mycat 分片
1 配置下面两种ER分片,并结合日志分析子表插入过程中的不同
(1).父表按照主键ID分片,子表的分片字段与主表ID关联,配置为ER分片
(2).父表的分片字段为其他字段,子表的分片字段与主表ID关联,配置为ER分片
答:(1)第一种分片:父表按照主键ID分片
表设计:父表student,子表selectcourse
student(id,stu_id);
selectcourse(id,stu_id,cou_id);
在schema.xml中增加父表、子表定义:
<table name="student" primaryKey="ID" dataNode="dn1,dn2,dn3" rule="mod-long">
<childTable name="selectcourse" primaryKey="ID" joinKey="stu_id" parentKey="id" />
</table>
在mysql客户端中执行创建表的语句:
create table student(id bigint not null primary key,stu_id bigint not null);
create table selectcourse(id bigint not null primary key,stu_id bigint not null,cou_id bigint not null);
插入父表记录
insert into student(id,stu_id) values(1,3001);//
insert into student(id,stu_id) values(2,3002);
插入子表记录
insert into selectcourse(id,stu_id,cou_id) values(1,1,1); //同时观察日志
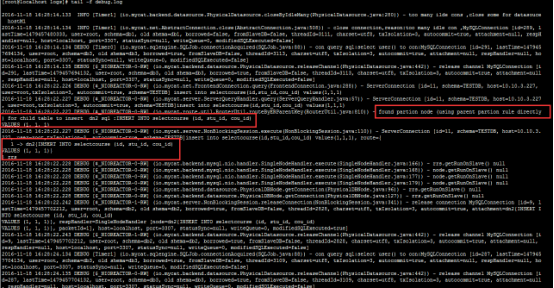
总结:直接使用父表的分片规则(id字段mod算法)来查找节点。
2)第二种分片:父表的分片字段为其他字段
表设计:父表book,子表sail
book(id,book_id);
sail(id,book_id,custo_id);
在rule.xml中增加“mod-long-book”分片方法:分片字段为book_id
<tableRule name="mod-long-book">
<rule>
<columns>book_id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
在schema.xml中增加父表、子表定义:父表用"mod-long-book"方法分片,
<table name="book" primaryKey="ID" dataNode="dn1,dn2,dn3" rule="mod-long-book">
<childTable name="sail" primaryKey="ID" joinKey="book_id" parentKey="id" />
</table>
在mysql客户端中执行创建表的语句:
create table book(id bigint not null primary key,book_id bigint not null);
create table sail(id bigint not null primary key,book_id bigint not null,customer_id bigint not null);
插入父表记录:
insert into book(id,book_id) values(1,3001);
insert into book(id,book_id) values(2,3002);
插入子表记录
insert into sail(id,book_id,customer_id) values(1,2,2001);//同时观察日志
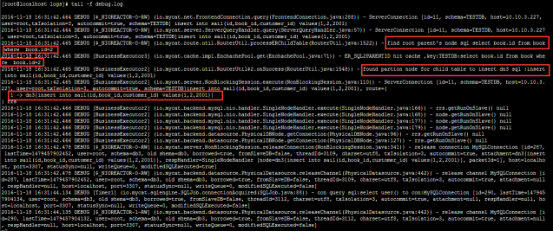
总结:先通过父表的id字段查询分片,再往相应的分片中插入数据。
比第一种方法多了一个“查找分片”的步骤。
2 选则连续分片规则中的2种,对配置和路由过程做完整的分析
(1)自定义数字范围分片:分片方法为“rang-long”
首先,在rule.xml中配置分片方法“price-rang-long”,算法为“rang-long”;

再在schema.xml中配置表信息,包括表名、主键、节点、分片方法等;

然后,在客户端执行创建表的命令(mygoods);

最后,往mygoods表中插入记录;

日志信息:

路由描述:
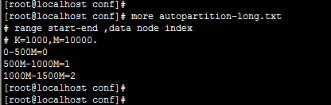
mygoods表依据rang-long算法进行分割,rang-long又依据autopartition-long.txt(如下图所示)文件中的值进行分片(制定数据节点dh),本题中的price为300,
属于0-500M的范围,所以本记录应该路由到第0个节点上(下标从0开始,第0个节点就是dn1)执行,正如上图中所示。
(2)自然月分片:分片方法为“partbymonth”
首先,在rule.xml中配置分片方法“sharding-by-month”,算法为“partbymonth”;
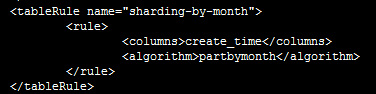
再在schema.xml中配置表信息,包括表名、主键、节点、分片方法等;

