[转帖]使用 EXISTS 代替 IN 和 inner join
在使用Exists时,如果能正确使用,有时会提高查询速度:
1,使用Exists代替inner join
2,使用Exists代替 in
1,使用Exists代替inner join例子:
在一般写sql语句时通常会遇到如下语句:
两个表连接时,取一个表的数据,一般的写法通过关联查询(inner join):
select a.id, a.workflowid,a.operator,a.stepidfrom dbo.[[zping.com]]] ainner join workflowbase b on a.workflowid=b.idand operator='4028814111ad9dc10111afc134f10041'
查询结果:
(1327 行受影响)表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。表 'workflowbase'。扫描计数 1,逻辑读取 293 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。表 '[zping.com]'。扫描计数 1,逻辑读取 1339 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
还有一种写法使用exists来取数据
select a.id,a.workflowid,a.operator ,a.stepidfrom dbo.[[zping.com]]] a where exists(select 'X' from workflowbase b where a.workflowid=b.id)and operator='4028814111ad9dc10111afc134f10041'
执行结果:
(1327 行受影响)表 '[zping.com]'。扫描计数 1,逻辑读取 1339 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。表 'workflowbase'。扫描计数 1,逻辑读取 291 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
这里两着的IO次数,EXISTS比inner join少 2个IO, 对比执行计划成本不一样, 看看两着的差异:
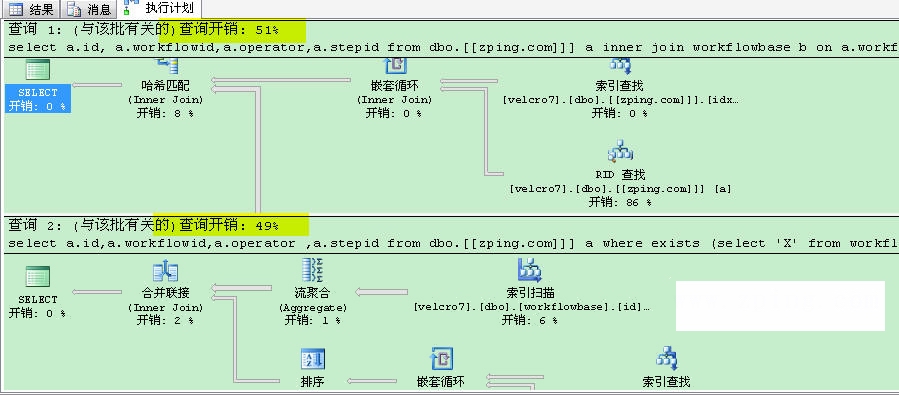
这时我们发现使用EXISTS要比inner join效率稍微高一下。
2,使用Exists代替 in
要求:编写workflowbase表中id不在表中dbo.[[zping.com]]]的行:
一般的写法:
select * from workflowbase where id not in (select a.workflowidfrom dbo.[[zping.com]]] a )
执行结果:
(1 行受影响)表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。表 '[zping.com]'。扫描计数 5,逻辑读取 56952 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。表 'workflowbase'。扫描计数 3,逻辑读取 1589 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
使用Existsl来写:
select * from workflowbase b where not exists(select 'X'from dbo.[[zping.com]]] a where a.workflowid=b.id )
看看执行结果
(1 行受影响)表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。表 '[zping.com]'。扫描计数 3,逻辑读取 18984 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。表 'workflowbase'。扫描计数 3,逻辑读取 1589 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
两个io的差距:56952+1589=58541次 (使用IN)
18984+1589=20573次 (使用Exists)
使用exists是in的2.8倍,查询性能提高很大。
EXISTS 使查询更为迅速,因为RDBMS核心模块将在子查询的条件一旦满足后,立刻返回结果。
in和inner join在大多数情况下都是返回两表的交集,但是两者还是有区别的,如下例子
mysql> select * from a;
+------+------+
| id | name |
+------+------+
| 1 | a |
| 2 | b |
| 3 | c |
+------+------+
MySQL> select * from b;
+------+------+
| id | name |
+------+------+
| 1 | d |
| 1 | g |
| 2 | e |
| 4 | f |
+------+------+
mysql> select a.id, a.name from a where a.id in (select b.id from b);
+------+------+
| id | name |
+------+------+
| 1 | a |
| 2 | b |
+------+------+
mysql> select a.id, a.name from a inner join b on (a.id = b.id);
+------+------+
| id | name |
+------+------+
| 1 | a |
| 1 | a |
| 2 | b |
+------+------+
mysql> select * from a inner join b on (a.id = b.id);
+------+------+------+------+
| id | name | id | name |
+------+------+------+------+
| 1 | a | 1 | d |
| 1 | a | 1 | g |
| 2 | b | 2 | e |
+------+------+------+------+
从查询结果中可以看出,in的结果是不会有重复的,对非主键进行join时,join的结果是有重复的。如果说还有另一个区别的话就是join会产生一个两表合并的临时表,in不会产生两表合并的临时表。
[转帖]使用 EXISTS 代替 IN 和 inner join的更多相关文章
- MySql学习(三) —— 子查询(where、from、exists) 及 连接查询(left join、right join、inner join、union join)
注:该MySql系列博客仅为个人学习笔记. 同样的,使用goods表来练习子查询,表结构如下: 所有数据(cat_id与category.cat_id关联): 类别表: mingoods(连接查询时作 ...
