mycat 分片
1 配置下面两种ER分片,并结合日志分析子表插入过程中的不同
(1).父表按照主键ID分片,子表的分片字段与主表ID关联,配置为ER分片
(2).父表的分片字段为其他字段,子表的分片字段与主表ID关联,配置为ER分片
答:(1)第一种分片:父表按照主键ID分片
表设计:父表student,子表selectcourse
student(id,stu_id);
selectcourse(id,stu_id,cou_id);
在schema.xml中增加父表、子表定义:
<table name="student" primaryKey="ID" dataNode="dn1,dn2,dn3" rule="mod-long">
<childTable name="selectcourse" primaryKey="ID" joinKey="stu_id" parentKey="id" />
</table>
在mysql客户端中执行创建表的语句:
create table student(id bigint not null primary key,stu_id bigint not null);
create table selectcourse(id bigint not null primary key,stu_id bigint not null,cou_id bigint not null);
插入父表记录
insert into student(id,stu_id) values(1,3001);//
insert into student(id,stu_id) values(2,3002);
插入子表记录
insert into selectcourse(id,stu_id,cou_id) values(1,1,1); //同时观察日志
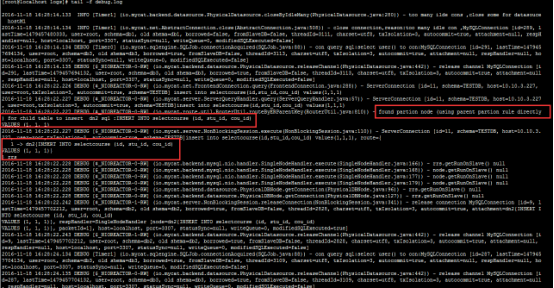
总结:直接使用父表的分片规则(id字段mod算法)来查找节点。
2)第二种分片:父表的分片字段为其他字段
表设计:父表book,子表sail
book(id,book_id);
sail(id,book_id,custo_id);
在rule.xml中增加“mod-long-book”分片方法:分片字段为book_id
<tableRule name="mod-long-book">
<rule>
<columns>book_id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
在schema.xml中增加父表、子表定义:父表用"mod-long-book"方法分片,
<table name="book" primaryKey="ID" dataNode="dn1,dn2,dn3" rule="mod-long-book">
<childTable name="sail" primaryKey="ID" joinKey="book_id" parentKey="id" />
</table>
在mysql客户端中执行创建表的语句:
create table book(id bigint not null primary key,book_id bigint not null);
create table sail(id bigint not null primary key,book_id bigint not null,customer_id bigint not null);
插入父表记录:
insert into book(id,book_id) values(1,3001);
insert into book(id,book_id) values(2,3002);
插入子表记录
insert into sail(id,book_id,customer_id) values(1,2,2001);//同时观察日志
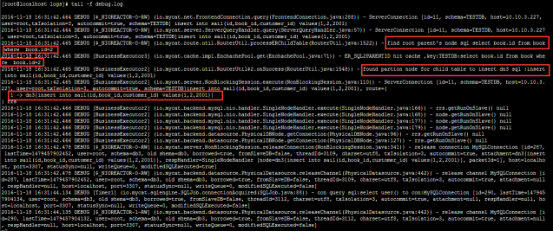
总结:先通过父表的id字段查询分片,再往相应的分片中插入数据。
比第一种方法多了一个“查找分片”的步骤。
2 选则连续分片规则中的2种,对配置和路由过程做完整的分析
(1)自定义数字范围分片:分片方法为“rang-long”
首先,在rule.xml中配置分片方法“price-rang-long”,算法为“rang-long”;

再在schema.xml中配置表信息,包括表名、主键、节点、分片方法等;

然后,在客户端执行创建表的命令(mygoods);

最后,往mygoods表中插入记录;

日志信息:

路由描述:
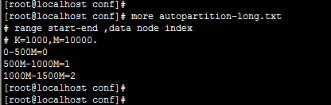
mygoods表依据rang-long算法进行分割,rang-long又依据autopartition-long.txt(如下图所示)文件中的值进行分片(制定数据节点dh),本题中的price为300,
属于0-500M的范围,所以本记录应该路由到第0个节点上(下标从0开始,第0个节点就是dn1)执行,正如上图中所示。
(2)自然月分片:分片方法为“partbymonth”
首先,在rule.xml中配置分片方法“sharding-by-month”,算法为“partbymonth”;
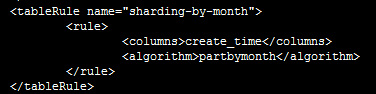
再在schema.xml中配置表信息,包括表名、主键、节点、分片方法等;

