[转帖]使用 EXISTS 代替 IN 和 inner join
在使用Exists时,如果能正确使用,有时会提高查询速度:
1,使用Exists代替inner join
2,使用Exists代替 in
1,使用Exists代替inner join例子:
在一般写sql语句时通常会遇到如下语句:
两个表连接时,取一个表的数据,一般的写法通过关联查询(inner join):
select a.id, a.workflowid,a.operator,a.stepidfrom dbo.[[zping.com]]] ainner join workflowbase b on a.workflowid=b.idand operator='4028814111ad9dc10111afc134f10041'
查询结果:
(1327 行受影响)表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。表 'workflowbase'。扫描计数 1,逻辑读取 293 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。表 '[zping.com]'。扫描计数 1,逻辑读取 1339 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
还有一种写法使用exists来取数据
select a.id,a.workflowid,a.operator ,a.stepidfrom dbo.[[zping.com]]] a where exists(select 'X' from workflowbase b where a.workflowid=b.id)and operator='4028814111ad9dc10111afc134f10041'
执行结果:
(1327 行受影响)表 '[zping.com]'。扫描计数 1,逻辑读取 1339 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。表 'workflowbase'。扫描计数 1,逻辑读取 291 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
这里两着的IO次数,EXISTS比inner join少 2个IO, 对比执行计划成本不一样, 看看两着的差异:
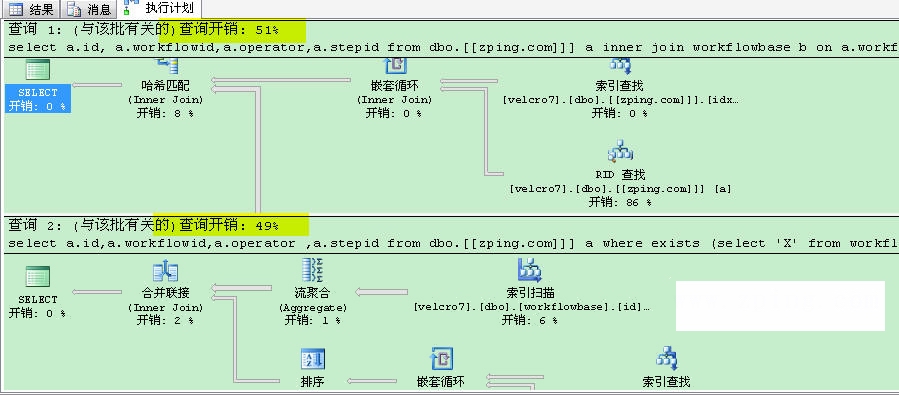
这时我们发现使用EXISTS要比inner join效率稍微高一下。
2,使用Exists代替 in
要求:编写workflowbase表中id不在表中dbo.[[zping.com]]]的行:
一般的写法:
select * from workflowbase where id not in (select a.workflowidfrom dbo.[[zping.com]]] a )
执行结果:
(1 行受影响)表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。表 '[zping.com]'。扫描计数 5,逻辑读取 56952 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。表 'workflowbase'。扫描计数 3,逻辑读取 1589 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
使用Existsl来写:
select * from workflowbase b where not exists(select 'X'from dbo.[[zping.com]]] a where a.workflowid=b.id )
看看执行结果
(1 行受影响)表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。表 '[zping.com]'。扫描计数 3,逻辑读取 18984 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。表 'workflowbase'。扫描计数 3,逻辑读取 1589 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
两个io的差距:56952+1589=58541次 (使用IN)
18984+1589=20573次 (使用Exists)
使用exists是in的2.8倍,查询性能提高很大。
EXISTS 使查询更为迅速,因为RDBMS核心模块将在子查询的条件一旦满足后,立刻返回结果。
in和inner join在大多数情况下都是返回两表的交集,但是两者还是有区别的,如下例子
mysql> select * from a;
+------+------+
| id | name |
+------+------+
| 1 | a |
| 2 | b |
| 3 | c |
+------+------+
MySQL> select * from b;
+------+------+
| id | name |
+------+------+
| 1 | d |
| 1 | g |
| 2 | e |
| 4 | f |
+------+------+
mysql> select a.id, a.name from a where a.id in (select b.id from b);
+------+------+
| id | name |
+------+------+
| 1 | a |
| 2 | b |
+------+------+
mysql> select a.id, a.name from a inner join b on (a.id = b.id);
+------+------+
| id | name |
+------+------+
| 1 | a |
| 1 | a |
| 2 | b |
+------+------+
mysql> select * from a inner join b on (a.id = b.id);
+------+------+------+------+
| id | name | id | name |
+------+------+------+------+
| 1 | a | 1 | d |
| 1 | a | 1 | g |
| 2 | b | 2 | e |
+------+------+------+------+
从查询结果中可以看出,in的结果是不会有重复的,对非主键进行join时,join的结果是有重复的。如果说还有另一个区别的话就是join会产生一个两表合并的临时表,in不会产生两表合并的临时表。
[转帖]使用 EXISTS 代替 IN 和 inner join的更多相关文章
- MySql学习(三) —— 子查询(where、from、exists) 及 连接查询(left join、right join、inner join、union join)
注:该MySql系列博客仅为个人学习笔记. 同样的,使用goods表来练习子查询,表结构如下: 所有数据(cat_id与category.cat_id关联): 类别表: mingoods(连接查询时作 ...
