最经典的TCP性能问题
问题描述
某个PHP服务通过Nginx将后面的tair封装了一下,让其他应用可以通过http协议访问Nginx来get、set 操作tair
上线后测试一切正常,每次操作几毫秒,但是有一次有个应用的value是300K,这个时候set一次需要300毫秒以上。 在没有任何并发压力单线程单次操作也需要这么久,这个延迟是没有道理和无法接受的。
问题的原因
是因为TCP协议为了做一些带宽利用率、性能方面的优化,而做了一些特殊处理。比如Delay Ack和Nagle算法。
这个原因对大家理解TCP基本的概念后能在实战中了解一些TCP其它方面的性能和影响。
什么是delay ack
由我前面的TCP介绍文章大家都知道,TCP是可靠传输,可靠的核心是收到包后回复一个ack来告诉对方收到了。
来看一个例子:
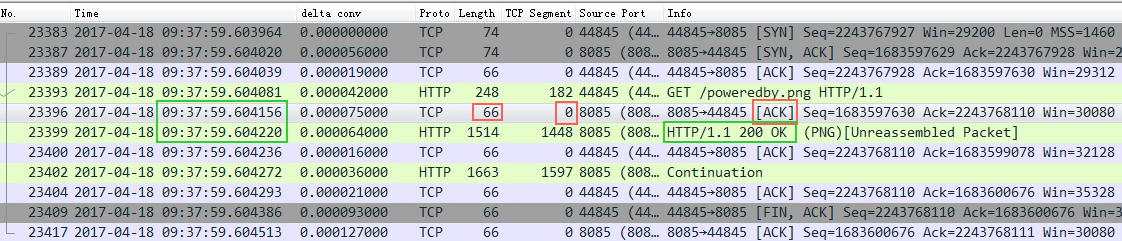
截图中的Nignx(8085端口),收到了一个http request请求,然后立即回复了一个ack包给client,接着又回复了一个http response 给client。大家注意回复的ack包长度66,实际内容长度为0,ack信息放在TCP包头里面,也就是这里发了一个66字节的空包给客户端来告诉客户端我收到你的请求了。
这里没毛病,逻辑很对,符合TCP的核心可靠传输的意义。但是带来的一个问题是:带宽效率不高。那能不能优化呢?
这里的优化就是delay ack。
delay ack是指收到包后不立即ack,而是等一小会(比如40毫秒)看看,如果这40毫秒以内正好有一个包(比如上面的http response)发给client,那么我这个ack包就跟着发过去(顺风车,http reponse包不需要增加任何大小),这样节省了资源。 当然如果超过这个时间还没有包发给client(比如nginx处理需要40毫秒以上),那么这个ack也要发给client了(即使为空,要不client以为丢包了,又要重发http request,划不来)。
假如这个时候ack包还在等待延迟发送的时候,又收到了client的一个包,那么这个时候server有两个ack包要回复,那么os会把这两个ack包合起来立即回复一个ack包给client,告诉client前两个包都收到了。
也就是delay ack开启的情况下:ack包有顺风车就搭;如果凑两个ack包自己包个车也立即发车;再如果等了40毫秒以上也没顺风车,那么自己打个车也发车。
截图中Nginx没有开delay ack,所以你看红框中的ack是完全可以跟着绿框(http response)一起发给client的,但是没有,红框的ack立即打车跑了
什么是Nagle算法
下面的伪代码就是Nagle算法的基本逻辑,摘自wiki:
if there is new data to send
if the window size >= MSS and available data is >= MSS
send complete MSS segment now
else
if there is unconfirmed data still in the pipe
enqueue data in the buffer until an acknowledge is received
else
send data immediately
end if
end if
end if
这段代码的意思是如果要发送的数据大于 MSS的话,立即发送。
否则:
看看前面发出去的包是不是还有没有ack的,如果有没有ack的那么我这个小包不急着发送,等前面的ack回来再发送
我总结下Nagle算法逻辑就是:如果发送的包很小(不足MSS),又有包发给了对方对方还没回复说收到了,那我也不急着发,等前面的包回复收到了再发。这样可以优化带宽利用率(早些年带宽资源还是很宝贵的),Nagle算法也是用来优化改进tcp传输效率的。
如果client启用Nagle,并且server端启用了delay ack会有什么后果呢?
