hive原理
什么是Hive
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
Hive架构图
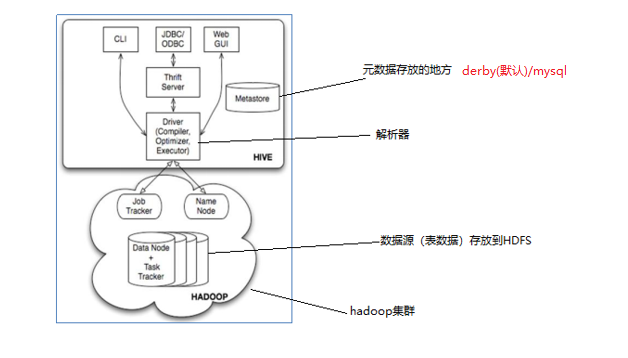
Jobtracker是hadoop1.x中的组件,它的功能相当于: Resourcemanager+AppMaster
TaskTracker 相当于: Nodemanager + yarnchild
Hive的特点
1. 可扩展
Hive可以自由的扩展集群的规模,一般情况下不需要重启服务。
2.延展性
Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
3.容错性
良好的容错性,节点出现问题SQL仍可完成执行。
基本组成
- 用户接口:包括 CLI、JDBC/ODBC、WebGUI。
- 元数据存储:通常是存储在关系数据库如 mysql , derby中。
- 解释器、编译器、优化器、执行器。
各组件的基本功能
- 用户接口主要由三个:CLI、JDBC/ODBC和WebGUI。其中,CLI为shell命令行;JDBC/ODBC是Hive的JAVA实现,与传统数据库JDBC类似;WebGUI是通过浏览器访问Hive。
- 元数据存储:Hive 将元数据存储在数据库中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
- 解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有 MapReduce 调用执行。
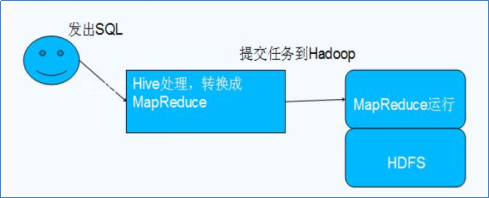
Hive与Hadoop的关系
Hive利用HDFS存储数据,利用MapReduce查询数据
Hive数据类型
- 数据类型
- TINYINT
- SMALLINT
- INT
- BIGINT
- BOOLEAN
- FLOAT
- DOUBLE
- STRING
- BINARY(Hive 0.8.0以上才可用)
- TIMESTAMP(Hive 0.8.0以上才可用)
– 复合类型
- Arrays:ARRAY<data_type>
- Maps:MAP<primitive_type, data_type>
- Structs:STRUCT<col_name: data_type[COMMENT col_comment],……>
- Union:UNIONTYPE<data_type, data_type,……>
hive数据存储
1、Hive中所有的数据都存储在 HDFS 中,没有专门的数据存储格式(可支持Text,SequenceFile,ParquetFile,RCFILE等)
2、只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
3、Hive 中包含以下数据模型:DB、Table,External Table,Partition,Bucket。
- db:在hdfs中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
- table:在hdfs中表现所属db目录下一个文件夹(普通表:删除表后, hdfs上的文件都删了)
- external table:外部表, 与table类似,不过其数据存放位置可以在任意指定路径(External外部表删除后, hdfs上的文件没有删除, 只是把文件删除了)
- partition:在hdfs中表现为table目录下的子目录
- bucket:桶, 在hdfs中表现为同一个表目录下根据hash散列之后的多个文件, 会根据不同的文件把数据放到不同的文件中
hive原理的更多相关文章
- 大数据系列之数据仓库Hive原理
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- Hive原理总结(完整版)
目录 课程大纲(HIVE增强) 3 1. Hive基本概念 4 1.1 Hive简介 4 1.1.1 什么是Hive 4 1.1.2 为什么使用Hive 4 1.1.3 Hive的特点 4 1.2 H ...
