【Spark】RDD(Resilient Distributed Dataset)究竟是什么?
基本概念
官方文档
介绍RDD的官方说明:http://spark.apache.org/docs/latest/rdd-programming-guide.html
概述
含义
RDD (Resilient Distributed Dataset) 叫做 弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将数据缓存在内存中,后续的查询能够重用这些数据,这极大地提升了查询速度。
Resilient —— RDD中的数据优先装在内存当中进行处理,如果内存不够用了,就将数据放到磁盘上面去处理。
Distributed —— RDD中的数据是分布式存储的,可用于分布式计算。
Dataset —— 一个数据集合,用于存放数据的。
RDD出现的原因
RDD是Spark的基石,是实现Spark数据处理的核心抽象。
最初,第一代计算引擎为Hadoop的MapReduce时,开始可以使用代码来实现数据分析处理等。但这种方法需要使用大量代码,比较复杂,不算高效。
之后,第二代计算引擎——Hive出现后,使用hql来实现数据分析,摆脱了MapReduce的繁琐的代码。但这种方法的缺点依然比较明显,就是执行效率慢。
第三代计算引擎以impala、Spark为代表的内存计算框架,开始将数据尽量放到内存中计算,RDD的概念也伴随而生。
五大属性
- A list of partitions 分区列表
- A function for computing each split 作用在每一个文件切片上面的函数
- A list of dependencies on other RDDs 依赖于其他的一些RDD
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned) 可选项:对于key,value对的rdd,有分区函数
- Optionally, a list of preferred locations to compute each split on (e.g. block locations for
an HDFS file) 可选项:数据的位置优先性来进行计算。移动计算比移动数据便宜
所谓移动计算比移动数据便宜,是指 如果文件在哪一台服务器上面,就在哪一台服务器上面启动task进行运算,尽量避免数据的拷贝
1.对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度,如果文件的block个数小于等于2,那么默认分区为2,如果大于等于2,则分区数为block的个数。