然后,在客户端执行创建表的命令(myrecords);

最后,往myrecords表中插入记录;

日志信息:

路由描述:
Myrecords表依据partbymonth算法进行分割,partbymonth的以自然月为依据,每个月一个分片,从2015-01-01开始(如下图所示:rule.xml中partbymonth分片方法),
即2015年1月份数据在第0节点,2015年2月份数据在第1节点,以此类推。本题中的create_time=”2015-03-01”对应的数据应该在第2个节点(下标从0开始,第2个节点
就是dn3)执行,所以,本记录路由到第2个节点上(dn3)执行,正如上图中所示。

3 选择离散分片规则的2种,对配置和路由过程做完整的分析
(1)十进制求模分片:分片方法为“mod-long”
首先,在rule.xml中配置分片方法;

再在schema.xml中配置表信息,包括表名、主键、节点、分片方法等;

然后,在客户端执行创建表的命令(student);
create table student(id bigint not null primary key,stu_id bigint not null);
最后,往student表中插入记录;

日志信息:
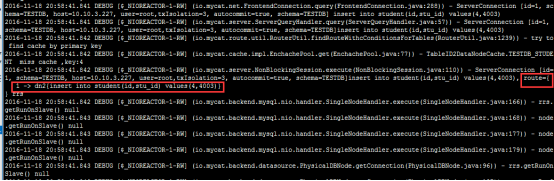
路由描述:
student表依据mod-log算法进行分割,本题中记录值为4除3的模为1,对应的数据应该在第1个节点(下标从0开始,第1个节点就是dn2)上;所以,本记录路由到第1个节点上(dn2)执行,正如上图中所示。
(2)哈希分片:分片方法为“hash-int”
首先,在rule.xml中配置分片方法;
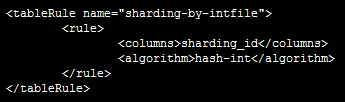
再在schema.xml中配置表信息,包括表名、主键、节点、分片方法等;

然后,在客户端执行创建表的命令(employee);
create table employee (id int not null primary key,name varchar(100),sharding_id int not null);
最后,往myrecords表中插入记录;

日志信息:
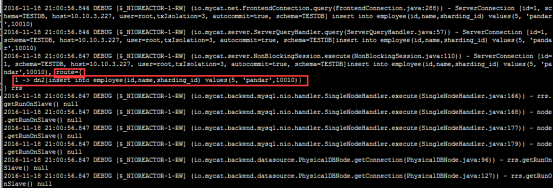
路由描述:
employee 表依据sharding-by-intfile算法进行分割,sharding-by-intfile算法又依据partition-hash-int.txt文件(如下图所示)中的范围进行分片,本题中记录值10010=1,
对应的数据应该在第1个节点(下标从0开始,第1个节点就是dn2)上;所以,本记录路由到第1个节点上(dn2)执行,正如上图中所示。