- 大数据相关技术原理资料整理(hdfs, spark, hbase, kafka, zookeeper, redis, hive, flink, k8s, OpenTSDB, InfluxDB, yarn)
hdfs: hdfs官方文档 深入理解HDFS的架构和原理 https://blog.csdn.net/kezhong_wxl/article/details/76573901 HDFS原理解析(总体 ...
- HIVE教程
完整PDF下载:<HIVE简明教程> 前言 Hive是对于数据仓库进行管理和分析的工具.但是不要被“数据仓库”这个词所吓倒,数据仓库是很复杂的东西,但是如果你会SQL,就会发现Hive是那 ...
- hive学习
大数据的仓库Hive学习 10期-崔晓光 2016-06-20 大数据 hadoop 10原文链接 我们接着之前学习的大数据来学习.之前说到了NoSql的HBase数据库以及Hadoop中 ...
- Phoenix与Hive学习资料
1.Phoenix二级索引机制 http://www.tuicool.com/articles/FfMz6bq http://itindex.net/detail/50681-phoenix-sql- ...
- 大数据利器Hive
序言:在大数据领域存在一个现象,那就是组件繁多,粗略估计一下轻松超过20种.如果你是初学者,瞬间就会蒙圈,不知道力往哪里使.那么,为什么会出现这种现象呢?在本文的开头笔者就简单的阐述一下这种现象出现的 ...
- Ambari配置Hive,Hive的使用
mysql安装,hive环境的搭建 ambari部署hadoop 博客大牛:董的博客 ambari使用 ambari官方文档 hadoop 2.0 详细配置教程 使用Ambari快速部署Hadoop大 ...
- 大数据系列之数据仓库Hive安装
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
随机推荐
- word中已删除设置是否显示
我们打开别人发过来的文档时经常会出现如下图所示,其实这个不是文档的异常,只是word设置显示了修订版标记,如果我们需要去除这个,只需要在审阅-修订功能下面选择显示最终版即可(测试用的10版,其 ...
- April 5 2017 Week 14 Wednesday
Today is a perfect day to start living your dream. 实现梦想,莫如当下. Miracles may happen every day. If you ...
- leetcode: 树
1. sum-root-to-leaf-numbers Given a binary tree containing digits from0-9only, each root-to-leaf pat ...
- POJ-3126 Prime Path---BFS+素数打表
题目链接: https://vjudge.net/problem/POJ-3126 题目大意: 给两个四位数a,b 每次改变a中的一位而且改动之后的必须是素数,问最少改动几次可以到b?(永远达不到b就 ...
- java常用输出技巧,debug
package control; import javax.swing.JFrame; public class DebugTest { public static void main(String[ ...
- 深入理解MyBatis-Spring中间件(spring/mybatis整合)
转:http://blog.csdn.net/fqz_hacker/article/details/53485833 Mybatis-Spring 1.应用 mybatis是比较常用的数据库中间件,我 ...
- 在TextBox控件中禁用鼠标右键
实现效果: 知识运用: MouseEventArgs类的Button属性 TextBox控件的ContextMenu属性 实现代码: private void textBox1_MouseDo ...
- Hive 配置显示表头和数据库信息
在 conf/hive-site.xml 中添加如下配置 <property> <name>hive.cli.print.header</name> <val ...
- System.TimeDate
本篇将介绍时间类型. msdn官网:点击查看 时间辅助类:点击查看 方法:计算两个时间的时间差(年月日小时分钟),获取时间戳,时间格式转换,获取时间随机码 定义:表示时间上的一刻,通常以日期和当天的 ...
- Data Warehouse 业务系统不入仓表
根据数据仓库的实施经验,凡符合如下特征的表,建议不入仓. ① 备份数据表 此类表是对现有表中某个时点数据的一份拷贝,根据需要进行数据恢复使用.因此,只需取当前表中的数据即可. ② 冗余数据表 同一类数 ...