L1和L2正则化(转载)
【深度学习】L1正则化和L2正则化
在机器学习中,我们非常关心模型的预测能力,即模型在新数据上的表现,而不希望过拟合现象的的发生,我们通常使用正则化(regularization)技术来防止过拟合情况。正则化是机器学习中通过显式的控制模型复杂度来避免模型过拟合、确保泛化能力的一种有效方式。如果将模型原始的假设空间比作“天空”,那么天空飞翔的“鸟”就是模型可能收敛到的一个个最优解。在施加了模型正则化后,就好比将原假设空间(“天空”)缩小到一定的空间范围(“笼子”),这样一来,可能得到的最优解能搜索的假设空间也变得相对有限。有限空间自然对应复杂度不太高的模型,也自然对应了有限的模型表达能力。这就是“正则化有效防止模型过拟合的”一种直观解析。

L2正则化
在深度学习中,用的比较多的正则化技术是L2正则化,其形式是在原先的损失函数后边再加多一项:12λθi2" role="presentation" style="position: relative;">12λθ2i12λθi2,那加上L2正则项的损失函数就可以表示为:L(θ)=L(θ)+λ∑inθi2" role="presentation" style="position: relative;">L(θ)=L(θ)+λ∑niθ2iL(θ)=L(θ)+λ∑inθi2,其中θ" role="presentation" style="position: relative;">θθ就是网络层的待学习的参数,λ" role="presentation" style="position: relative;">λλ则控制正则项的大小,较大的取值将较大程度约束模型复杂度,反之亦然。
L2约束通常对稀疏的有尖峰的权重向量施加大的惩罚,而偏好于均匀的参数。这样的效果是鼓励神经单元利用上层的所有输入,而不是部分输入。所以L2正则项加入之后,权重的绝对值大小就会整体倾向于减少,尤其不会出现特别大的值(比如噪声),即网络偏向于学习比较小的权重。所以L2正则化在深度学习中还有个名字叫做“权重衰减”(weight decay),也有一种理解这种衰减是对权值的一种惩罚,所以有些书里把L2正则化的这一项叫做惩罚项(penalty)。
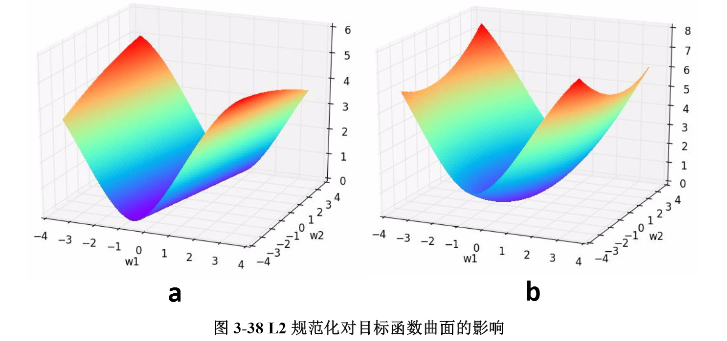
我们通过一个例子形象理解一下L2正则化的作用,考虑一个只有两个参数w1" role="presentation" style="position: relative;">w1w1和w2" role="presentation" style="position: relative;">w2w2的模型,其损失函数曲面如下图所示。从a可以看出,最小值所在是一条线,整个曲面看起来就像是一个山脊。那么这样的山脊曲面就会对应无数个参数组合,单纯使用梯度下降法难以得到确定解。但是这样的目标函数若加上一项0.1×(w12+w22)" role="presentation" style="position: relative;">0.1×(w21+w22)0.1×(w12+w22),则曲面就会变成b图的曲面,最小值所在的位置就会从一条山岭变成一个山谷了,此时我们搜索该目标函数的最小值就比先前容易了,所以L2正则化在机器学习中也叫做“岭回归”(ridge regression)。
L1正则化
L1正则化的形式是:λ|θi|" role="presentation" style="position: relative;">λ|θi|λ|θi|,与目标函数结合后的形式就是:L(θ)=L(θ)+λ∑in|θi|" role="presentation" style="position: relative;">L(θ)=L(θ)+λ∑ni|θi|L(θ)=L(θ)+λ∑in|θi|。需注意,L1 正则化除了和L2正则化一样可以约束数量级外,L1正则化还能起到使参数更加稀疏的作用,稀疏化的结果使优化后的参数一部分为0,另一部分为非零实值。非零实值的那部分参数可起到选择重要参数或特征维度的作用,同时可起到去除噪声的效果。此外,L1正则化和L2正则化可以联合使用:λ1|θi|+12λ2θi2" role="presentation" style="position: relative;">λ1|θi|+12λ2θ2iλ1|θi|+12λ2θi2。这种形式也被称为“Elastic网络正则化”。
