模拟IDC spark读写MaxCompute实践
简介: 现有湖仓一体架构是以 MaxCompute 为中心读写 Hadoop 集群数据,有些线下 IDC 场景,客户不愿意对公网暴露集群内部信息,需要从 Hadoop 集群发起访问云上的数据。本文以 EMR (云上 Hadoop)方式模拟本地 Hadoop 集群访问 MaxCompute数据。
一、背景
1、背景信息
现有湖仓一体架构是以 MaxCompute 为中心读写 Hadoop 集群数据,有些线下 IDC 场景,客户不愿意对公网暴露集群内部信息,需要从 Hadoop 集群发起访问云上的数据。本文以 EMR (云上 Hadoop)方式模拟本地 Hadoop 集群访问 MaxCompute数据。
2、基本架构

二、搭建开发环境
1、EMR环境准备
(1)购买
① 登录阿里云控制台 - 点击右上角控制台选项 https://www.aliyun.com/accounttraceid=bc277aa7c0c64023b459dd695ac328b1jncu

② 进入到导航页 - 点击云产品 - E-MapReduce(也可以搜索)
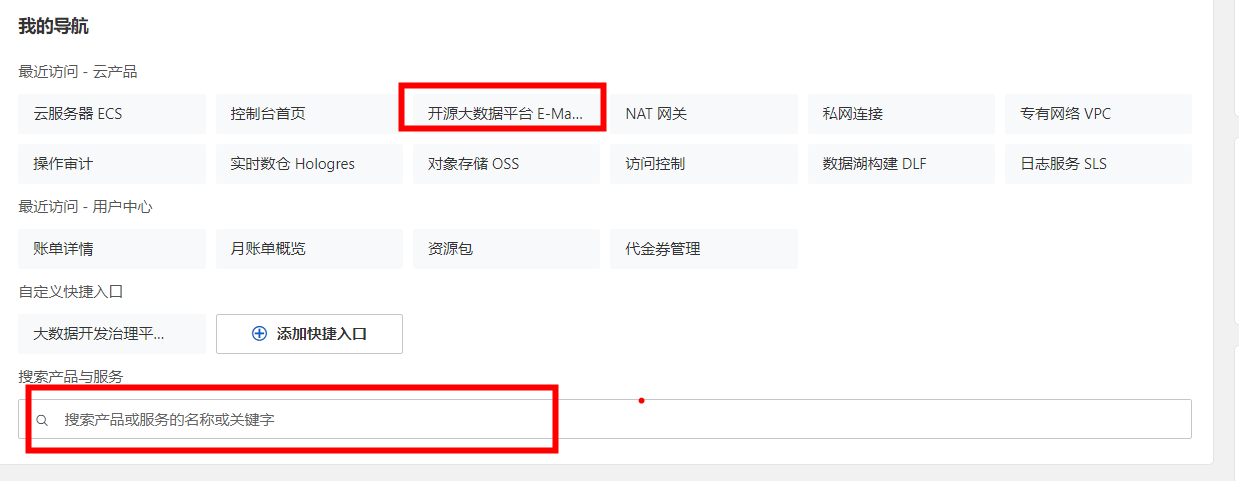
③ 进入至 E-MapReduce 首页,点击 EMR on ECS - 创建集群
-- 具体购买细节参考官方文档 https://help.aliyun.com/document_detail/176795.html#section-55q-jmm-3ts
④ 点击集群ID 可查看集群的基础信息、集群服务以及节点管理等模块
(2)登录
-- 详细登录集群方式可参考官方文档 https://help.aliyun.com/document_detail/169150.html
-- 本文以登录ECS实例操作
① 点击阿里云首页控制台 - 云服务器ECS
https://www.aliyun.com/product/ecs?spm=5176.19720258.J_3207526240.92.542b2c4aSz6c39
② 点击实例名称 - 远程连接 - Workbench远程连接
2、本地IDEA准备
(1)安装maven
-- 可参考文档 https://blog.csdn.net/l32273/article/details/123684435
(2)创建Scala项目
① 下载Scala插件
② 安装 Scala JDK
-- 建议下载 *.zip 文件
-- 配置 Scala 环境变量
-- 通过 Win + R 打开 cmd 测试是否出现 Scala版本
-- 可参考文档: https://blog.csdn.net/m0_59617823/article/details/124310663
③ 创建 Scala 项目
3、MaxCompute数据准备
(1)Project
-- MaxCompute 创建 project 可参考官方文档: https://help.aliyun.com/document_detail/27815.html
(2)AccessKey
-- 简称AK,包括AccessKey ID和AccessKey Secret,是访问阿里云API的密钥。在阿里云官网注册云账号后,可以在AccessKey管理页面生成该信息,用于标识用户,为访问MaxCompute、其他阿里云产品或连接第三方工具做签名验证。请妥善保管AccessKey Secret,必须保密,如果存在泄露风险,请及时禁用或更新AccessKey。
-- 查找 ak 可参考官方文档
https://ram.console.aliyun.com/manage/ak?spm=a2c4g.11186623.0.0.24704213IXakh3
(3)Endpoint
-- MaxCompute服务:连接地址为Endpoint,取值由地域及网络连接方式决定
-- 各地域 endpoint 可参考官方文档:https://help.aliyun.com/document_detail/34951.html
(4)table
-- MaxCompute 创建表可参考官方文档 https://help.aliyun.com/document_detail/73768.html
-- 本文需准备分区表和非分区表,供测试使用
三、代码测试
1、前提条件
(1)准备 MaxCompute 上的project、ak信息以及表数据
(2)准备 E-MapReduce集群
(3)终端连接 E-MapReduce节点(即 ECS 实例)
(4)本地 IDEA 需配置 Scala 环境变量、maven 环境变量 并下载 Scala 插件
2、代码示例
3、打包上传
(1)本地写好代码后,maven 打包
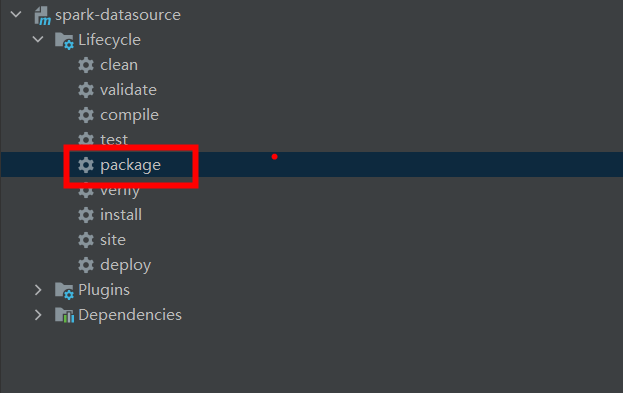
(2)本地编译jar包
① 进入project目录
cd ${project.dir}/spark-datasource-v3.1
② 执行mvn命令构建spark-datasource
mvn clean package jar:test-jar

