论文精读:用于少样本图像识别的语义提示(Semantic Prompt for Few-Shot Image Recognition)
原论文于2023.11.6撤稿,原因:缺乏合法的授权,详见此处
Abstract
在小样本学习中(Few-shot Learning, FSL)中,有通过利用额外的语义信息,如类名的文本Embedding,通过将语义原型与视觉原型相结合来解决样本稀少的问题。但这种方法可能会遇到稀有样本中学到噪声特征导致收益有限。在这篇论文,作者提出了一种用于少样本学习的语义提示(Semantic Prompt, SP)方法,不同于简单地利用语义信息纠正分类器,而是选择用语义信息作为提示(prompt)去自适应调整视觉特征提取网络。
具体来说,作者设计了两种互补机制,将语义提示插入特征提取器:1、在空间维度上,通过自注意力机制使语义提示和局部图块(patch)embedding相互作用;2、在通道维度上,用变换后的语义提示补充视觉特征。通过结合这两种机制,特征提取器能更好地关注特定类的特征,并仅用了较少的支持样本就能得到通用的图像表示。
1. 引言
在解决小样本问题时,最有效的FSL方法是利用从大量标记基础数据集学习而来的先验知识,并将先验知识编码为一组初始网络参数,或者在所有的类中共享固定的嵌入函数。
由于缺少新的类的带标签图像,一种直接替代方式是使用其他模式的辅助信息,例如语言模型,来帮助学习新的类,这在zero-shot中已经被广泛使用了。这些方法通常直接使用文本embeddings用于新的类的图像分类器。基于此,一些FSL研究提出了从类名推断文本原型,并将其与从罕见的支持图像中提取的视觉原型结合。另一些方法通过引入更复杂的文本预测器,或者利用大规模预训练模型产出更准确的文本原型。
这些方法大多直接从文本特征中得到类的原型,忽视了文本特征与视觉特征的信息差。确切来说,文本特征可能包含了新的类与已知的类之间的语义联系,但由于缺少与底层视觉表示的交互,这些方法不能提供能确切区分新类的视觉特征。此外,由于有限的支持图像,学习到的视觉特征仍然遭受噪声特征的影响,例如背景的干扰。
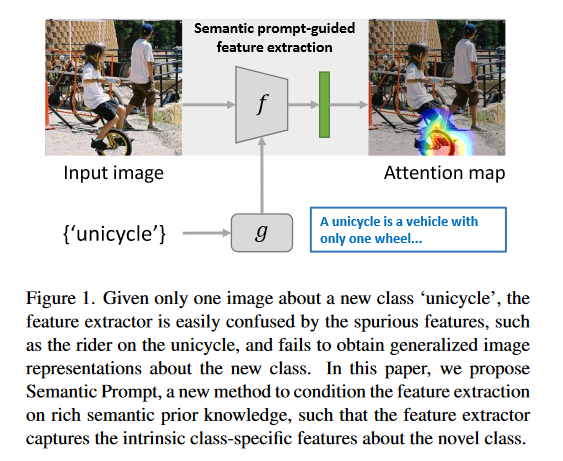
在图一中,对于一个新类“unicycle”,特征提取器可能会将unicycle图像和其他干扰因素作为图像特征,干扰因素可能包含骑手和房屋,并在其他场景下不能识别unicycle。本文中,作者选择使用文本特征作为语义提示去自适应调整特征提取网络,如图一所示,在语义提示的指导下,特征提取器注重捕获新类的固有特征而不是杂乱的背景。
此外,在大规模训练的自然语言模型(Natural Language Process, NLP)如BERT和GPT能从类名挖掘丰富的文本信息。通过语义提示和视觉特征相互作用,可以帮助特征提取器判断视觉特征时提供附加信息,并产生更通用的类原型。
