdata] Spark RDD整理
1. RDD是什么RDD:Spark的核心概念是RDD (resilient distributed dataset),指的是一个只读的,可分区的弹性分布式数据集,这个数据集的全部或部分可以缓存在内存 ...
- Spark RDD基本概念与基本用法
1. 什么是RDD RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行计算的集合.RDD具 ...
- RDD, DataFrame or Dataset
总结: 1.RDD是一个Java对象的集合.RDD的优点是更面向对象,代码更容易理解.但在需要在集群中传输数据时需要为每个对象保留数据及结构信息,这会导致数据的冗余,同时这会导致大量的GC. 2.Da ...
- Spark RDD理解-总结
1.spark是什么 快速.通用.可扩展的分布式计算引擎. 2. 弹性分布式数据集RDD RDD(Resilient Distributed Dataset),是Spark中最基本的数据抽象结构,表示 ...
- Spark的核心RDD(Resilient Distributed Datasets弹性分布式数据集)
Spark的核心RDD (Resilient Distributed Datasets弹性分布式数据集) 原文链接:http://www.cnblogs.com/yjd_hycf_space/p/7 ...
- RDD内存迭代原理(Resilient Distributed Datasets)---弹性分布式数据集
Spark的核心RDD Resilient Distributed Datasets(弹性分布式数据集) Spark运行原理与RDD理论 Spark与MapReduce对比,MapReduce的计 ...
随机推荐
- MFC实现COM组件
一般而言,ATL实现了对COM组件最好的支持,所以不用MFC实现COM组件.但是MFC实际上也是可以实现COM组件的. 一.MFC DLL优点: MFC com组件可以将MFC的类型作为参数进行传递, ...
- python中zip()函数基本用法
zip()函数接受一系列可迭代对象作为参数,将不同对象中相对应的元素打包成一个元组(tuple),返回由这些元组组成的list列表,如果传入的参数的长度不等,则返回的list列表的长度和传入参数中 ...
- 浅谈MVC、MVP、MVVM模式
mvc的模式已经深入人心,想必大家都很熟悉,但是未必都能遵守mvc模式.我们的一个mvc项目比较简单,主要是数据库的查询.一个DBHelp类,封装了数据库的操作,然后Controller中进行中各种查 ...
- mysql绿色安装
先下载需要的文件: MySQL5.1(绿色).rar 和 MySQL-Front_v5.3(绿色版).rar 都是绿色免安装版 1.解压MySQL Server 5.1.rar到MySQL Serve ...
- keepalived+nginx实现双机热备
keepalived是一个类似于layer3, 4, 5 交换机制的软件,也就是我们平时说的第3层.第4层和第5层交换.Keepalived的作用是检测web服务器的状态,如果有一台web服务器死机, ...
- MySQL Sending data导致查询很慢的问题详细分析
这两天帮忙定位一个MySQL查询很慢的问题,定位过程综合各种方法.理论.工具,很有代表性,分享给大家作为新年礼物:) [问题现象] 使用sphinx支持倒排索引,但sphinx从mysql查询源数据的 ...
- 人物-IT-任正非:任正非
ylbtech-人物-IT-任正非:任正非 任正非,祖籍浙江省浦江县,1944年10月25日出生于贵州省安顺市镇宁县.华为技术有限公司主要创始人兼总裁. 1963年就读于重庆建筑工程学院(现已并入重庆 ...
- kubeadm 搭建 K8S集群
kubeadm是K8s官方推荐的快速搭建K8s集群的方法. 环境: Ubuntu 16.04 1 安装docker Install Docker from Ubuntu’s repositories: ...
- 二 vue环境搭建
一: 新建一个项目文件夹,命名为 vue-demo,cd到此文件夹,输入:vue init webpack vue-demo,回车,按照如下操作进行初始化: 2: 项目结构 3: 安装项目依赖的包 ...
- Linux查看并修改mysql的编码
系统:阿里云 一.查看mysql字符集 输入:show variables like 'character_set_%'; 二.修改某一个数据库的编码 输入:alter database dbname ...