③ 查看 target 目录下是否有 dependencies.jar 和 tests.jar
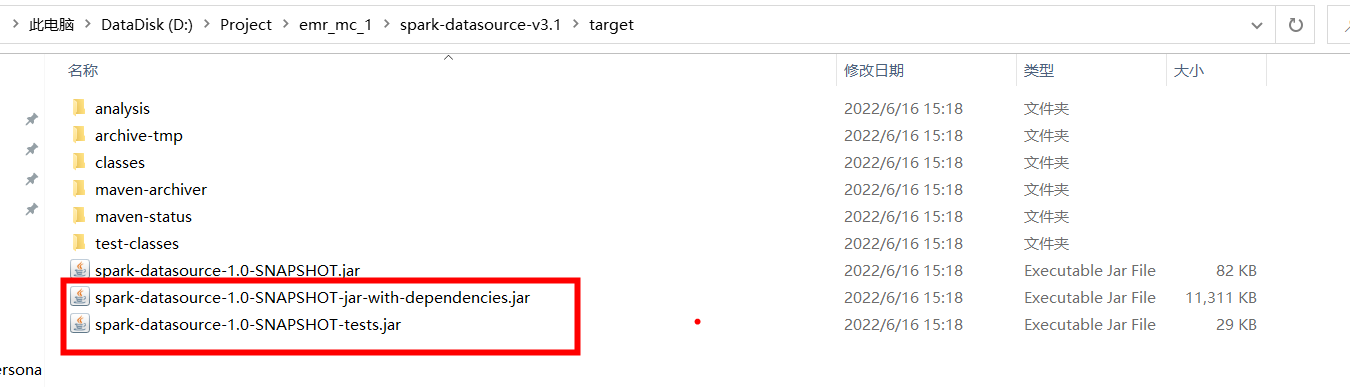
(3)打好的 jar 包上传至服务器
① scp 命令上传
scp [本地jar包路径] root@[ecs实例公网IP]:[服务器存放jar包路径]

② 服务器查看

③ 各节点之间上传 jar 包
scp -r [本服务器存放jar包路径] root@ecs实例私网IP:[接收的服务器存放jar包地址]