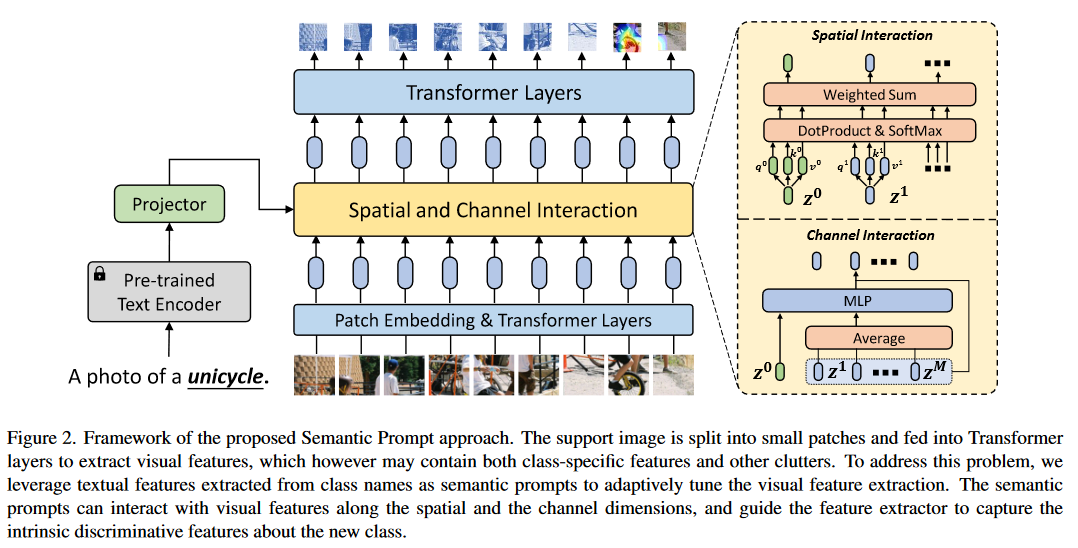
语义提示与视觉特征的相互作用发生在空间维度与通道维度。
- 空间维度上,用语义提示扩展图像块序列,并输入到Transformer的Encoder中,通过自注意力层,语义提示可以使特征提取器关注类的特定特征并一直其他干扰因素;
- 通道维度上,首先将语义提示与从所有图像块中提取的视觉上下文连接,然后投喂进多层感知机(Multilayer Perceptron, MLP)模块。提取的特征向量会被添加到每个图像块中,在逐个通道中调整与增强视觉特征。
2. 问题设置
FSL问题中通常被定义为N-way、K-shot分类任务,对于查询集\(Q\)的样本\(x^q\),模型能将其分类在\(C_{novel}\)的\(N\)个类中的某一个。训练数据为支持集\(S\)的少量带标签样本\((x^s_i,y^s_i)^{N\times K}_{i=1}\)。由于支持集较少,在FSL训练之前,会在大量标记的数据集\(D_{base}\)预训练模型。注意,\(C_{base}\cap C_{novel}=\varnothing\),这表示训练的类与测试的类完全不同,模型学习到的仅是泛化未知的类的能力。
在之前的工作中,图像的标签\(y\)通常使用one-hot编码表示,如\(y=[0,1,0,0,\dots]\),这种表示会导致物体概念和文本标签中的语义信息被抹去。本文中,为了使语义能被提取,作者保留了文本标签如\('cat', 'dog'\)。并把这种label表示为\(y^{text}\)与one-hot表示的\(y\)相区分。
3. 方法
3.1 预训练
在FSL中,学习通用特征提取器是将知识转移到下游学习任务的关键。在给定的标签数据集\(D_{base}\)中,采用简单的监督学习范式来学习特征提取器。线性分类的权重矩阵和偏置向量与输入特征向量\(f(x)\)运算并映射到其中一个基础类,并通过最小化标准交叉熵损失函数进行训练:
\]
其中,\(W_i,b_i\)表示分类器对于\(i\)类的权重与偏置。
对于骨干网络的选择,为了促进视觉特征与语义提示相互作用,采用Vision Transformer作为图像特征提取器\(f\)。对于输入图像\(x\in\mathbb{R}^{H\times W\times C}\)首先被分为\(M\)个图像块序列\(X=\{x^1_p,x^2_p,\dots,x^M_p\}\),其中\(x^i_p\in\mathbb{R}^{P\times P\times C}\),\(P\)表示图像块的大小。然后每一个图像块将被转为embedding向量并加入位置embedding,此时作为Transformer输入的图像块可以写为\(Z_0=[z_0^1,z_0^2,\dots,z_0^M]\),其中\(z^i_0\in\mathbb{R}^{C_z}\)是位于位置\(i\)的图像块token,\(C_z\)为每个token的通道数。
