端路由原理及react-router的常用组件
在react中,通常都是使用单页面应用(SPA),即整个页面只有一个html,然后通过不同的url地址进行组件的匹配和切换。
我们看到的url地址可能会有两种形式,一种是 localhost:3000/home,一种是 localhost:3000/#/home,两种地址的区别在于有无#,有#的是根据hash来进行匹配,即url中的锚点,本质上是通过location.hash来改变href,hash后的内容是不会发送给服务器的,没有#是通过html5的history来进行跳转,两者跳转后都不会进行刷新。
以下路由是美团和网易云音乐的,可以看到他们的路由地址的分别是基于hash和history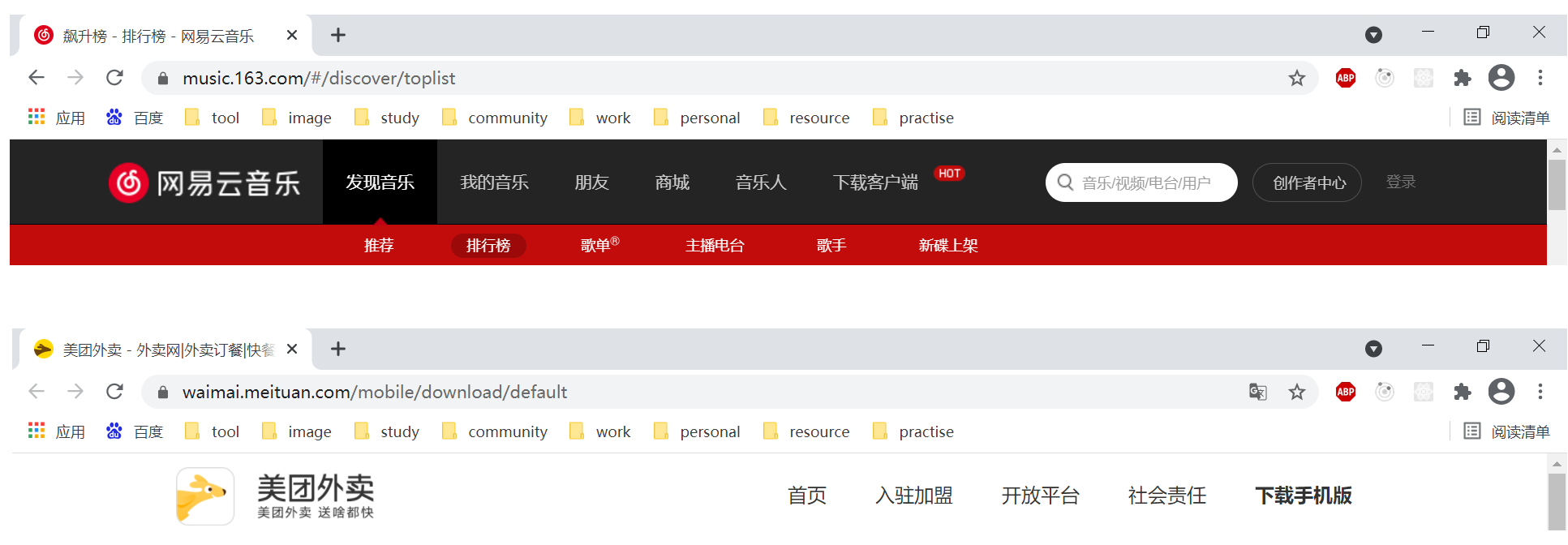
具体来说,通过#来区分路由的实现原理是监听hash的变化,这里监听的方式是使用hashchange 事件,当url地址发生了变化时,通过匹配当前url的地址来进行展示,代码如下所示
<body>
<div>
<a href="#/home">首页</a>
<a href="#/about">关于</a>
</div>
<div id="content"></div> <script>
window.addEventListener('hashchange',()=>{
const content = document.getElementById('content')
switch(location.hash){
case '#/home':
content.innerHTML = '首页'
break
case '#/about':
content.innerHTML = '关于'
break
default:
content.innerHTML = ''
}
})
</script>
</body>
通过html5的history来实现跳转无刷新,就需要阻止a标签的默认行为,再通过history的pushState这一方法实现url地址的替换,同样是监听url地址的变化,这里使用popState方法,当url地址发生了变化之后,展示对应的内容。
<body>
<div>
<div>
<a href="/home">首页</a>
<a href="/about">关于</a>
</div>
<div id="content">
</div>
</body> <script>
const content = document.getElementById('content')
const aEles = document.getElementsByTagName('a') for (let el of aEles) {
el.addEventListener('click', (event) => {
event.preventDefault()
const href = el.getAttribute("href")
history.pushState({}, '', href)
urlchange()
})
} window.addEventListener('popstate', () => {
urlchange()
}) function urlchange() {
switch (location.pathname) {
case '/home':
content.innerHTML = '首页'
break
case '/about':
content.innerHTML = '关于'
break
default:
content.innerHTML = ''
}
}
</script>
以上的锚点和history分别对应了react-router中的HashRouter和BrowserRouter,在react-router中,想要使用路由组件必须在最外层包裹一层HashRouter或者BrowserRouter,来选择想要使用的路由类型,然后才能使用react-router提供的其它组件,react-route中用于web端的库为react-router-dom,以下所有的组件都是从react-router-dom中导出。
