Spark RDD(Resilient Distributed Dataset)
基于数据集的处理:从物理存储上加载数据,然后操作数据,然后写入物理存储设备。比如Hadoop的MapReduce。
缺点:1.不适合大量的迭代 2. 交互式查询 3. 不能复用曾经的结果或中间计算结果
基于工作集的处理:如Spark的RDD。
RDD具有如下的弹性:
1. 自动的进行内存和磁盘数据存储的切换
2. 基于Lineage的高效容错
3. Task如果失败会自动进行特定次数的重试
4. Stage如果失败会自动进行特定次数的重试,而且只会计算失败的分片
5. Checkpoint和persist (用于计算结果复用)
6. 数据分片的高度弹性
RDD的写操作是粗粒度的,读操作既可以是粗粒度的也可以是细粒度的.
RDD是分布式函数式编程的抽象。
RDD通过记录数据更新的方式为何高效?
1. RDD是不可变的 + lazy
创建RDD的几种方式:1. 程序中的集合(主要用于测试) 2. 使用本地文件系统(主要用于测试较大量的数据) 3. 使用HDFS 4. 基于DB。5. 基于S3 6. 基于数据流
RDD 依赖分为宽依赖和窄依赖
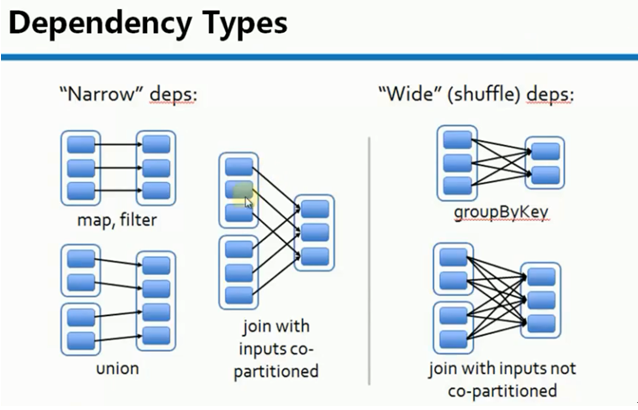
1. 窄依赖是指每个父RDD的Partition最多被子RDD的一个Partition使用。例如:map, filter等会产生窄依赖
2. 宽依赖是指一个父RDD的Partition会被多个子RDD的Partition使用。例如:groupByKey,reduceByKey等会产生宽依赖
宽依赖会产生Shuffle
特别说明:对于join操作有两种情况,如果说join的时候,每个Partition仅仅和已知的Partition进行join,则此时的join操作就是窄依赖;其它情况是宽依赖.
窄依赖不仅包含一对一的窄依赖,还包含一对固定个数的窄依赖(也就是说对父RDD的依赖的Partition的数量不会随着RDD数据规模的改变而改变)
Stage的划分:
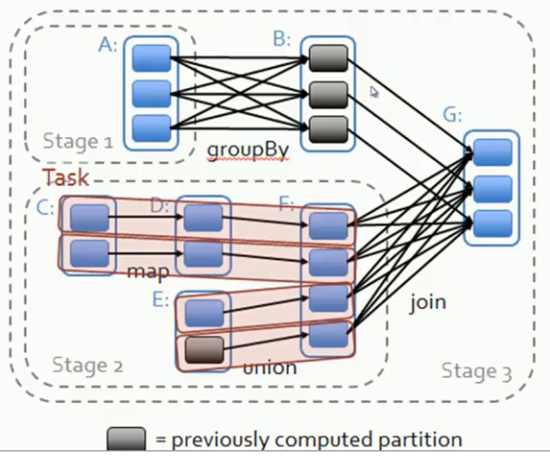
1. 从后往前推,遇到宽依赖就断开,遇到窄依赖就把当前RDD加入到Stage中
2. 每个Stage里面的Task的数量是由该Stage中最后一个RDD的Partition的数量所决定的。
3. 最后一个Stage里面的任务类型是ResultTask,前面其它所有的Stage里面的任务的类型是ShuffleMapTask
窄依赖的物理执行内幕:
一个Stage内部的RDD都是窄依赖,窄依赖计算本身,从逻辑上看是从Stage内部最左侧的RDD开始立即计算的,根据Computing Chain,数据从一个计算步骤流动到下一个计算步骤,以此类推,直到计算到Stage内部的最一个RDD来产生计算结果。
Computing Chain的构建是从后往前回溯构建而成的,而实际的物理计算则是让数据从前往后在算子上流动,直到流动到不能再流动位置才开始计算下一个Record。这就导致了一个美好的结果:后面的RDD不需要等待前面的RDD全部计算完毕才进行计算,极大的提高了计算效率。
宽依赖物理执行内幕:
必须等到依赖的父Stage中最后一个RDD把全部数据计算完毕才能够经过Shuffle来计算当前的Stage.