每一个图像块token都会被投入Transformer层L,提取视觉特征。每一个特征由多头自注意力(Multihead Self-Attention, MSA)、MLP块、归一化层和残差连接组成(各个层的结构顺序如下图所示)。在L的顶层,将所有token序列中的embedding向量求平均作为提取的图像特征:
\]
其中\(z_L^i\)是在L层的第\(i\)个token的embedding向量。

图片来源:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale。文中改进了Transformer并应用于计算机视觉,作者将其命名为Vision Transformer(ViT)。
自注意力的计算量为序列长度的平方,为了降低计算成本,采用ViT的变体Visformer作为Transformer层的实现。
3.2 语义提示
在基础训练进行预训练后的特征提取器\(f\)可以从输入图像提取大量的视觉特征,为了准确识别,我们还需要语义信息作为提示指导网络,在样本数量少的情况获得更好的泛化能力。具体来说,类名就是终于的语义信息,文中使用大规模预训练的NLP模型从类名中提取语义特征。
在一次训练的episode,对于支持集的图像\(x^s\)的类名\(y^{text}\)投喂进预训练的语言模型\(g(\cdot)\),得到语义特征\(g(y^{text})\)。语义特征被用于调整样本较少的类的调整,这个过程记为:\(f_g(x^s)=f(x^s|g(y^{text}))\)。每个类中,对这些特征求平均计算类的原型,\(p_i\)表示第\(i\)个类的原型。
\]
其中\(x_j^s\)是\(i\)的第\(j\)个支持图像。
episode: episode指一次训练的子任务。举例来说,假设正在使用元学习来训练一个模型来识别不同的动物。每个episode可能代表一个特定的识别任务,比如在一个episode中,模型需要学会识别猫和狗,而在另一个episode中,模型需要学会识别鸟类和鱼类。每个episode都会提供一组训练样本,以及模型需要尽快学会正确分类这些样本的机会。
在元训练中,会冻结文本编码器\(g(\cdot)\)并使用交叉熵损失函数最大化查询样本与原型的特征相似度来微调其他参数:
\]
其中\(s\)是余弦相似度,\(p_{y^q}\)是类\(y^q\)的原型,\(\tau\)是温度参数。
3.2.1 空间维度的相互作用
