CPU缓存伪共享
CPU缓存什么东西?当然这个问题很多人有可能觉得比较傻,CPU缓存什么,肯定是缓存数据(代码)啊,要不然还能缓存啥,这个确实没问题,但是CPU到底缓存什么样的数据呢?因为对CPU来说,无论是指令,还是数据,都是数据,他如果要缓存,缓存的单位是啥?要缓存的内容是啥呢?
接下来咱们一点点解析这部分的内容,首先看一个比较有意思的代码
#include <thread>
#include <iostream>
#include <sys/time.h>
//设置一个10亿的执行次数
#define MAX_NUM 1000000000
struct TestLine {
int x;
int y;
};
int GetTimeCost(const timeval &beg,const timeval &end) {
return (end.tv_sec-beg.tv_sec) * 1000 + (end.tv_usec-beg.tv_usec)/1000;
}
void T1Func(TestLine* tl){
for( int it = 0; it< MAX_NUM ; ++it) {
tl->x +=1;
}
return;
}
void T2Func(TestLine *tl) {
for ( int it = 0;it < MAX_NUM ; ++it) {
tl->y +=1;
}
return ;
}
int main(){
timeval beg,end;
gettimeofday(&beg,NULL);
TestLine tl = {0,0};
std::thread t1(T1Func,&tl);
std::thread t2(T2Func,&tl);
t1.join();
t2.join();
gettimeofday(&end,NULL);
std::cout << "cost = "<< GetTimeCost(beg,end) << "ms ,x="<< tl.x << ",y="<< tl.y << std::endl;
return 0;
}
这是一段很简单的程序,启动两个线程,分别对结构体中的x变量与y变量进行操作,循环10亿次,在大家看来,这段代码是两个线程分别对两个变量进行操作,其实是两者毫无关联的动作,我们执行一下这段代码,看下耗时

线程执行耗时
接下来咱们再看一下下面的代码
#include <thread>
#include <iostream>
#include <sys/time.h>
//设置一个10亿的执行次数
#define MAX_NUM 1000000000
struct TestLine {
int x;
long long buf[8]; // 新增一个8个long long 类型的数组
int y;
};
int GetTimeCost(const timeval &beg,const timeval &end) {
return (end.tv_sec-beg.tv_sec) * 1000 + (end.tv_usec-beg.tv_usec)/1000;
}
void T1Func(TestLine* tl){
for( int it = 0; it< MAX_NUM ; ++it) {
tl->x +=1;
}
return;
}
void T2Func(TestLine *tl) {
for ( int it = 0;it < MAX_NUM ; ++it) {
tl->y +=1;
}
return ;
}
int main(){
timeval beg,end;
gettimeofday(&beg,NULL);
TestLine tl = {0,0};
std::thread t1(T1Func,&tl);
std::thread t2(T2Func,&tl);
t1.join();
t2.join();
gettimeofday(&end,NULL);
std::cout << "cost = "<< GetTimeCost(beg,end) << "ms ,x="<< tl.x << ",y="<< tl.y << std::endl;
return 0;
}
这段代码与上面的那段代码最大的区别就是:在结构体中增加了一个8个long long类型的数组,接下来我们看下这段代码的执行情况:
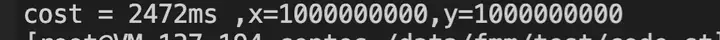
注:以上代码是在C++11环境下进行编译运行,大家可以通过 g++ -lpthread -std=c++11 http://xxx.cc方式进行编译
大家可以看到,这段代码与上段代码最终x与y的输出是一致的,但是耗时上,这段代码要比第一段代码执行时间降低50%以上,为啥?