下面来说说react-router的常用组件
1、<Link>和<NavLink>,这两个标签都是由a标签的封装,通过to属性指定跳转的链接地址,<NavLink>比<Link>多的是可以指定选中的样式和类名,格式如
<Link to="/about">关于</Link>
通过<Link>标签,点击之后就可以跳转到指定的地址,此时即使外层包裹的是HashRouter,也不需要自己加上#,react-router会帮我们在url上加上#

2、当使用<Link>定义了跳转的url地址后,此时需要指定匹配跳转该url地址时需要显示的内容,此时使用的是<Route>,通过path属性指定url地址,component属性指定渲染的组件,格式如
<Route path="/about" component={About} />
加上了之后, /about这个地址显示的就是About这个组件里的内容。<Route>进行的是模糊匹配,一个url路径可能可以匹配多个Route,如果需要严格匹配的话,可以增加一个属性 exact,适合没有二级路由的时候开启。
3、在有很多的Route的情况下,即使在第一个Route匹配到合适的之后,仍然会继续向下匹配,直到最后一个,所以在所有的<Route>外包裹一个<Switch>标签可以让它进行唯一的匹配,匹配到合适的之后就不继续匹配了。
4、当所有的<Route>都无法匹配到url上的地址时,可以定义 <Redirect>组件直接重定向到一个页面,通过to来指定路由地址,这个组件要放置到<Route>的最后面,因为它和<Link>不同,<Link>是点击了之后才会跳转对应的地址,而<Redirect>会直接执行并跳转
<Redirect to="/about"/>
5、通过路由来匹配的组件称为路由组件,<Route path="/about" component={About} />,这里的About就是路由组件,和其它的组件是不一样的,路由组件的props里有一些数据,其中包括三大属性,history、location和match,history可以自定义页面的跳转,location用来获取url地址相关的信息,match可以用作动态路由的匹配。
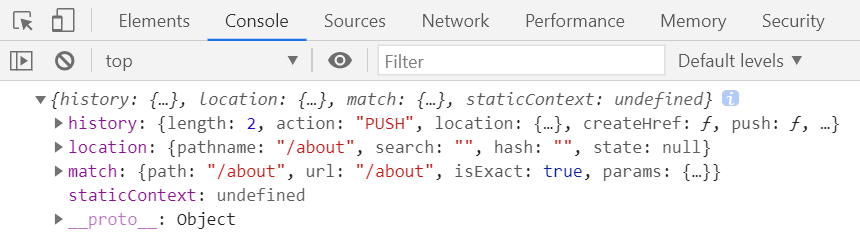
但一般的组件是没有这些props属性的,如果一般的组件也需要这样一些属性的话,可以通过一个高阶组件 withRouter。如
class myCom extends PureComponent { }
export default withRouter(myCom)
再来说说路由传参
有时候,我们希望在链接上带一个id值或者两个页面之间跳转的时候传递一些参数,这时候有三种路由传参方式
1、params传参
<NavLink to="/detail/1">商品详情</NavLink>
<Route path="/detail/:id" component={Detail}/> // 如果是自行定义跳转的地址可以通过 this.props.history.push("/detail/1")
此时的id就是动态的,可以在id这个位置传递任意的数值或者字符串,然后通过props里的match对象中的params获取动态匹配的内容
2、search传参
<NavLink to="/detail?id=1">商品详情</NavLink>
<Route path="/detail" component={Detail}/> // 如果是自行定义跳转的地址可以通过 this.props.history.push("/detail?id=1")
此时相当于在url上添加一个问号进行拼接,需要把地址拼成一种键值对的形式,通过 props里的location对象中的search属性获取从问号开始的匹配内容,这一种路由的匹配方式需要自行解析字符串
3、state传参
<NavLink to={ pathname: "/detail", state: { id: 1} }>商品详情</NavLink>
<Route path="/detail" component={Detail}/>