对于给定的语义特征\(g(y^{text})\)和\(l\)层的输入图像序列embedding\(Z_{l-1}=[z_{l-1}^1,z_{l-1}^2,\dots,z_{l-1}^M]\in\mathbb{R}^{M\times C_z}\),之后通过投影的(projected)语义特征扩展\(Z_{l-1}\)得到\(\hat{Z}_{l-1}\in\mathbb{R}^{(M+1)\times C_z}\):
\]
其中,\(z^0=h_s(g(y^{text}))\in\mathbb{R}^{C_z}\)是投影的语义embedding用于空间交互,\(h_s\)是保持语义embedding和图像块embedding维度相同的投影器(projector)。之后,\(\hat{Z}_{l-1}\)被投喂进Transformer的\(l\)层的MSA模块,MSA模块首先将每个token映射为三个向量\(q,k,v\in\mathbb{R}^{N_h\times(M+1)\times C_h}\),映射的投影参数为\(W_{qkv}\),即:
\]
其中,\(N_h\)是MSA中头的数量,\(C_h\)是每个头的通道数。之后计算注意力权重\(A\in\mathbb{R}^{N_h\times(M+1)\times(M+1)}\)。
\]
注意力权重可以聚合不同位置的信息,最终输出通过连接所有头的输出并由参数\(W_{out}\)投影获得:
\]
公式(6)-(8)可参考Transformer原论文
3.2.2 通道维度的相互作用
除了通过MSA进行空间上的相互作用外,还提出了另一种交互机制:可以根据输入的语义提示逐个通道得调节和增强视觉特征。对于\(l\)层的输入图像块embedding序列\(Z_{l-1}=[z^2_{l-1},z^1_{l-1},\dots,z^M_{l-1}]\in\mathbb{R}^{R_z}\),首先所有图像块token取平均得到全局视觉上下文向量\(z^c_{l-1}\in\mathbb{R}^{C_z}\):
\]
将视觉特征\(z^c_{l-1}\)与投影的语义向量\(z^0=h_c(g(h_{text}))\in\mathbb{R}^{R_c}\)连接,并投喂进2层MLP模块,得到调节后的向量
\]
其中,\(W_1,b_1,W_2,b_2\)是MLP模块的参数,\(\sigma\)是激活函数,\(h_c\)是通道交互的投影器。
最后,将图像块token与上面得到的调节向量相加以调整每个通道上的视觉特征,调整的序列为\(\hat{Z}_{l-1}\in\mathbb{R}^{M\times C_z}\)
\]
4. 实验
4.1 数据集测试
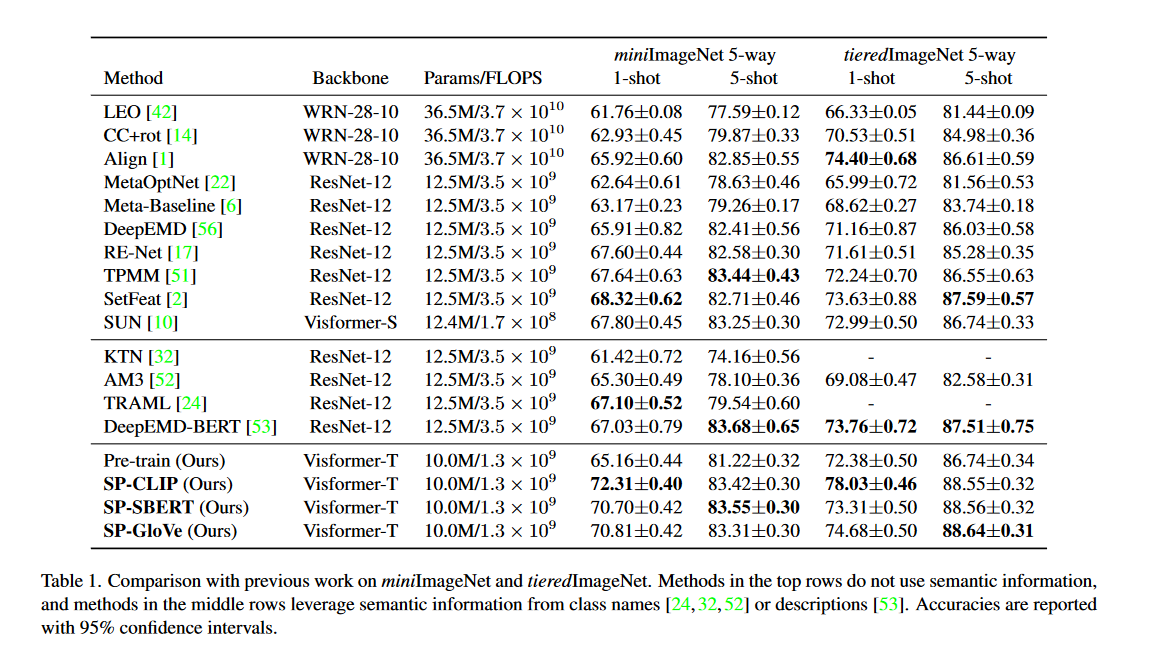