假如client要发送一个http请求给server,这个请求有1600个bytes,握手的MSS是1460,那么这1600个bytes就会分成2个TCP包,第一个包1460,剩下的140bytes放在第二个包。第一个包发出去后,server收到第一个包,因为delay ack所以没有回复ack,同时因为server没有收全这个HTTP请求,所以也没法回复HTTP response(server等一个完整的HTTP请求,或者40毫秒的delay时间)。client这边开启了Nagle算法(默认开启)第二个包比较小(140<MSS),第一个包的ack还没有回来,那么第二个包就不发了,等!互相等!一直到Delay Ack的Delay时间到了!
这就是悲剧的核心原因。
再来看一个经典例子和数据分析
这个案例来自:http://www.stuartcheshire.org/papers/nagledelayedack/
案例核心奇怪的问题是,如果传输的数据是 99,900 bytes,速度5.2M/秒;
如果传输的数据是 100,000 bytes 速度2.7M/秒,多了10个bytes,不至于传输速度差这么多。
原因就是:
99,900 bytes = 68 full-sized 1448-byte packets, plus 1436 bytes extra
100,000 bytes = 69 full-sized 1448-byte packets, plus 88 bytes extra
99,900 bytes:
68个整包会立即发送(都是整包,不受Nagle算法的影响),因为68是偶数,对方收到最后两个包后立即回复ack(delay ack凑够两个也立即ack),那么剩下的1436也很快发出去(根据Nagle算法,没有没ack的包了,立即发)
100,000 bytes:
前面68个整包很快发出去也收到ack回复了,然后发了第69个整包,剩下88bytes(不够一个整包)根据Nagle算法要等一等,server收到第69个ack后,因为delay ack不回复(手里只攒下一个没有回复的包),所以client、server两边等在等,一直等到server的delay ack超时了。
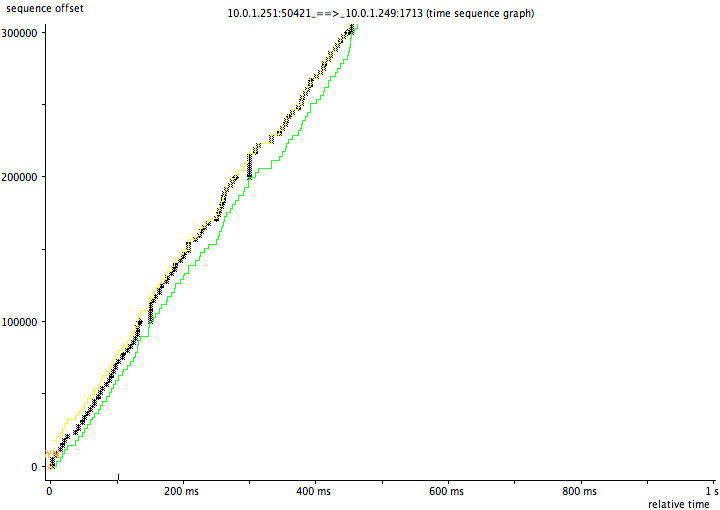
挺奇怪和挺有意思吧,作者还给出了传输数据的图表:

这是有问题的传输图,明显有个平台层,这个平台层就是两边在互相等,整个速度肯定就上不去。
如果传输的都是99,900,那么整个图形就很平整:
回到前面的问题
服务写好后,开始测试都没有问题,rt很正常(一般测试的都是小对象),没有触发这个问题。后来碰到一个300K的rt就到几百毫秒了,就是因为这个原因。
另外有些http post会故意把包头和包内容分成两个包,再加一个Expect参数之类的,更容易触发这个问题。
这是修改后的C代码:
struct curl_slist *list = NULL;
//合并post包
list = curl_slist_append(list, "Expect:");
CURLcode code(CURLE_FAILED_INIT);
if (CURLE_OK == (code = curl_easy_setopt(curl, CURLOPT_URL, oss.str().c_str())) &&
CURLE_OK == (code = curl_easy_setopt(curl, CURLOPT_TIMEOUT_MS, timeout)) &&
CURLE_OK == (code = curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, &write_callback)) &&
CURLE_OK == (code = curl_easy_setopt(curl, CURLOPT_VERBOSE, 1L)) &&