// 如果是自行定义跳转的地址可以通过 this.props.history.push("/detail", { id: 1})
这样的传递参数方式通过props里的location对象中的state属性来获取传递的值,这种方式的可以直接以对象的形式传递,并且可传递的数据更多,这些参数不会显示在url上
用一个小的组合案例展示以上内容
import React, { PureComponent } from 'react'
import { NavLink, Route, Switch, withRouter, Redirect } from "react-router-dom"
import Home from "./pages/Home"
import About from "./pages/About"
import Detail from "./pages/Detail"
import Product from './pages/Product'
class App extends PureComponent {
jumpToProduct(){
this.props.history.push('/product')
}
render() {
return (
<div>
<NavLink exact to="/">首页</NavLink>
<NavLink to="/about">关于</NavLink>
<NavLink to="/detail/1">详情</NavLink>
<button onClick={e=>this.jumpToProduct()}>商品</button>
<Switch>
<Route exact path="/" component={Home} />
<Route path="/about" component={About} />
<Route path="/detail/:id" component={Detail} />
<Route path="/product" component={Product}/>
<Redirect to="/"/>
</Switch>
</div>
);
}
}
export default withRouter(App)
端路由原理及react-router的常用组件的更多相关文章
- React Native之常用组件(View)
一. JSX和组件的概念 React的核心机制之一就是虚拟DOM:可以在内存中创建的虚拟DOM元素.React利用虚拟DOM来减少对实际DOM的操作从而提升性能.传统的创建方式是: 但这样的代码可读性 ...
- 从 React Router 谈谈路由的那些事
React Router 是专为 React 设计的路由解决方案,在使用 React 来开发 SPA (单页应用)项目时,都会需要路由功能,而 React Router 应该是目前使用率最高的. Re ...
- React躬行记(13)——React Router
在网络工程中,路由能保证信息从源地址传输到正确地目的地址,避免在互联网中迷失方向.而前端应用中的路由,其功能与之类似,也是保证信息的准确性,只不过来源变成URL,目的地变成HTML页面. 在传统的前端 ...
- React初识整理(四)--React Router(路由)
官网:https://reacttraining.com/react-router 后端路由:主要做路径和方法的匹配,从而从后台获取相应的数据 前端路由:用于路径和组件的匹配,从而实现组件的切换. 如 ...
- react router 4.0以上的路由应用
thead>tr>th{padding:8px;line-height:1.4285714;border-top:1px solid #ddd}.table>thead>tr& ...
- Mysql系列六:(Mycat分片路由原理、Mycat常用分片规则及对应源码介绍)
一.Mycat分片路由原理 我们先来看下面的一个SQL在Mycat里面是如何执行的: , ); 有3个分片dn1,dn2,dn3, id=5000001这条数据在dn2上,id=10000001这条数 ...