正则化对偏导的影响
对于L2正则化:C=C0+λ2n∑iωi2" role="presentation" style="position: relative;">C=C0+λ2n∑iω2iC=C0+λ2n∑iωi2,相比于未加正则化之前,权重的偏导多了一项λnω" role="presentation" style="position: relative;">λnωλnω,偏置的偏导没变化,那么在梯度下降时ω" role="presentation" style="position: relative;">ωω的更新变为:
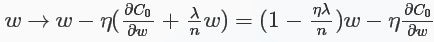
可以看出ω" role="presentation" style="position: relative;">ωω的系数使得权重下降加速,因此L2正则也称weight decay(caffe中损失层的weight_decay参数与此有关)。对于随机梯度下降(对一个mini-batch中的所有x的偏导求平均):

对于L1正则化:C=C0+λn∑i|ωi|" role="presentation" style="position: relative;">C=C0+λn∑i|ωi|C=C0+λn∑i|ωi|,梯度下降的更新为:
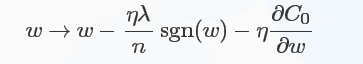
符号函数在ω" role="presentation" style="position: relative;">ωω大于0时为1,小于0时为-1,在ω=0" role="presentation" style="position: relative;">ω=0ω=0时|ω|" role="presentation" style="position: relative;">|ω||ω|没有导数,因此可令sgn(0)=0,在0处不使用L1正则化。
L1相比于L2,有所不同:
- L1减少的是一个常量,L2减少的是权重的固定比例
- 孰快孰慢取决于权重本身的大小,权重刚大时可能L2快,较小时L1快
- L1使权重稀疏,L2使权重平滑,一句话总结就是:L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0
实践中L2正则化通常优于L1正则化。







L1和L2正则化(转载)的更多相关文章
- Spark2.0机器学习系列之12: 线性回归及L1、L2正则化区别与稀疏解
概述 线性回归拟合一个因变量与一个自变量之间的线性关系y=f(x). Spark中实现了: (1)普通最小二乘法 (2)岭回归(L2正规化) (3)La ...
- L1与L2正则化
目录 过拟合 结构风险最小化原理 正则化 L2正则化 L1正则化 L1与L2正则化 参考链接 过拟合 机器学习中,如果参数过多.模型过于复杂,容易造成过拟合. 结构风险最小化原理 在经验风险最小化(训 ...
- 4.机器学习——统计学习三要素与最大似然估计、最大后验概率估计及L1、L2正则化
1.前言 之前我一直对于“最大似然估计”犯迷糊,今天在看了陶轻松.忆臻.nebulaf91等人的博客以及李航老师的<统计学习方法>后,豁然开朗,于是在此记下一些心得体会. “最大似然估计” ...
- 深入理解L1、L2正则化
过节福利,我们来深入理解下L1与L2正则化. 1 正则化的概念 正则化(Regularization) 是机器学习中对原始损失函数引入额外信息,以便防止过拟合和提高模型泛化性能的一类方法的统称.也就是 ...