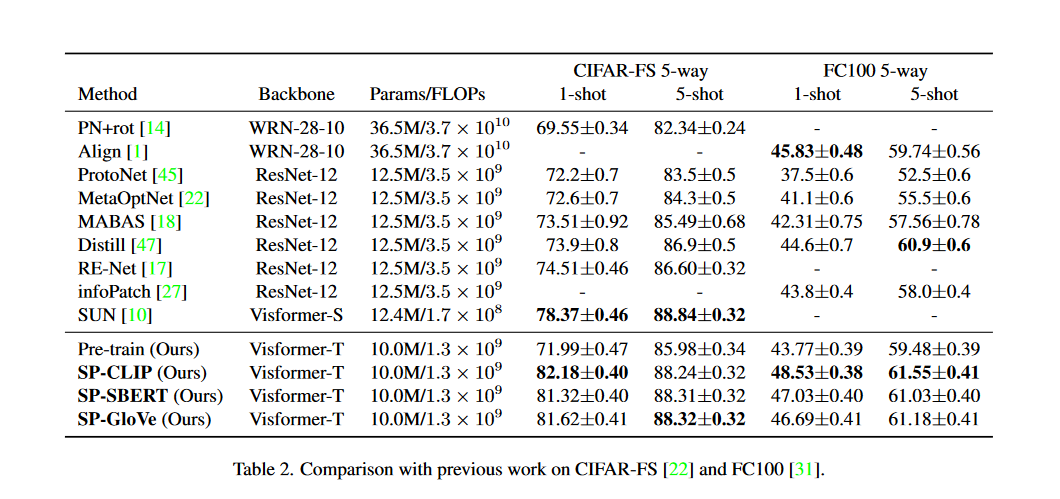
作者在四个数据集上与其他SOTA方法进行对比试验如表1、表2所示。对于预训练的文本编码器,一共试验了三种:CLIP、SBERT、GloVe。对于CLIP的使用输入采用模板:A photo of a {class name}。而其他两种文本编码器的输入为类名。如果名称中有多个单词,则对输出单词向量求平均。文中默认使用的文本编码器为ClIP。
可以看到之前的方法通常采用CNN作为骨干网络,对比同样以Visformer-S的SUN,准确率提升了2.46%
4.2 模型分析
4.2.1 消融研究
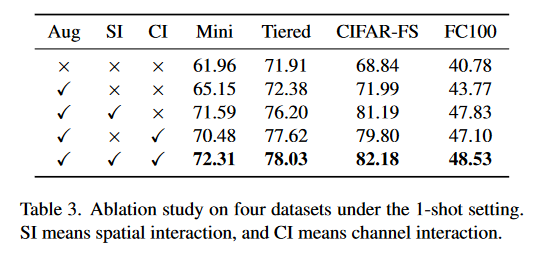
文中进行了消融研究,结果如表3所示,证明图像增强与两种交互机制的有效性。
4.2.2 层的选择
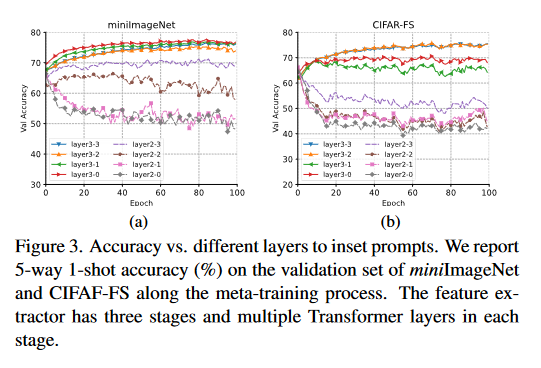
特征提取器有三个阶段,每个阶段含有多个Transformer层。理论上语义提示可以在任意层插入,实验研究了二、三阶段不同层插入语义提示的实验结果。可以发现,插入高层时模型的表现较好,插入低层时模型的表现下降。文中认为语义提示向量特定于类,而更高层的网络层提取的特征特定于类,而在低层提取的特征会在类间共享。在图3中,可以看到语义提示插入三阶段的整体表现较好,语义提示默认插入位置为layer3-2(三阶段的第二层)。
4.2.3 骨干网络和分类器架构
表4中用两种骨干网络测试了3种baseline方法,可见骨干网络的替换并不能明显提高精度,而使用了语义提示后精度得到了明显提高。表5中比较两种分类器余弦距离分类器和线性逻辑回归分类器,两者的精度差距不大。

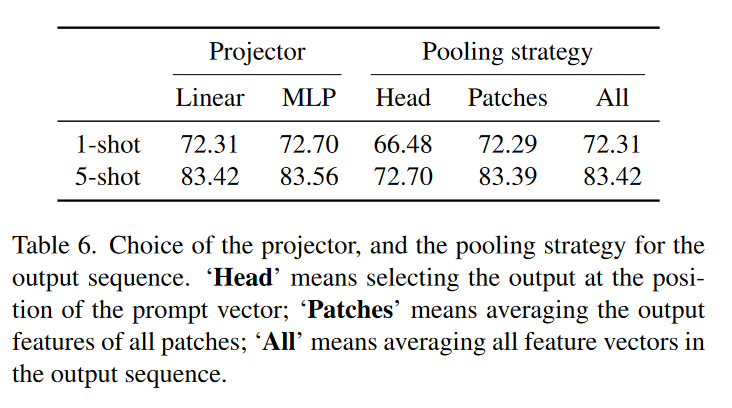
4.2.4 投影器和池化策略
表6可以看到,投影器的选择对精度影响不大,不管是线性还是多层感知机都表现良好。但池化的策略选择对精度影响较大,当选择Head策略时,模型精度较差,这表明仅通过语义特征无法获得较好的泛化能力。
- Head: 选择语义提示向量位置处的输出(公式(5)的\(z^0\));
- Patch: 对所有图像块的特征取平均(公式(5)的\(z_{l-1}^1,\dots,z_{l-1}^M\));
- All: 对所有特征向量取平均。
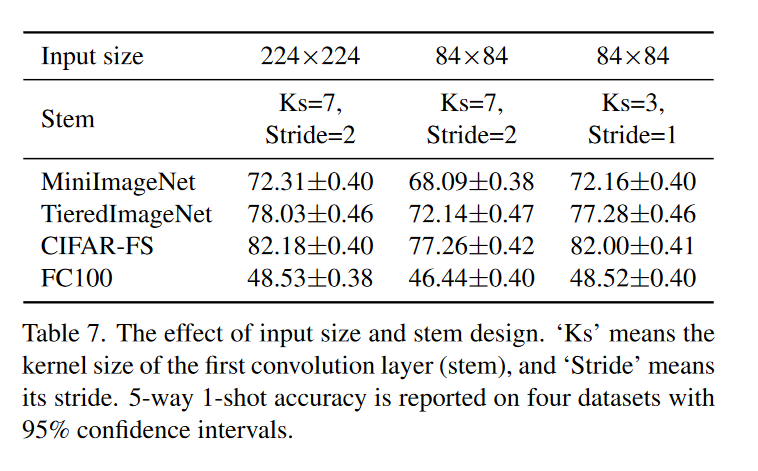
4.2.5 图像大小和主干设计
表7可以看到,保持卷积主干不变的情况下缩小图像会导致精度下降,因为此时卷积核和卷积步幅太大不能捕获详细的视觉特征,如果相应地减少卷积核和步幅,精度会提高。
4.2.6 可视化