- react router @4 和 vue路由 详解(七)react路由守卫
完整版:https://www.cnblogs.com/yangyangxxb/p/10066650.html 12.react路由守卫? a.在之前的版本中,React Router 也提供了类似的 ...
- react router @4 和 vue路由 详解(全)
react router @4 和 vue路由 本文大纲: 1.vue路由基础和使用 2.react-router @4用法 3.什么是包容性路由?什么是排他性路由? 4.react路由有两个重要的属 ...
- React Router 4.0 实现路由守卫
在使用 Vue 或者 Angular 的时候,框架提供了路由守卫功能,用来在进入某个路有前进行一些校验工作,如果校验失败,就跳转到 404 或者登陆页面,比如 Vue 中的 beforeEnter 函 ...
- < react router>: (路由)
< react router> (路由): 思维导图: Atrial 文件夹下的index.js 文件内容: import React, { Component } from 'rea ...
随机推荐
- latex-作业模板(自用,因为记不住语法55)
\documentclass[12pt, a4paper, oneside]{ctexart} \usepackage{amsmath, amsthm, amssymb, bm, graphicx, ...
- python库Munch的使用记录
开头 日常操作字典发现发现并不是很便利,特别是需要用很多 get('xxx','-') 的使用,就觉得很烦,偶然看到Kuls大佬公众号发布的一篇技术文有对 python munch库的使用, 使得字典 ...
- 2021-08-30:给定两个字符串str1和str2,在str1中寻找一个最短子串,能包含str2的所有字符,字符顺序无所谓,str1的这个最短子串也可以包含多余的字符。返回这个最短包含子串。
2021-08-30:给定两个字符串str1和str2,在str1中寻找一个最短子串,能包含str2的所有字符,字符顺序无所谓,str1的这个最短子串也可以包含多余的字符.返回这个最短包含子串. 福大 ...
- pupstudy的使用
打开环境 点击管理--打开根目录 把靶场放在www文件夹里 网页打开127.0.0.1/靶场文件名即可
- ChatGPT在线体验原理课-概览:ChatGPT 与自然语言处理
# 概览:ChatGPT 与自然语言处理 本文将介绍 ChatGPT 与自然语言处理的相关知识. ## ChatGPT 与图灵测试 图灵测试是人工智能领域的一个经典问题,它旨在检验计算机是否能够表现出 ...
- [MAUI]写一个跨平台富文本编辑器
@ 目录 原理 创建编辑器 定义 实现复合样式 选择范围 字号 字体颜色与背景色 字体下划线 字体加粗与斜体 序列化和反序列化 跨平台实现 集成至编辑器 创建控件 使用控件 最终效果 已知问题 项目地 ...
- 搭建私人GPT及域名配置
前几天在掘金看到一个搭建私人ChatGPT的教程,看起来并不难. 我也有OpenAI的API Key,然后前阵子我看到我的账号余额还有很多,我的api key其实就一个机器人在用,没用多少. 还有,就 ...
- 在命令行按下tab键之后, 发生了生么?
1. 引言 2. complete命令 3. 自定义补全列表 4. 动态补全列表 5. compgen命令 6. 别名的自动补全 7. 补全规则永久生效 8. 自动加载 9. 参考 1. 引言 当我们 ...
- 迟来的秋招面经,17家公司,Java岗位
一位朋友秋招面试了17家公司(都是中小公司或者银行),Java 后端岗.下面是他的个人情况.求职经验已经这17家公司的面经. 个人情况和求职经验 其实现在是挺后悔大学没有好好的学习的,因为基本上都会提 ...
- 自然语言处理 Paddle NLP - 文本翻译技术及应用-理论
什么是机器翻译 机器翻译质量的自动评价 从统计机器翻译到神经网络机器翻译 多语言/多领域/多模态的翻译应用 神经网络机器翻译面临的挑战 视频:https://aistudio.baidu.com/ai ...