- L1 与 L2 正则化
参考这篇文章: https://baijiahao.baidu.com/s?id=1621054167310242353&wfr=spider&for=pc https://blog. ...
- day-17 L1和L2正则化的tensorflow示例
机器学习中几乎都可以看到损失函数后面会添加一个额外项,常用的额外项一般有两种,一般英文称作ℓ1-norm和ℓ2-norm,中文称作L1正则化和L2正则化,或者L1范数和L2范数.L2范数也被称为权重衰 ...
- 机器学习中的L1、L2正则化
目录 1. 什么是正则化?正则化有什么作用? 1.1 什么是正则化? 1.2 正则化有什么作用? 2. L1,L2正则化? 2.1 L1.L2范数 2.2 监督学习中的L1.L2正则化 3. L1.L ...
- L1与L2正则化的对比及多角度阐述为什么正则化可以解决过拟合问题
正则化是一种回归的形式,它将系数估计(coefficient estimate)朝零的方向进行约束.调整或缩小.也就是说,正则化可以在学习过程中降低模型复杂度和不稳定程度,从而避免过拟合的危险. 一. ...
- L1、L2正则化详解
正则化是一种回归的形式,它将系数估计(coefficient estimate)朝零的方向进行约束.调整或缩小.也就是说,正则化可以在学习过程中降低模型复杂度和不稳定程度,从而避免过拟合的危险. 一. ...
- tensorflow 中的L1和L2正则化
import tensorflow as tf weights = tf.constant([[1.0, -2.0],[-3.0 , 4.0]]) >>> sess.run(tf.c ...
随机推荐
- IDEA 常用命令
1.快捷键 Alt + Enter 导入包,自动修正代码 Ctrl + Y 删除光标所在行 Ctrl + D 复制光标所在行,插入光标位置下面 Ctrl + Alt + L 格式化代码 Ctrl + ...
- vins_fusion学习笔记
Vins-Fusion源码:https://github.com/HKUST-Aerial-Robotics/VINS-Fusion 摘要 应项目需要,侧重学习stereo+gps融合 转载几篇写的比 ...
- vue 复制文本到剪切板上
1.下载clipboard.js npm install vue-clipboard2 --save 2.引入,可以在mian.js中全局引入也可以在单个vue中引入 import Clipboard ...
- DataGridView 行数据验证:当输入数据无效时不出现红色感叹号的Bug
private void dgvView_CellValidating(object sender, DataGridViewCellValidatingEventArgs e){ if ...
- WPF 时间编辑控件的实现(TimeEditer)
一.前言 有个项目需要用到时间编辑控件,在大量搜索无果后只能自己自定义一个了.MFC中倒是有这个控件,叫CDateTimeCtrl.大概是这个样子: 二.要实现的功能 要实现的功能包含: 编辑时.分. ...
- Git远程协作和分支
一.远程基本操作 基本的配置远程仓库有两个命令: git remote add origin git@github.com:ZXZxin/gitlearn.git : git push -u orig ...
- 解决:The web application [] registered the JDBC driver [] but failed to unregister it when the web application was stopped. To prevent a memory leak, the JDBC Driver has been forcibly unregistered.
问题描述 在将Spring Boot程序打包生成的war包部署到Tomcat后,启动Tomcat时总是报错,但是直接在IDEA中启动Application或者用"java -jar" ...
- webapi行程开发文档
1.新建webapi项目 2.项目中controllers 中有一个values的为webapi接口 3.areas中域中有helppage为生成文档可以直接运行localhost/help,就会生成 ...
- webpack打包js文件
当输入 webpack 输入指令 npm run dev 后会自动启动一个浏览器 需要借鉴插件 open-browser-webpack-plugin 下载:npm install open-bro ...
- JavaWeb 分层设计、MVC
M:Model,JavaBean. V:View,JSP. C:Controller,Servlet. Servlet: 接受用户请求,把请求参数封装为一个JavaBean,调用service来处理业 ...