然后,在客户端执行创建表的命令(myrecords);

最后,往myrecords表中插入记录;

日志信息:

路由描述:
Myrecords表依据partbymonth算法进行分割,partbymonth的以自然月为依据,每个月一个分片,从2015-01-01开始(如下图所示:rule.xml中partbymonth分片方法),
即2015年1月份数据在第0节点,2015年2月份数据在第1节点,以此类推。本题中的create_time=”2015-03-01”对应的数据应该在第2个节点(下标从0开始,第2个节点
就是dn3)执行,所以,本记录路由到第2个节点上(dn3)执行,正如上图中所示。

3 选择离散分片规则的2种,对配置和路由过程做完整的分析
(1)十进制求模分片:分片方法为“mod-long”
首先,在rule.xml中配置分片方法;

再在schema.xml中配置表信息,包括表名、主键、节点、分片方法等;

然后,在客户端执行创建表的命令(student);
create table student(id bigint not null primary key,stu_id bigint not null);
最后,往student表中插入记录;

日志信息:
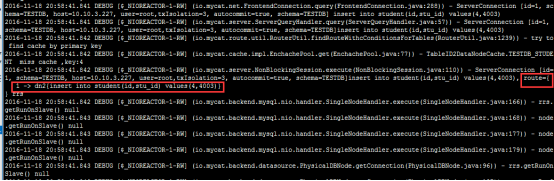
路由描述:
student表依据mod-log算法进行分割,本题中记录值为4除3的模为1,对应的数据应该在第1个节点(下标从0开始,第1个节点就是dn2)上;所以,本记录路由到第1个节点上(dn2)执行,正如上图中所示。
(2)哈希分片:分片方法为“hash-int”
首先,在rule.xml中配置分片方法;
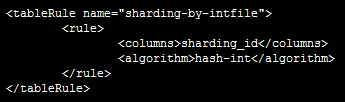
再在schema.xml中配置表信息,包括表名、主键、节点、分片方法等;

然后,在客户端执行创建表的命令(employee);
create table employee (id int not null primary key,name varchar(100),sharding_id int not null);
最后,往myrecords表中插入记录;

日志信息:
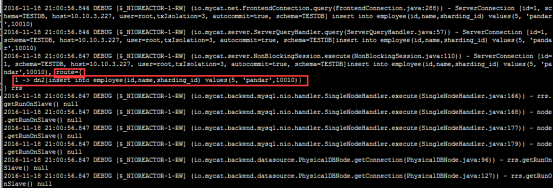
路由描述:
employee 表依据sharding-by-intfile算法进行分割,sharding-by-intfile算法又依据partition-hash-int.txt文件(如下图所示)中的范围进行分片,本题中记录值10010=1,
对应的数据应该在第1个节点(下标从0开始,第1个节点就是dn2)上;所以,本记录路由到第1个节点上(dn2)执行,正如上图中所示。