2.Spark中每个RDD都会实现compute函数,以此来达到让RDD的计算都是以分片为单位的目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。
3.RDD每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系,在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区重新计算。
4.Spark中实现了两种类型的分片函数,一种是基于哈希的HashPartitioner,一种是基于范围的RangePartitioner。只有对于key-value的RDD才会有Partitioner,非key-value的RDD的Partitioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
以单词统计为例,一张图熟悉RDD当中的五大属性
解构图
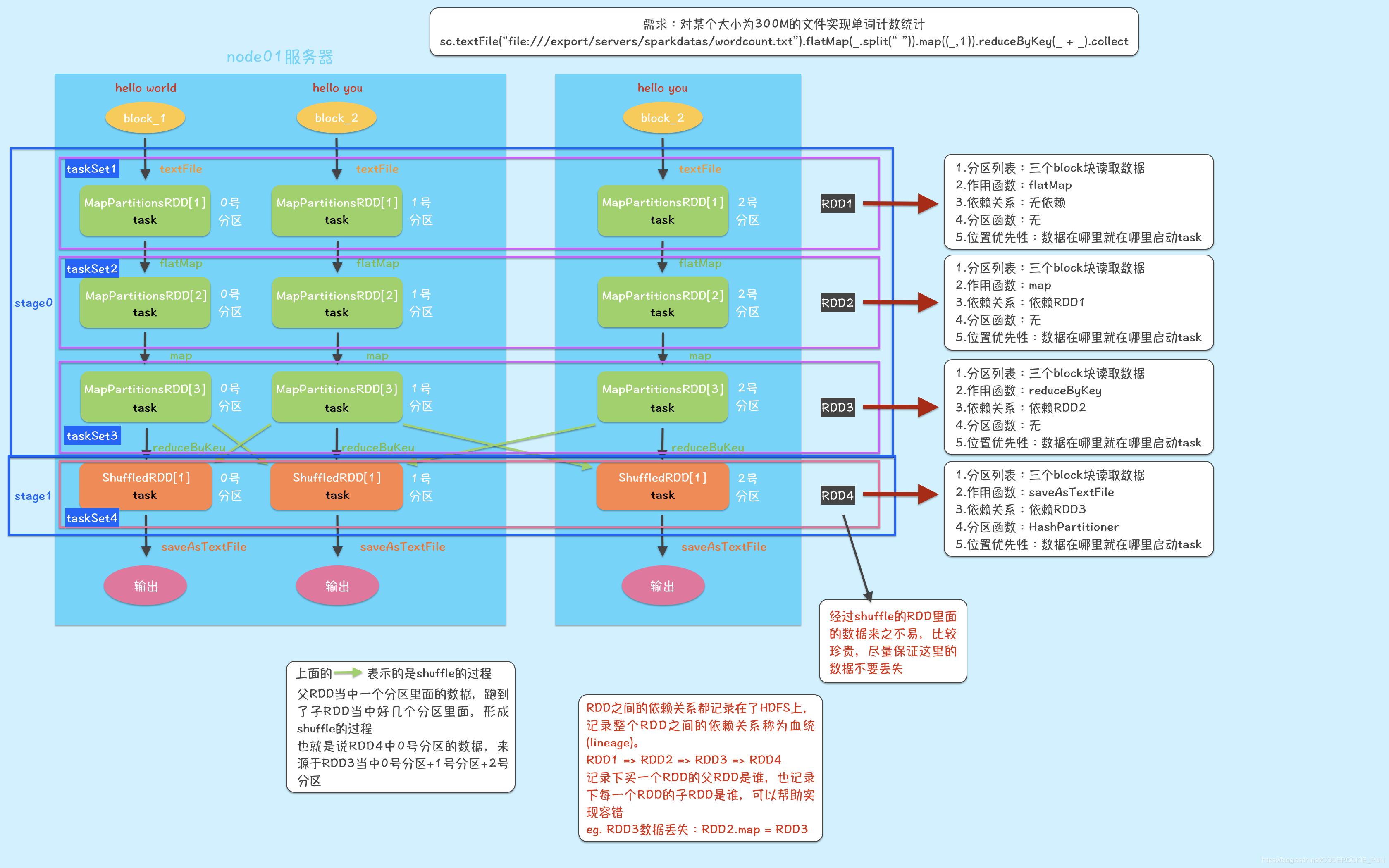
RDD弹性
一、自动进行内存以及磁盘文件切换
二、基于血统lineage的高效容错性。lineage记录了rdd之间的依赖关系
三、task执行失败自动进行重试
四、stage失败自动进行重试
五、checkpoint实现数据的持久化保存
基于RDDs之间的依赖,RDDs会形成一个有向无环图DAG,该DAG描述了整个流式计算的流程,实际执行的时候,RDD是通过血缘关系(Lineage)一气呵成的,即使出现数据分区丢失,也可以通过血缘关系重建分区
RDD特点
分区
只读
rdd当中的数据是只读的,不能更改
依赖
缓存
常用的rdd我们可以给缓存起来
checkpoint
对于一些常用的rdd我们也可以试下持久化
【Spark】RDD(Resilient Distributed Dataset)究竟是什么?的更多相关文章
- Spark RDD(Resilient Distributed Dataset)
基于数据集的处理:从物理存储上加载数据,然后操作数据,然后写入物理存储设备.比如Hadoop的MapReduce. 缺点:1.不适合大量的迭代 2. 交互式查询 3. 不能复用曾经的 ...
- spark RDD,DataFrame,DataSet 介绍
弹性分布式数据集(Resilient Distributed Dataset,RDD) RDD是Spark一开始就提供的主要API,从根本上来说,一个RDD就是你的数据的一个不可变的分布式元素集合,在 ...
- 2. RDD(弹性分布式数据集Resilient Distributed dataset)
*以下内容由<Spark快速大数据分析>整理所得. 读书笔记的第二部分是讲RDD.RDD 其实就是分布式的元素集合.在 Spark 中,对数据的所有操作不外乎创建RDD.转化已有RDD以及 ...