CURLE_OK == (code = curl_easy_setopt(curl, CURLOPT_POST, 1L)) &&
CURLE_OK == (code = curl_easy_setopt(curl, CURLOPT_POSTFIELDSIZE, pooh.sizeleft)) &&
CURLE_OK == (code = curl_easy_setopt(curl, CURLOPT_READFUNCTION, read_callback)) &&
CURLE_OK == (code = curl_easy_setopt(curl, CURLOPT_READDATA, &pooh)) &&
CURLE_OK == (code = curl_easy_setopt(curl, CURLOPT_NOSIGNAL, 1L)) && //1000 ms curl bug
CURLE_OK == (code = curl_easy_setopt(curl, CURLOPT_HTTPHEADER, list))
) {
//这里如果是小包就不开delay ack,实际不科学
if (request.size() < 1024) {
code = curl_easy_setopt(curl, CURLOPT_TCP_NODELAY, 1L);
} else {
code = curl_easy_setopt(curl, CURLOPT_TCP_NODELAY, 0L);
}
if(CURLE_OK == code) {
code = curl_easy_perform(curl);
}
上面中文注释的部分是后来的改进,然后经过测试同一个300K的对象也能在几毫米以内完成get、set了。
尤其是在Post请求将HTTP Header和Body内容分成两个包后,容易出现这种延迟问题。
总结
这个问题确实经典,非常隐晦一般不容易碰到,碰到一次决不放过她。文中所有client、server的概念都是相对的,client也有delay ack的问题。 Nagle算法一般默认开启的
最经典的TCP性能问题的更多相关文章
- 理论经典:TCP协议的3次握手与4次挥手过程详解
1.前言 尽管TCP和UDP都使用相同的网络层(IP),TCP却向应用层提供与UDP完全不同的服务.TCP提供一种面向连接的.可靠的字节流服务. 面向连接意味着两个使用TCP的应用(通常是一个客户和一 ...
- [转载] 高流量大并发Linux TCP 性能调优
原文: http://cenwj.com/2015/2/25/19 本文参考文章为: 优化Linux下的内核TCP参数来提高服务器负载能力 Linux Tuning 本文所面对的情况为: 高并发数 高 ...
- 对TCP性能的考虑
#xiaodeng #对TCP性能的考虑 #HTTP权威指南 86 #对TCP性能的考虑 #HTTP紧挨着TCP,位于其上层.所以HTTP事务的性能很大程度上取决于底层tcp通道的性能. #4.2.1 ...
- [心平气和读经典]The TCP/IP Guide(003)
The TCP/IP Guide [Page 43, 44] Scope of The TCP/IP Guide | 本书的讨论范围 The first step to dealing with a ...
- 《HTTP权威指南》之HTTP连接管理及对TCP性能的考虑
在上一篇博客中(<HTTP权威指南>之HTTP相关概念详解)我们简单对HTTP相关的基本概念做了一些简单的了解,但未对HTTP连接管理的内容做一些详细的介绍.本篇博客我们就一起来看一下HT ...
- (经典)tcp粘包分析
转载自csdn:http://blog.csdn.net/zhangxinrun/article/details/6721495 这两天看csdn有一些关于socket粘包,socket缓冲区设置的问 ...