4、测试
(1)运行模式
① Local 模式:指定 master 参数为 local
./bin/spark-submit \
--master local \
--jars ${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-jar-with-dependencies.jar,${project.dir}/spark-datasource-v2.3/libs/cupid-table-api-1.1.5-SNAPSHOT.jar,${project.dir}/spark-datasource-v2.3/libs/table-api-tunnel-impl-1.1.5-SNAPSHOT.jar \
--class DataReaderTest \
${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-tests.jar \
${maxcompute-project-name} \
${aliyun-access-key-id} \
${aliyun-access-key-secret} \
${maxcompute-table-name}
② yarn 模式:指定master 参数为 yarn、代码中 endpoint 选择以 -inc 结尾
代码:val ODPS_ENDPOINT = "http://service.cn-beijing.maxcompute.aliyun-inc.com/api" ./bin/spark-submit \
--master yarn \
--jars ${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-jar-with-dependencies.jar,${project.dir}/spark-datasource-v2.3/libs/cupid-table-api-1.1.5-SNAPSHOT.jar,${project.dir}/spark-datasource-v2.3/libs/table-api-tunnel-impl-1.1.5-SNAPSHOT.jar \
--class DataReaderTest \
${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-tests.jar \
${maxcompute-project-name} \
${aliyun-access-key-id} \
${aliyun-access-key-secret} \
${maxcompute-table-name}
(2)读非分区表表测试
① 命令
-- 首先进入spark执行环境
cd /usr/lib/spark-current
-- 提交任务
./bin/spark-submit \
--master local \
--jars ${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-jar-with-dependencies.jar,${project.dir}/spark-datasource-v2.3/libs/cupid-table-api-1.1.5-SNAPSHOT.jar,${project.dir}/spark-datasource-v2.3/libs/table-api-tunnel-impl-1.1.5-SNAPSHOT.jar \
--class DataReaderTest \
${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-tests.jar \
${maxcompute-project-name} \
${aliyun-access-key-id} \
${aliyun-access-key-secret} \
${maxcompute-table-name}
② 执行界面

③ 执行结果

(2)读分区表测试
① 命令
-- 首先进入spark执行环境
cd /usr/lib/spark-current
-- 提交任务
./bin/spark-submit \
--master local \
--jars ${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-jar-with-dependencies.jar,${project.dir}/spark-datasource-v2.3/libs/cupid-table-api-1.1.5-SNAPSHOT.jar,${project.dir}/spark-datasource-v2.3/libs/table-api-tunnel-impl-1.1.5-SNAPSHOT.jar \
--class DataWriterTest \
${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-tests.jar \
${maxcompute-project-name} \
${aliyun-access-key-id} \
${aliyun-access-key-secret} \
${maxcompute-table-name} \
${partition-descripion}
② 执行界面

③ 执行结果

(3)写非分区表表测试
① 命令
./bin/spark-submit \
--master local \
--jars ${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-jar-with-dependencies.jar,${project.dir}/spark-datasource-v2.3/libs/cupid-table-api-1.1.5-SNAPSHOT.jar,${project.dir}/spark-datasource-v2.3/libs/table-api-tunnel-impl-1.1.5-SNAPSHOT.jar \
--class DataWriterTest \
${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-tests.jar \
${maxcompute-project-name} \
${aliyun-access-key-id} \
${aliyun-access-key-secret} \
${maxcompute-table-name}
② 执行界面

③ 执行结果
(4)写分区表测试
① 命令
./bin/spark-submit \
--master local \
--jars ${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-jar-with-dependencies.jar,${project.dir}/spark-datasource-v2.3/libs/cupid-table-api-1.1.5-SNAPSHOT.jar,${project.dir}/spark-datasource-v2.3/libs/table-api-tunnel-impl-1.1.5-SNAPSHOT.jar \
--class DataWriterTest \
${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-tests.jar \
${maxcompute-project-name} \
${aliyun-access-key-id} \
${aliyun-access-key-secret} \
${maxcompute-table-name} \
${partition-descripion}
② 执行过程

③ 执行结果

5、性能测试
-- 由于实验环境是 EMR 和 MC ,属于云上互联,如果 IDC 网络与云上相连取决于 tunnel 资源或者专线带宽
(1)大表读测试
-- size:4829258484 byte
-- partitions : 593个
-- 读取分区 20170422
-- 耗时: 0.850871 s