在图4中,对注意力图进行可视化。在预训练的baseline中夹杂着背景信息,如果给出特定的文本提示,模型就能专注于某一部分(蜘蛛或是蛛网)。

5. 总结
本文提出了一种新颖的 FSL 语义提示(SP)方法,该方法利用从类名派生的语义特征自适应地调整特征提取。所提出的方法在四个基准数据集上进行了评估,并相对于以前的方法取得了显着的改进。更深入的分析表明,SP 鼓励模型提取更多类别特定的特征,并且对不同的文本编码器和模型设计具有健壮性。
参考文献
- Chen, Wentao, et al. "Semantic Prompt for Few-Shot Image Recognition." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.
论文精读:用于少样本图像识别的语义提示(Semantic Prompt for Few-Shot Image Recognition)的更多相关文章
- R-CNN论文翻译——用于精确物体定位和语义分割的丰富特征层次结构
原文地址 我对深度学习应用于物体检测的开山之作R-CNN的论文进行了主要部分的翻译工作,R-CNN通过引入CNN让物体检测的性能水平上升了一个档次,但该文的想法比较自然原始,估计作者在写作的过程中已经 ...
- NeurIPS 2019 | 基于Co-Attention和Co-Excitation的少样本目标检测
论文提出CoAE少样本目标检测算法,该算法使用non-local block来提取目标图片与查询图片间的对应特征,使得RPN网络能够准确的获取对应类别对象的位置,另外使用类似SE block的sque ...
- (转载)基于比较的少样本(one/few-shoting)分类
基于比较的方法 先通过CNN得到目标特征,然后与参考目标的特征进行比较. 不同在于比较的方法不同而已. 基本概念 数据集Omniglot:50种alphabets(文字或者文明); alphabet中 ...
- Generalizing from a Few Examples: A Survey on Few-Shot Learning(从几个例子总结经验:少样本学习综述)
摘要:人工智能在数据密集型应用中取得了成功,但它缺乏从有限的示例中学习的能力.为了解决这一问题,提出了少镜头学习(FSL).利用先验知识,可以快速地从有限监督经验的新任务中归纳出来.为了全面了解FSL ...
- 腾讯推出超强少样本目标检测算法,公开千类少样本检测训练集FSOD | CVPR 2020
论文提出了新的少样本目标检测算法,创新点包括Attention-RPN.多关系检测器以及对比训练策略,另外还构建了包含1000类的少样本检测数据集FSOD,在FSOD上训练得到的论文模型能够直接迁移到 ...