- linux下改动内核參数进行Tcp性能调优 -- 高并发
前言: Tcp/ip协议对网络编程的重要性,进行过网络开发的人员都知道,我们所编写的网络程序除了硬件,结构等限制,通过改动Tcp/ip内核參数也能得到非常大的性能提升, 以下就列举一些Tcp/ip内核 ...
- 第七篇:几个经典的TCP通信函数
前言 在TCP通信中要使用到几个非常经典的函数,本文将对这几个函数进行一个简短的使用说明. socket()函数 函数作用:创建一个网际字节流套接字 包含头文件:sys/socket.h ( 后面几个 ...
- 几个经典的TCP通信函数
前言 在TCP通信中要使用到几个非常经典的函数( 点这里参考一个关于它们作用的形象比方 ),本文将对这几个函数进行一个简短的使用说明. socket函数 函数作用:创建一个网际字节流套接字 包含头文件 ...
- 【转】TCP性能优化之避免慢启动
TCP协议中有个慢启动,在<TCP/IP详解卷一>中占据的篇幅很小,但是这个东西,在某些业务场景下,对性能的影响非常大. 什么是慢启动 最初的TCP的实现方式是,在连接建立成功后便会向网络 ...
随机推荐
- HTTPD 搭建正向代理 使无网络访问权限的服务器能够访问互联网服务的快捷办法
背景 公司有保密要求比较高,数据安全要求比较高的企业客户,要求核心业务服务器部允许直接访问互联网,但是因为我们有一些OCR识别以及发票查验等的场景需要连接云端的服务才可以正常使用, 所以这里面就存在安 ...
- 浅谈基于Web的跨平台桌面应用开发
作者:京东物流 王泽知 近些年来,跨平台跨端一直是比较热门的话题,Write once, run anywhere,一直是我们开发者所期望的,跨平台方案的优势十分明显,对于开发者而言,可以做到一次开发 ...
- Docker容器基础入门认知-Namespce
在使用 docker 之前我一般都认为容器的技术应该和虚拟机应该差不多,和虚拟机的技术类似,但是事实上容器和虚拟机根本不是一回事. 虚拟机是将虚拟硬件.内核(即操作系统)以及用户空间打包在新虚拟机当中 ...
- Harbor系统文章01---Linux安装Harbor
1.切换到指定目录下载harbor安装包 wget https://ghproxy.com/https://github.com/goharbor/harbor/releases/download/v ...
- MySQL 列操作记录
在 MySQL 中,你可以使用多种命令和语句来执行列操作,包括添加.修改.删除列等.以下是一些与列操作相关的常用 MySQL 命令和语句: 1. 添加列: 添加新列到表格中: ALTER TABLE ...
- SqlSugar子查询
1.基础教程 1.1 API目录 *****只查一列***** //First: SqlFunc.Subqueryable<School>().Where(s => s.Id == ...
- word论文常用格式设定技巧【公式对齐、制表符公式编号等】
1.公式对齐 改动前: 改动后结果: 2.段落行距要求 对于文字可以设定为1.5倍行距 对于公式 5号字体对应1.5倍行距大概在23.4磅,因此可以根据需求适当调整大小. 3.公式标号---使用制表符 ...
- mybatis批量插入支持默认值和自定义id生成策略的免写sql插件
最近做项目时用了免写sql的插件但是发现批量操作不满足现有需求.所以,在原有基础之上扩展了批量的操作支持[支持插入默认值和自定义id生成策略].使用方法如下: 一:在pom文件中引入jar配置 < ...
- 高精度模板 大数减大数 可变数组vector实现
vector<int> Sub(vector<int>& A, vector<int>& B)//这里默认长数减去短数 { vector<in ...
- 洛谷P2241 统计方形 ,棋盘问题升级板,给出格子坐标中矩形以及正方形的计算方法
在做这道题之前我们先了解一下棋盘问题 棋盘问题 (qq.com) 对于棋盘问题,我们可以得出对于一个n*n的正方形方格阵如何求其包含的正方形个数 也就是数每个正方形的中间点,然后将其点排列 ...