mycat 分片的更多相关文章
- Mysql系列八:Mycat和Sharding-jdbc的区别、Mycat分片join、Mycat分页中的坑、Mycat注解、Catlet使用
一.Mycat和Sharding-jdbc的区别 1)mycat是一个中间件的第三方应用,sharding-jdbc是一个jar包 2)使用mycat时不需要改代码,而使用sharding-jdbc时 ...
- Mysql系列六:(Mycat分片路由原理、Mycat常用分片规则及对应源码介绍)
一.Mycat分片路由原理 我们先来看下面的一个SQL在Mycat里面是如何执行的: , ); 有3个分片dn1,dn2,dn3, id=5000001这条数据在dn2上,id=10000001这条数 ...
- mycat分片操作
mycat位于应用与数据库的中间层,可以灵活解耦应用与数据库,后端数据库可以位于不同的主机上.在mycat中将表分为两大类:对于数据量小且不需要做数据切片的表,称之为分片表:对于数据量大到单库性能,容 ...
- mycat分片规则之分片枚举(sharding-by-intinfile)
mycat分片规则之分片枚举(sharding-by-intinfile) http://blog.51cto.com/goome/2058959 mycat安装及分片初体验 https://blog ...
- mycat分片及主从(二)
一.mycat分片规则 经过上一篇幅讲解,应该很清楚分片规则配置文件rule.xml位于$MYCAT_HOME/conf目录,它定义了所有拆分表的规则.在使用过程中可以灵活使用不同的分片算法,或者对同 ...
- Mycat 分片规则详解--一致性hash分片
实现方式:基于hash算法的分片中,算法内部是把记录分片到一种叫做"bucket"(hash桶)的内部算法结构中的,然后hash桶与实际的分片节点一一对应,从此实现了分片.路由的功 ...
- Mycat 分片规则详解--数据迁移及节点扩容
使用的是 Mycat 提供的 dataMigrate 脚本进行对数据进行迁移和节点扩容,目前支持的 Mycat 是1.6 版本,由于 Mycat 是由 Java 编写的因此在做数据迁移及节点扩容时需要 ...
- Mycat 分片规则详解--日期范围 hash 分片
实现方式:其思想和范围取模分片一样,由于日期取模会出现数据热点问题,所以先根据日期分组,再根据时间 hash 使得短期数据分布跟均匀. 优点:避免扩容时的数据迁移,可以在一定程度上避免范围分片的热点问 ...
- Mycat 分片规则详解--单月小时分片
实现方式:单月内按照小时拆分,最小粒度是小时,一天最多可以有24个分片,最少1个分片,下个月从头开始循环 优点:使数据按照小时来进行分时存储,颗粒度比日期(天)分片要小,适用于数据采集类存储分片 缺点 ...
- Mycat 分片规则详解--日期(天)分片
实现方式:按照日期来分片 优点:使数据按照日期来进行分时存储 缺点:由于数据是连续的,所以该方案不能有效的利用资源 配置示例: <tableRule name="sharding-by ...
随机推荐
- 自动生成Mapper代码
public class BeanMapperTest { @Test public void build() throws Exception { Class clazz = RiskAccess. ...
- HDU 3466 Proud Merchants 排序 背包
题意:物品有三个属性,价格p,解锁钱数下线q(手中余额>=q才有机会购买该商品),价值v.钱数为m,问购买到物品价值和最大. 思路:首先是个01背包问题,但购买物品受限所以应先排序.考虑相邻两个 ...
- R语言笔记005——计算描述性统计量
数据的分布特征: 分布的集中趋势,反应各数据向其中心值靠拢或聚集的程度(平均数,中位数,四分位数,众数) 分布的离散程度,反应各数据远离其中心值的趋势(极差,四分位差,方差,标准差,离散系数) 分布的 ...
- 【转】nodejs mysql 链接数据库集群
1.建立数据库连接:createConnection(Object)方法 该方法接受一个对象作为参数,该对象有四个常用的属性host,user,password,database.与php中 ...
- HDU 5925 离散化
东北赛的一道二等奖题 当时学长想了一个dfs的解法并且通过了 那时自己也有一个bfs的解法没有拿出来 一直没有机会和时ji间xing来验证对错 昨天和队友谈离散化的时候想到了 于是用当时的思路做了一下 ...
- EXCEL中,怎样查看一个工作簿中有几个工作表?
EXCEL中,怎样查看一个工作簿中有几个工作表 有几个EXCEL文件,每个文件(工作簿)中都有上百个工作表, 怎样可以一次性查看一个簿包含几个表? 目前好像没有直接可以看到有多少张工作表的按钮,这就需 ...
- linux学习-磁盘管理
- js获取当前url的参数
可以用正则表达式获取当前url参数,例如: var t={ getQueryString:function(name){ var reg = new RegExp("(^|&)&qu ...
- 十大监视SQL Server性能的计数器
作为DBA,每个人都会用一系列计数器来监视SQLSERVER的运行环境,使用计数器,既可以衡量当前的数据库的性能,还可以和以前的性能进行对比.我们也可以一直以快速和简单的方法把计数器做了一张图表来 ...
- windows live writer 原始图片大小设置
点击图片,右面对图片参数进行设置,然后点击保存默认设置. 那么以后再插入图片,就不要重新操作了.