- 增量学习不只有finetune,三星AI提出增量式少样本目标检测算法ONCE | CVPR 2020
论文提出增量式少样本目标检测算法ONCE,与主流的少样本目标检测算法不太一样,目前很多性能高的方法大都基于比对的方式进行有目标的检测,并且需要大量的数据进行模型训练再应用到新类中,要检测所有的类别则需 ...
- Debiased Contrastive Learning of Unsupervised Sentence Representations 论文精读
1. 介绍(Introduction) 问题: 由PLM编码得到的句子表示在方向上分布不均匀, 在向量空间中占据一个狭窄的锥形区域, 这在很大程度上限制了它们的表达能力. 已有的解决办法: 对比学习. ...
- 【深度学习 论文篇 02-1 】YOLOv1论文精读
原论文链接:https://gitee.com/shaoxuxu/DeepLearning_PaperNotes/blob/master/YOLOv1.pdf 笔记版论文链接:https://gite ...
- 论文阅读 | A Curriculum Domain Adaptation Approach to the Semantic Segmentation of Urban Scenes
paper链接:https://arxiv.org/pdf/1812.09953.pdf code链接:https://github.com/YangZhang4065/AdaptationSeg 摘 ...
- 语义分割(semantic segmentation) 常用神经网络介绍对比-FCN SegNet U-net DeconvNet,语义分割,简单来说就是给定一张图片,对图片中的每一个像素点进行分类;目标检测只有两类,目标和非目标,就是在一张图片中找到并用box标注出所有的目标.
from:https://blog.csdn.net/u012931582/article/details/70314859 2017年04月21日 14:54:10 阅读数:4369 前言 在这里, ...
随机推荐
- L1-018 大笨钟 (10分)
开始天梯赛专项训练 微博上有个自称"大笨钟V"的家伙,每天敲钟催促码农们爱惜身体早点睡觉.不过由于笨钟自己作息也不是很规律,所以敲钟并不定时.一般敲钟的点数是根据敲钟时间而定的,如 ...
- SpringBoot 集成短信和邮件
准备工作 1.集成邮件 以QQ邮箱为例 在发送邮件之前,要开启POP3和SMTP协议,需要获得邮件服务器的授权码,获取授权码: 1.设置>账户 在账户的下面有一个开启SMTP协议的开关并进行密码 ...
- 公共号码池redis实现方案
概述 在企业级呼叫模型中,号码资源总是有限的,企业员工在使用有限的号码资源外呼时,就会有号码冲突的问题,如何解决多人共用少量号码的选号问题? 最近有一个新的业务需求,需要解决公共号码池的选号问题,号码 ...
- 碎碎念 | 20230326 · 与 SEU & 南传跆协共进晚餐
(碎碎念)今天晚上跟社团一起吃饭,南传的跆协来交流了.南传的人说 他们基本散养,没人正经自习 图书馆基本废弃,校园里有一个大舞台 每天表演,大家每天写剧本 / 演绎 / 拍摄 剪辑,天天喝庆功酒()然 ...
- Angular系列教程之依赖注入详解
.markdown-body { line-height: 1.75; font-weight: 400; font-size: 16px; overflow-x: hidden; color: rg ...
- python3使用json、pickle和sqlite3持久化存储字典对象
技术背景 在各种python的项目中,我们时常要持久化的在系统中存储各式各样的python的数据结构,常用的比如字典等.尤其是在云服务类型中的python项目中,要持久化或者临时的在缓存中储存一些用户 ...
- restful-接口风格
- [转帖]命令行参数--与-D的区别
https://juejin.cn/post/7238420276228341815 Spring Boot 学习笔记 我们要想了解这两者之间的差异,首先来看一个案例: bash 复制代码 # ...
- [转帖]Linux fsync和fdatasync系统调用实现分析(Ext4文件系统)
转自:https://blog.csdn.net/luckyapple1028/article/details/61413724 在Linux系统中,对文件系统上文件的读写一般是通过页缓存(pag ...
- [转帖]tidb RESTORE
https://docs.pingcap.com/zh/tidb/v4.0/sql-statement-restore RESTORE 语句用于执行分布式恢复,把 BACKUP 语句生成的备份文件恢复 ...