(2)大表写测试
① 分区写入 万条 数据
-- 耗时:2.5s

-- 结果
② 分区写入 十万条 数据
-- 耗时:8.44 s

-- 结果:
③ 分区写入 百万条 数据
-- 耗时:73.28 s

-- 结果

模拟IDC spark读写MaxCompute实践的更多相关文章
- Spark 读写hive 表
spark 读写hive表主要是通过sparkssSession 读表的时候,很简单,直接像写sql一样sparkSession.sql("select * from xx") 就 ...
- Spark读写HBase
Spark读写HBase示例 1.HBase shell查看表结构 hbase(main)::> desc 'SDAS_Person' Table SDAS_Person is ENABLED ...
- 使用Spark读写CSV格式文件(转)
原文链接:使用Spark读写CSV格式文件 CSV格式的文件也称为逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号.在本文中的CSV格 ...
- spark读写mysql
spark读写mysql除官网例子外还要指定驱动名称 travels.write .mode(SaveMode.Overwrite) .format("jdbc") .option ...
- Spark在MaxCompute的运行方式
一.Spark系统概述 左侧是原生Spark的架构图,右边Spark on MaxCompute运行在阿里云自研的Cupid的平台之上,该平台可以原生支持开源社区Yarn所支持的计算框架,如Spark ...
- Spark读写ES
本文主要介绍spark sql读写es.structured streaming写入es以及一些参数的配置 ES官方提供了对spark的支持,可以直接通过spark读写es,具体可以参考ES Spar ...
- [Big Data]从Hadoop到Spark的架构实践
摘要:本文则主要介绍TalkingData在大数据平台建设过程中,逐渐引入Spark,并且以Hadoop YARN和Spark为基础来构建移动大数据平台的过程. 当下,Spark已经在国内得到了广泛的 ...
- [转载] 从Hadoop到Spark的架构实践
转载自http://www.csdn.net/article/2015-06-08/2824889 http://www.zhihu.com/question/26568496 当下,Spark已经在 ...
- 我的Spark SQL单元测试实践
最近加入一个Spark项目,作为临时的开发人员协助进行开发工作.该项目中不存在测试的概念,开发人员按需求进行编码工作后,直接向生产系统部署,再由需求的提出者在生产系统检验程序运行结果的正确性.在这种原 ...
- 从Hadoop到Spark的架构实践
当下,Spark已经在国内得到了广泛的认可和支持:2014年,Spark Summit China在北京召开,场面火爆:同年,Spark Meetup在北京.上海.深圳和杭州四个城市举办,其中仅北京就 ...
随机推荐
- jenkins批量复制view中所有job
需要将jenkins中某一个view中的所有job都复制到另外一个view中,一个一个复制有点蛋疼,所以查询了一下资料,使用groovy scripts 来实现这个功能 新建view 打开系统管理 - ...
- python学习笔记(3):模块
模块 一个.py文件就是一个模块,模块可以包含在包(package)内.包内必须有一个__init**__**.py,包也可以多层嵌套.__init__.py也是一个模块,模块名就是包名. 当用命令行 ...
- 使用ConnectivityManager.bindProcessToNetwork绑定特殊网络
最近测试那边提了一个bug,经过排查后发现其原因:是因为连接的Wi-Fi无法上网,因此在Android系统的多网络策略中,可以上网的SIM移动网络被设置为系统默认网络,投屏组件docker传输与反控模 ...
- Ubuntu 16.04 配置NFS
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文作为本人csdn blog的主站的备份.(Bl ...
- 深入解析C#中的第三方库NPOI:Excel和Word文件处理的利器
一.引言 在.NET开发中,操作Office文档(特别是Excel和Word)是一项常见的需求.然而,在服务器端或无Microsoft Office环境的场景下,直接使用Office Interop可 ...
- drf(请求和响应)
一 请求 源码分析 from rest_framework.request import Request class Request: def __init__(self, request, pars ...
- 浅析三维模型3DTile格式轻量化处理常见问题与处理措施
浅析三维模型3DTile格式轻量化处理常见问题与处理措施 三维模型3DTile格式的轻量化处理是大规模三维地理空间数据可视化的关键环节,但在实际操作过程中,往往会遇到一些问题.下面我们来看一下这些常见 ...
- 记录--怎么实现一个3d翻书效果
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 本篇主要讨论以下两种翻书动画的实现: 第一种是整页翻转的效果: 这种整页翻转的效果主要是做rotateY的动画,并结合一些CSS的3d属性 ...
- 【Jenkins】Jenkins 运行权限问题
yum安装的Jenkins 配置文件默认位置/etc/sysconfig/jenkins 默认jenkins服务以jenkins用户运行,这时在jenkins执行maven脚本时可能会发生没有权限操作 ...
- Oracle 索引原理
B-Tree索引 一个B树索引只有一个根节点,它实际就是位于树的最顶端的分支节点. 可以用下图一来描述B树索引的结构.其中,B表示分支节点,而L表示叶子节点. 对于分支节点块(包括根节点块)来说,其所 ...