- [bigdata] Spark RDD整理
1. RDD是什么RDD:Spark的核心概念是RDD (resilient distributed dataset),指的是一个只读的,可分区的弹性分布式数据集,这个数据集的全部或部分可以缓存在内存 ...
- Spark RDD基本概念与基本用法
1. 什么是RDD RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行计算的集合.RDD具 ...
- RDD, DataFrame or Dataset
总结: 1.RDD是一个Java对象的集合.RDD的优点是更面向对象,代码更容易理解.但在需要在集群中传输数据时需要为每个对象保留数据及结构信息,这会导致数据的冗余,同时这会导致大量的GC. 2.Da ...
- Spark RDD理解-总结
1.spark是什么 快速.通用.可扩展的分布式计算引擎. 2. 弹性分布式数据集RDD RDD(Resilient Distributed Dataset),是Spark中最基本的数据抽象结构,表示 ...
- Spark的核心RDD(Resilient Distributed Datasets弹性分布式数据集)
Spark的核心RDD (Resilient Distributed Datasets弹性分布式数据集) 原文链接:http://www.cnblogs.com/yjd_hycf_space/p/7 ...
- RDD内存迭代原理(Resilient Distributed Datasets)---弹性分布式数据集
Spark的核心RDD Resilient Distributed Datasets(弹性分布式数据集) Spark运行原理与RDD理论 Spark与MapReduce对比,MapReduce的计 ...
随机推荐
- for循环,for…in循环,forEach循环的区别
for循环,for…in循环,forEach循环的区别for循环通关for循环,生成所有的索引下标for(var i = 0 ; i <= arr.length-1 ; i++){ 程序内容 } ...
- python这门语言为什么要起这个名字
我只是一只可爱的小虫 前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:Liz喵 PS:如有需要Python学习资料的小 ...
- Shell脚本日志关键字监控+告警
最近小张的爬虫程序越来越多,可当爬虫程序报错,不能及时的发现,从而造成某些重要信息不能及时获取的问题,更有甚者,遭到领导的批评.于是就在想有没有一种方法,当爬取信息报错的时候,可以通过邮件或者短信的方 ...
- python函数-易错知识点
定义函数: def greet_users(names): #names是形参 """Print a simple greeting to each user in th ...
- 不停机还能替换代码?6年的 Java程序员表示不可思议
相信很多人都有这样一种感受,自己写的代码在开发.测试环境跑的稳得一笔,可一到线上就抽风,不是缺这个就是少那个反正就是一顿报错,而线上调试代码又很麻烦,让人头疼得很.不过, 阿里巴巴出了一款名叫Arth ...
- 从头学pytorch(十三):使用GPU做计算
GPU计算 默认情况下,pytorch将数据保存在内存,而不是显存. 查看显卡信息 nvidia-smi 我的机器输出如下: Fri Jan 3 16:20:51 2020 +------------ ...
- nginx history路由模式时,页面返回404重定向index.html
1.路由默认是带#的,有时我们感觉不美观,就使其变为history模式,也就没有#字符 2.# 如果找不到当前页面(404),就返回index.html,重新分配路由 location ^~/prod ...
- Service Location Protocol SLP
https://www.ibm.com/developerworks/cn/linux/l-slp/ 服务发现(service discovery) 是在网络环境中发现必须使用的服务的能力.例如,如果 ...
- [Batch 脚本] 批量生成文件夹
@echo off echo start set time=30000 echo %time% for /l %%i in (1,1, %time%) do ( echo %%i% md " ...
- 《SQL初学者指南》——第1章 关系型数据库和SQL
第1章 关系型数据库和SQL SQL初学者指南在本章中,我们将介绍一些背景知识,以便于你能够很快地上手,能在后续的章节中编写SQL语句.本章有两个主题.首先是对本书所涉及到的数据库做一个概述,并且介绍 ...