mycat 分片的更多相关文章
- Mysql系列八:Mycat和Sharding-jdbc的区别、Mycat分片join、Mycat分页中的坑、Mycat注解、Catlet使用
一.Mycat和Sharding-jdbc的区别 1)mycat是一个中间件的第三方应用,sharding-jdbc是一个jar包 2)使用mycat时不需要改代码,而使用sharding-jdbc时 ...
- Mysql系列六:(Mycat分片路由原理、Mycat常用分片规则及对应源码介绍)
一.Mycat分片路由原理 我们先来看下面的一个SQL在Mycat里面是如何执行的: , ); 有3个分片dn1,dn2,dn3, id=5000001这条数据在dn2上,id=10000001这条数 ...
- mycat分片操作
mycat位于应用与数据库的中间层,可以灵活解耦应用与数据库,后端数据库可以位于不同的主机上.在mycat中将表分为两大类:对于数据量小且不需要做数据切片的表,称之为分片表:对于数据量大到单库性能,容 ...
- mycat分片规则之分片枚举(sharding-by-intinfile)
mycat分片规则之分片枚举(sharding-by-intinfile) http://blog.51cto.com/goome/2058959 mycat安装及分片初体验 https://blog ...
- mycat分片及主从(二)
一.mycat分片规则 经过上一篇幅讲解,应该很清楚分片规则配置文件rule.xml位于$MYCAT_HOME/conf目录,它定义了所有拆分表的规则.在使用过程中可以灵活使用不同的分片算法,或者对同 ...
- Mycat 分片规则详解--一致性hash分片
实现方式:基于hash算法的分片中,算法内部是把记录分片到一种叫做"bucket"(hash桶)的内部算法结构中的,然后hash桶与实际的分片节点一一对应,从此实现了分片.路由的功 ...
- Mycat 分片规则详解--数据迁移及节点扩容
使用的是 Mycat 提供的 dataMigrate 脚本进行对数据进行迁移和节点扩容,目前支持的 Mycat 是1.6 版本,由于 Mycat 是由 Java 编写的因此在做数据迁移及节点扩容时需要 ...
- Mycat 分片规则详解--日期范围 hash 分片
实现方式:其思想和范围取模分片一样,由于日期取模会出现数据热点问题,所以先根据日期分组,再根据时间 hash 使得短期数据分布跟均匀. 优点:避免扩容时的数据迁移,可以在一定程度上避免范围分片的热点问 ...
- Mycat 分片规则详解--单月小时分片
实现方式:单月内按照小时拆分,最小粒度是小时,一天最多可以有24个分片,最少1个分片,下个月从头开始循环 优点:使数据按照小时来进行分时存储,颗粒度比日期(天)分片要小,适用于数据采集类存储分片 缺点 ...
- Mycat 分片规则详解--日期(天)分片
实现方式:按照日期来分片 优点:使数据按照日期来进行分时存储 缺点:由于数据是连续的,所以该方案不能有效的利用资源 配置示例: <tableRule name="sharding-by ...
随机推荐
- Codeforces Round #275 (Div. 2) D
题意 : 一个数组 给出m个限制条件 l r z 代表从l 一直 & 到 r 为 z 问能否构造出这种数组 如果可以 构造出来 因为 n m 都是1e5 而l r 可能输入进去就超时了 所以 ...
- JavaWeb -- 四个域对比 request,servletContext, Session, pageContext
requsest: 程序产生数据,用完了就没有用了, 用request, 作用范围:一个请求范围. Session: 程序产生数据,用完了 等一下还要使用, 用Session, 作用范围: 一个会话范 ...
- Spring data jpa 实现简单动态查询的通用Specification方法
本篇前提: SpringBoot中使用Spring Data Jpa 实现简单的动态查询的两种方法 这篇文章中的第二种方法 实现Specification 这块的方法 只适用于一个对象针对某一个固定字 ...
- ZigzagConvert
public class ZigzagConvert { public static String convert(String s, int nRows) { int len = s.length( ...
- Python之异常总结
一.异常错误 a.语法错误 错误一: if 错误二: def text: pass 错误三: print(sjds b.逻辑错误 #用户输入不完整(比如输入为空)或者输入非法(输入不是数字) num= ...
- 使用 Spring Boot 快速构建 Spring 框架应用
Spring 框架对于很多 Java 开发人员来说都不陌生.自从 2002 年发布以来,Spring 框架已经成为企业应用开发领域非常流行的基础框架.有大量的企业应用基于 Spring 框架来开发.S ...
- Ant入门
一.Ant介绍 Ant是Java的生成工具,是Apache的核心项目:直接在apache官网下载即可: Ant类似于Unix中的Make工具,都是用来编译.生成: Ant是跨平台的,而Make不能: ...
- 云服务器pip下载老失败怎么办?
pip install -i https://pypi.douban.com/simple django==1.9
- RGB(16进制)_转_TColor
ZC:内存中 COLORREF就是一个DWORD(从定义"COLORREF = DWORD;"就可以看出来),但是 具体的byte R/G/B 的位置是怎么方式的? ZC:Wind ...
- Spring Boot入门——集成Mybatis
步骤: 1.新建maven项目 2.在pom.xml文件中引入相关依赖 <!-- mysql依赖 --> <dependency> <groupId>mysql&l ...