Spark RDD(Resilient Distributed Dataset)的更多相关文章
- 【Spark】RDD(Resilient Distributed Dataset)究竟是什么?
目录 基本概念 官方文档 概述 含义 RDD出现的原因 五大属性 以单词统计为例,一张图熟悉RDD当中的五大属性 解构图 RDD弹性 RDD特点 分区 只读 依赖 缓存 checkpoint 基本概念 ...
- spark RDD,DataFrame,DataSet 介绍
弹性分布式数据集(Resilient Distributed Dataset,RDD) RDD是Spark一开始就提供的主要API,从根本上来说,一个RDD就是你的数据的一个不可变的分布式元素集合,在 ...
- 2. RDD(弹性分布式数据集Resilient Distributed dataset)
*以下内容由<Spark快速大数据分析>整理所得. 读书笔记的第二部分是讲RDD.RDD 其实就是分布式的元素集合.在 Spark 中,对数据的所有操作不外乎创建RDD.转化已有RDD以及 ...
- [bigdata] Spark RDD整理
1. RDD是什么RDD:Spark的核心概念是RDD (resilient distributed dataset),指的是一个只读的,可分区的弹性分布式数据集,这个数据集的全部或部分可以缓存在内存 ...
- Spark RDD基本概念与基本用法
1. 什么是RDD RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行计算的集合.RDD具 ...
- RDD, DataFrame or Dataset
总结: 1.RDD是一个Java对象的集合.RDD的优点是更面向对象,代码更容易理解.但在需要在集群中传输数据时需要为每个对象保留数据及结构信息,这会导致数据的冗余,同时这会导致大量的GC. 2.Da ...
- Spark RDD理解-总结
1.spark是什么 快速.通用.可扩展的分布式计算引擎. 2. 弹性分布式数据集RDD RDD(Resilient Distributed Dataset),是Spark中最基本的数据抽象结构,表示 ...
- Spark的核心RDD(Resilient Distributed Datasets弹性分布式数据集)
Spark的核心RDD (Resilient Distributed Datasets弹性分布式数据集) 原文链接:http://www.cnblogs.com/yjd_hycf_space/p/7 ...
- RDD内存迭代原理(Resilient Distributed Datasets)---弹性分布式数据集
Spark的核心RDD Resilient Distributed Datasets(弹性分布式数据集) Spark运行原理与RDD理论 Spark与MapReduce对比,MapReduce的计 ...
随机推荐
- $.ajax()方法详解(转)
以下内容转自:http://www.cnblogs.com/tylerdonet/p/3520862.html 尊重原创,请访问原创文章 jquery中的ajax方法参数总是记不住,这里记录一下. ...
- Java钉钉开发_00_资源帖
1.源码 本系列教程的源码已上传至GitHub: https://github.com/shirayner/DingTalk_Demo 2.官方 官方源码:https://github.com/op ...
- 关于linux 安装 python pymssql模块
需要先安装freetds是一个开源的C程序库,它可以实现在Linux系统下访问操作微软的SQL数据库.可以用在Sybase的db-lib或者ct-lib库,在里面也包含了一个ODBC的库.允许许多应用 ...
- 关于Windows与Linux下32位与64位开发中的数据类型长度的一点汇总
32位与64位的数据类型长度是不一样的,而且windows和linux也有些许区别,下面把64位下的数据长度列表如下(无符号unsigned和有符号的长度一样): linux64 ...
- ACM学习历程—UESTC 1218 Pick The Sticks(动态规划)(2015CCPC D)
题目链接:http://acm.uestc.edu.cn/#/problem/show/1218 题目大意就是求n根木棒能不能放进一个容器里,乍一看像01背包,但是容器的两端可以溢出容器,只要两端的木 ...
- MySQL复制--最快的从库搭建方法(tar包) -转
最快的从库搭建方法0,准备从库第一次数据备份,临时锁所有表开启窗口1 mysql> flush tables with read lock; Query OK, 0 rows affected ...
- DSP/BIOS程序启动顺序
基于TI的DSP芯片的应用程序分为两种:一般应用程序:DSP/BIOS应用程序. 为简化编程,TI提供了一套C的编程接口,它以API和宏的形式封装了TI的所有硬件模块,这套接口统称DSP/BIOS.D ...
- 【转】 Pro Android学习笔记(三八):Fragment(3):基础小例子-续
目录(?)[-] Step 2实现Fragment指定调用类TitleFragment onInflate和onAttach onCreate和onCreateView onActivityCreat ...
- CSS 关于文本 背景 边框整理
文本与字体 1)阴影:text-shadow 格式:text-shadow:5px 5px 3px #FFFFFF分别对应 水平方向 垂直方向 模糊程度 颜色值 代码: <!DOCTYPE ht ...
- 使用swift命令遭遇503错误
使用swift命令遭遇503 Internal Server Error.这个问题可能有很多种原因,这里只描述下我当前遇到的一种情况. 我们实验环境下的swift设有3个zone,有1个proxy n ...