- 使用 EXISTS 代替 IN 和 inner join
在使用Exists时,如果能正确使用,有时会提高查询速度: 1,使用Exists代替inner join 2,使用Exists代替 in 1,使用Exists代替inner join例子: 在一般写s ...
- SQL优化--使用 EXISTS 代替 IN 和 inner join来选择正确的执行计划
在使用Exists时,如果能正确使用,有时会提高查询速度: 1,使用Exists代替inner join 2,使用Exists代替 in 1,使用Exists代替inner join例子: 在一般写s ...
- Sql语句优化-查询两表不同行NOT IN、NOT EXISTS、连接查询Left Join
在实际开发中,我们往往需要比较两个或多个表数据的差别,比较那些数据相同那些数据不相同,这时我们有一下三种方法可以使用:1. IN或NOT IN,2. EXIST或NOTEXIST,3.使用连接查询(i ...
- 为什么 EXISTS(NOT EXIST) 与 JOIN(LEFT JOIN) 的性能会比 IN(NOT IN) 好
前言 网络上有大量的资料提及将 IN 改成 JOIN 或者 exist,然后修改完成之后确实变快了,可是为什么会变快呢?IN.EXIST.JOIN 在 MySQL 中的实现逻辑如何理解呢?本文也是比较 ...
- MySQL中exists和in的区别及使用场景
exists和in的使用方式: 1 #对B查询涉及id,使用索引,故B表效率高,可用大表 -->外小内大 1 select * from A where exists (select * fro ...
- MySQL Execution Plan--NOT EXISTS子查询优化
在很多业务场景中,会使用NOT EXISTS语句来确保返回数据不存在于特定集合,部分场景下NOT EXISTS语句性能较差,网上甚至存在谣言"NOT EXISTS无法走索引". 首 ...
- in和exists
exists和in的使用方式: #对B查询涉及id,使用索引,故B表效率高,可用大表 -->外小内大 select * from A where exists (select * from B ...
- MySQL中Exists和In的使用
Exists关键字: exists表示存在,是对外表做loop循环,每次loop循环再对内表(子查询)进行查询,那么因为对内表的查询使用的索引(内表效率高,故可用大表),而外表有多大都需要遍历,不可避 ...
- 【转载】 mysql explain用法
转载链接: mysql explain用法 官网说明: http://dev.mysql.com/doc/refman/5.7/en/explain-output.html 参数: htt ...
随机推荐
- HDU 4893 线段树延迟标记
原题链接 题意 初始有一长度为n,全为0的序列 每次我们可以对这个序列进行三种操作: 1.将某个位置的数加上d 2.输出某个区间的和 3.将某个区间内每个数字变为与其最接近的斐波那契数,如果有两个最相 ...
- maven系列:聚合与继承
目录 一.聚合 创建Maven模块,设置打包类型为pom 设置当前聚合工程所包含的子模块名称 二. 继承 问题导入 创建Maven模块,设置打包类型为pom 在父工程的pom文件中配置依赖关系(子工程 ...
- C# / VB.NET 获取PDF文档的数字签名信息
文档中的数字签名具有不可否认性,可有效防伪防篡改.对文档中已有的数字签名信息,可通过一定方法获取,下面通过程序代码介绍如何来实现.程序中,使用了Spire.PDF.dll,版本:6.11.6,可自行在 ...
- 理论+实践详解最热的LLM应用框架LangChain
本文分享自华为云社区<LangChain是什么?LangChain的详细介绍和使用场景>,作者:码上开花_Lancer . 一.概念介绍 1.1 Langchain 是什么? 官方定义是: ...
- 关于汽车OTA,这篇科普文能告诉你
随着汽车中软件发挥的作用越来越重要,软件定义汽车已经是行业内的共识.汽车行业的发展极有可能最终像手机产业一样,基础硬件差异会越来越小,关键在于汽车给用户的体验的多样性,以及汽车产品在不同场景下满足用户 ...
- 几款Java开发者必备常用的工具,准点下班不在话下
摘要:一问一答的形式轻松学习掌握java工具. 以一问一答的形式学习java工具 Q:检查内存泄露的工具有?A: jmap生成dump转储文件,jhat可视化查看. Q:某进程CPU使用率一直占满,用 ...
- 快来一起玩转LiteOS组件:Curl
摘要:Curl是一个文件传输工具,常用于数据上传和下载,本demo基于Cloud_STM32F429IGTx_FIRE开发板演示了在curl demo中调用curl提供的API来下载一个文件,并将其保 ...
- A/B测试助力游戏业务增长
更多技术交流.求职机会.试用福利,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 中国游戏行业发展现状及挑战 国内市场增长乏力 2021年游戏销售收入2965.13亿元,同比增长6.4% ...
- Java 事件链
Java中的事件机制的参与者有3种角色: 1. event object:就是事件产生时具体的"事件",用于listener的相应的方法之中,作为参数,一般存在于listerner ...
- python jira 读取表数据批量新建子任务
小李在Jira中处理任务时,发现一个表格数据很有趣.他决定为每一行数据创建一个新的子任务.他复制粘贴,忙得不亦乐乎.同事小张路过,好奇地问:"你在做什么?"小李得意地回答:&quo ...