为什么我已经把数据缓存到本地了,通过增加一个数组,就可以提升程序的运行时间呢?
cache line(缓存行)
通过上面的一个小程序,大家是不是会存在很多疑惑,为啥只是增加了一个数组,整个程序的运行时间就大幅度提高了,下面我们来简单解释一下这里面的原因。
通过上文我们知道,CPU为了提升运行速度,是存在缓存的,但是CPU的缓存,到底缓存了啥呢?数据+指令
CPU的缓存单位是啥呢?cache line,cache line 到底是个啥东西呢?cache line 就是CPU执行时,从内存中读取内容的最小单位,那cache line大小是多少呢?一般是64个字节(当然不同的体系结构及厂商设定的cache line大小是不一样的),为啥是64个字节,不是其他值呢?哈哈,我也不知道,大概率就是测试出来64的性价比+性能是最优的吧。
典型的cache line结构如下:

tag用于标识这个缓存行,data字段用于存储实际的内容数据(这就是我们所说的64字节大小的部分),flag用于标记这个缓存行的状态
如何获取到系统的缓存行大小信息呢?
getconf -a | grep CACHE
上述可以看到,计算机有三层缓存,并且每层缓存中的cache line都是64字节。
现在我们来解释一下上两段代码的差异吧。我们知道CPU缓存数据是以cache line为单位,并且每个cache line的大小大概是64个字节,我们就可以看出,在第一段代码中,结构体中的x成员与y成员,大概率会在同一个cache line 中,如果这两个线程分别对这个cache line进行操作,那么很有可能会造成读写这段cache line临界区的程序变成串行,因为两个线程同时操作一个cache line,肯定会存在覆盖写的问题,为了解决覆盖写,所以这段数据只能是串行(你写完之后,我在读取,然后我在写)这种模式
那再来分析一下第二段代码,第二段代码在两个变量中间增加了long long类型的数组,数组大小为8,为啥是这个数字内,因为上文中简单介绍了,一般cache line的大小是64个字节,当然大家也可以增加一个64个char型的数组,效果其实是一样的。当我们增加了这么第一段看似没有用的数据之后,我们就可以猜测出来,x与y,大概率不会再同一个cache line中了,所以这两个线程操作的是两个不同的cache line,完全可以实现线程的并行执行(因为已经不存在临界区的东西了),所以第二段代码的执行时间也是第一段代码的50%(可解释)
所以通过分析可以得出,CPU虽然把数据进行了缓存,但是这些缓存有时候并不能完全做到数据共享,而是有部分数据发生变化之后,其余CPU的数据也必须跟着发生变化,这就是所谓的CPU缓存的“伪共享”问题。
CPU缓存伪共享的更多相关文章
- JUC源码学习笔记4——原子类,CAS,Volatile内存屏障,缓存伪共享与UnSafe相关方法
JUC源码学习笔记4--原子类,CAS,Volatile内存屏障,缓存伪共享与UnSafe相关方法 volatile的原理和内存屏障参考<Java并发编程的艺术> 原子类源码基于JDK8 ...
- java高并发核心要点|系列5|CPU内存伪共享
上节提到的:伪共享,今天我们来说说. 那什么是伪共享呢? 这得从CPU的缓存结构说起.以下如图,CPU一般来说是有三级缓存,1 级,2级,3级,越上面的,越靠近CPU的,速度越快,成本也越高.也就是说 ...
- cache line 伪共享
https://blog.csdn.net/qq_27680317/article/details/78486220认识CPU Cache CPU Cache概述 随着CPU的频率不断提升,而内存的访 ...
- 什么是CPU缓存
一.什么是CPU缓存 1. CPU缓存的来历 众所周知,CPU是计算机的大脑,它负责执行程序的指令,而内存负责存数据, 包括程序自身的数据.在很多年前,CPU的频率与内存总线的频率在同一层面上.内存的 ...
- CPU缓存是位于CPU与内存之间的临时数据交换器,它的容量比内存小的多但是交换速度却比内存要快得多。CPU缓存一般直接跟CPU芯片集成或位于主板总线互连的独立芯片上
一.什么是CPU缓存 1. CPU缓存的来历 众所周知,CPU是计算机的大脑,它负责执行程序的指令,而内存负责存数据, 包括程序自身的数据.在很多年前,CPU的频率与内存总线的频率在同一层面上.内存的 ...