- 使用 EXISTS 代替 IN 和 inner join
在使用Exists时,如果能正确使用,有时会提高查询速度: 1,使用Exists代替inner join 2,使用Exists代替 in 1,使用Exists代替inner join例子: 在一般写s ...
- SQL优化--使用 EXISTS 代替 IN 和 inner join来选择正确的执行计划
在使用Exists时,如果能正确使用,有时会提高查询速度: 1,使用Exists代替inner join 2,使用Exists代替 in 1,使用Exists代替inner join例子: 在一般写s ...
- Sql语句优化-查询两表不同行NOT IN、NOT EXISTS、连接查询Left Join
在实际开发中,我们往往需要比较两个或多个表数据的差别,比较那些数据相同那些数据不相同,这时我们有一下三种方法可以使用:1. IN或NOT IN,2. EXIST或NOTEXIST,3.使用连接查询(i ...
- 为什么 EXISTS(NOT EXIST) 与 JOIN(LEFT JOIN) 的性能会比 IN(NOT IN) 好
前言 网络上有大量的资料提及将 IN 改成 JOIN 或者 exist,然后修改完成之后确实变快了,可是为什么会变快呢?IN.EXIST.JOIN 在 MySQL 中的实现逻辑如何理解呢?本文也是比较 ...
- MySQL中exists和in的区别及使用场景
exists和in的使用方式: 1 #对B查询涉及id,使用索引,故B表效率高,可用大表 -->外小内大 1 select * from A where exists (select * fro ...
- MySQL Execution Plan--NOT EXISTS子查询优化
在很多业务场景中,会使用NOT EXISTS语句来确保返回数据不存在于特定集合,部分场景下NOT EXISTS语句性能较差,网上甚至存在谣言"NOT EXISTS无法走索引". 首 ...
- in和exists
exists和in的使用方式: #对B查询涉及id,使用索引,故B表效率高,可用大表 -->外小内大 select * from A where exists (select * from B ...
- MySQL中Exists和In的使用
Exists关键字: exists表示存在,是对外表做loop循环,每次loop循环再对内表(子查询)进行查询,那么因为对内表的查询使用的索引(内表效率高,故可用大表),而外表有多大都需要遍历,不可避 ...
- 【转载】 mysql explain用法
转载链接: mysql explain用法 官网说明: http://dev.mysql.com/doc/refman/5.7/en/explain-output.html 参数: htt ...
随机推荐
- python Django api 返回图片
re_path(r"report_img/(.*)$",views.ReportImage.as_view()) def return_img(request): img_dir ...
- 【技术控请进】华为云DevCloud深色模式开发解读
引言 近期,华为云DevCloud推出了开发者友好的深色模式,深受开发者们的喜爱和关注.大家都知道,深色模式(Dark Mode)在iOS13 引入该特性后各大应用和网站都开始支持了深色模式.在这之前 ...
- 解锁华为云AI如何助力无人车飞驰“新姿势”,大赛冠军有话说
摘要:在2020年第二届华为云人工智能大赛•无人车挑战杯赛道中,"华中科技大学无人车一队"借助华为云一站式AI开发与管理平台ModelArts及HiLens端云协同AI开发应用平台 ...
- DTSE Tech Talk丨第2期:1小时深度解读SaaS应用系统设计
摘要:介绍在SaaS场景下如何技术选型,SaaS架构设计中关键的技术点等内容. 本文分享自华为云社区<DTSE Tech Talk丨第2期:1小时深度解读SaaS应用系统设计>,作者: 华 ...
- GaussDB(DWS) NOT IN优化技术解密:排他分析场景400倍性能提升
摘要:本文针对8.1.2版本中的NOT IN场景的Mixed-HashJoin新技术进行介绍.该技术在GaussDB(DWS)与招商银行的联创项目中落地,为招商银行的批量作业带来了总体15%的性能提升 ...
- 深度克隆从C#/C/Java漫谈到JavaScript真复制
如果只想看js,直接从JavaScript标题开始. 在C#里面,深度clone有System.ICloneable.创建现有实例相同的值创建类的新实例 克隆原理 值类型变量与引用类型变量 如果我们有 ...
- 火山引擎 DataTester 推出可视化数据集成方案
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 随着数字化的长期演进,企业中往往存在多个运行在不同平台的数字系统,这些数据源彼此独立,数据跨系统间的交流.共享和融 ...
- PPT 年终总结PPT 应该怎么样改
- Java SpringBoot Test 单元测试中包括多线程时,没跑完就结束了
如何阻止 Java SpringBoot Test 单元测试中包括多线程时,没跑完就结束了 使用 CountDownLatch CountDownLatch.CyclicBarrier 使用区别 多线 ...
- PPT 没有电脑如何制作PPT
没有电脑如何制作PPT