- 从Java视角理解CPU缓存和伪共享
转载自:http://ifeve.com/from-javaeye-cpu-cache/ http://ifeve.com/from-javaeye-false-shari ...
- 从缓存行出发理解volatile变量、伪共享False sharing、disruptor
volatilekeyword 当变量被某个线程A改动值之后.其他线程比方B若读取此变量的话,立马能够看到原来线程A改动后的值 注:普通变量与volatile变量的差别是volatile的特殊规则保证 ...
- 伪共享(False Sharing)和缓存行(Cache Line)
转载:https://www.jianshu.com/p/a9b1d32403ea https://www.toutiao.com/a6644375612146319886/ 前言 在上篇介绍Long ...
- 简述伪共享和缓存一致性MESI
什么是伪共享 计算机系统中为了解决主内存与CPU运行速度的差距,在CPU与主内存之间添加了一级或者多级高速缓冲存储器(Cache),这个Cache一般是集成到CPU内部的,所以也叫 CPU Cache ...
- Java8的伪共享和缓存行填充--@Contended注释
在我的前一篇文章<伪共享和缓存行填充,从Java 6, Java 7 到Java 8>中, 我们演示了在Java 8中,可以采用@Contended在类级别上的注释,来进行缓存行填充.这样 ...
随机推荐
- 2023/4/18 SCRUM个人博客
1.我昨天的任务 初步学习dlib的安装,了解dlib的基础组件 2.遇到了什么困难 对pandas库了解不到位,需要学习其中的基础 3.我今天的任务 初步了解了pandas库,对series和dat ...
- Jmeter函数助手30-groovy
groovy函数用于脚本执行. 表达式评估:填入Apache Groovy脚本(不是文件名).本身包含逗号的参数值应根据需要进行转义'\,' 存储结果的变量名(可选) 1.引用变量进行截取字符处理 $ ...
- Jmeter函数助手14-TestPlanName
TestPlanName函数获取当前测试计划保存的文件名称.该函数没有参数,直接引用即可${__TestPlanName}.
- 【Java】Collection子接口:其一 List 列接口
Collection子接口 其一:List接口List 接口存储结构:元素有序,且可重复,每个元素都有对应的索引根据索引获取容器元素 实现类有:ArrayList.LinkedList.Vector ...
- 【Uni-App】UniApp转微信小程序发布应用
参考地址: https://www.jianshu.com/p/a77b73f329e4 第一步,把原始Uni-App项目,转成微信小程序项目 点[发行]-- [小程序-微信(仅适用uni-app)] ...
- douyin 今日头条 巨量登录滑块和douyin详情滑块分析
声明(lianxi a15018601872) 本文章中所有内容仅供学习交流使用,不用于其他任何目的,抓包内容.敏感网址.数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均 ...
- 【英伟达】GTC 2024|黄仁勋2小时演讲精华版|六大亮点| Blackwell GPU | DGX B200 | NVL72 | cuLitho | GROOT | Omniverse Cloud —— 智能机器人元年
视频地址: https://www.youtube.com/watch?v=zBIddyiMXsU
- MindSpore分布式并行训练 (GPU-Docker)mindspore—1.2.1—gpu—docker版本运行报错,Failed to init nccl communicator for group,init nccl communicator for group nccl_world_group
如题目所述: 计算框架MindSpore分布式并行训练报错,具体版本:docker-gpu-1.2.1 运行环境: 硬件:Intel CPU, 4卡泰坦 软件:Ubuntu18.04宿主机,docke ...
- Inno Setup 出现 the drive or unc share you selected does not exist or is not accessible 解决记录
背景 软件是使用Inno Setup的,且安装后,再次安装是默认安装到历史路径.一次用户电脑维修后,发现再次安装后报错 解决办法 取消自动安装到默认路径就好了~ UsePreviousAppDir=n ...
- 2.6倍!WhaleTunnel 客户POC实景对弈DataX
作为阿里早期的开源产品,DataX是一款非常优秀的数据集成工具,普遍被用于多个数据源之间的批量同步,包括类似Apache DolphinScheduler的Task类型也对DataX进行了适配和增强, ...