Kafka动态增加Topic的副本
一、kafka的副本机制
由于Producer和Consumer都只会与Leader角色的分区副本相连,所以kafka需要以集群的组织形式提供主题下的消息高可用。kafka支持主备复制,所以消息具备高可用和持久性。
一个分区可以有多个副本,这些副本保存在不同的broker上。每个分区的副本中都会有一个作为Leader。当一个broker失败时,Leader在这台broker上的分区都会变得不可用,kafka会自动移除Leader,再其他副本中选一个作为新的Leader。
在通常情况下,增加分区可以提供kafka集群的吞吐量。然而,也应该意识到集群的总分区数或是单台服务器上的分区数过多,会增加不可用及延迟的风险。
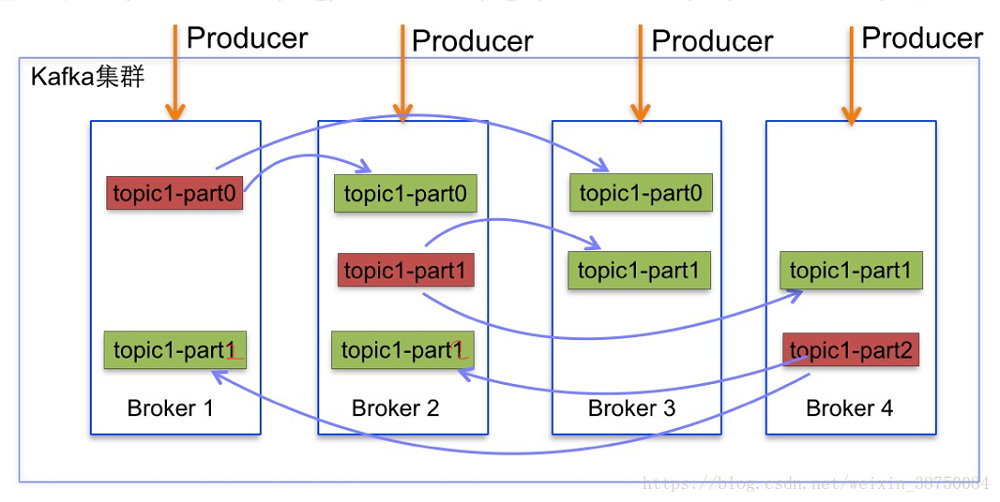
关于副本的更多信息,请参考链接:
https://blog.csdn.net/weixin_38750084/article/details/82942564
二、概述
目前的kakfa集群有3个节点,server.properties 关于topic的配置为:
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
目前的设置为1个副本,这样不健全。如果有一台服务器挂掉了,那么就会造成数据丢失!
因此,需要将副本数改为3,也就是每台服务器都有一个副本,这样才是稳妥的!
三、动态扩容
kafka-topics.sh 不能用来增加副本因子replication-factor。实际应该使用kafka bin目录下面的kafka-reassign-partitions.sh
查看topic详情
首先查看kafka的所有topic
/kafka/bin/kafka-topics.sh --zookeeper zookeeper-1.default.svc.cluster.local:2181 --list
输出:
test
...
查看topic为test的详细信息
/kafka/bin/kafka-topics.sh --describe --zookeeper zookeeper-1.default.svc.cluster.local:2181 --topic test
输出:
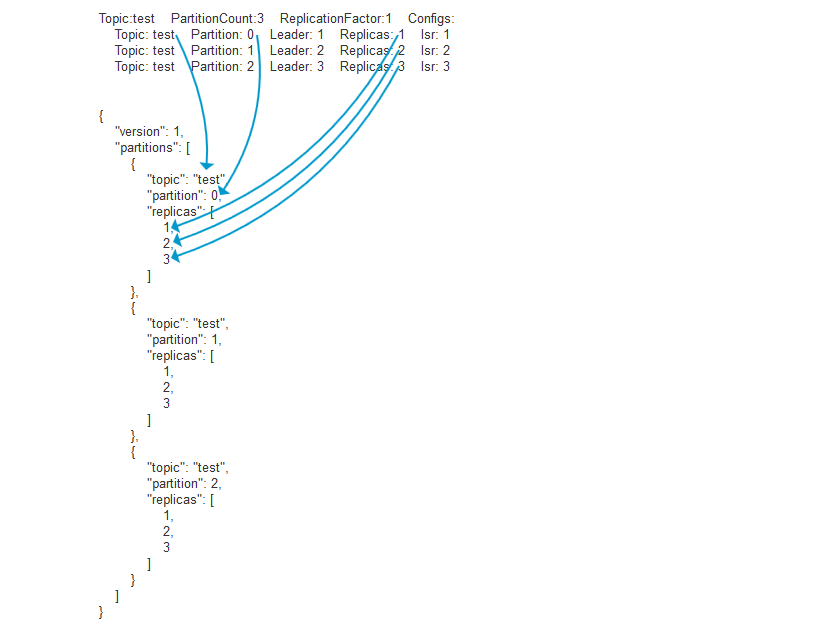
Topic:test PartitionCount:3 ReplicationFactor:1 Configs:
Topic: test Partition: 0 Leader: 1 Replicas: 1 Isr: 1
Topic: test Partition: 1 Leader: 2 Replicas: 2 Isr: 2
Topic: test Partition: 2 Leader: 3 Replicas: 3 Isr: 3
可以看到test的副本数为1
扩容副本
kafka-reassign-partitions.sh 执行时,依赖一个json文件。
创建 test.json
{
"version": 1,
"partitions": [
{
"topic": "test",
"partition": 0,
"replicas": [
1,
2,
3
]
},
{
"topic": "test",
"partition": 1,
"replicas": [
1,
2,
3
]
},
{
"topic": "test",
"partition": 2,
"replicas": [
1,
2,
3
]
}
]
}
注意:这个json文件和上面查看的test详情,是有关联的!否则会导致执行失败
关系图
正式执行脚本
/kafka/bin/kafka-reassign-partitions.sh --zookeeper zookeeper-1.default.svc.cluster.local:2181 --reassignment-json-file test.json --execute
参数解释:
--reassignment-json-file 带有分区的JSON文件
--execute 按规定启动重新分配通过---重新分配JSON文件选择权。
执行输出:
Current partition replica assignment
{"version":1,"partitions":[{"topic":"test","partition":2,"replicas":[1],"log_dirs":["any"]},{"topic":"test","partition":1,"replicas":[3],"log_dirs":["any"]},{"topic":"test","partition":0,"replicas":[2],"log_dirs":["any"]}]}
出现 Successfully 表示成功了!
再次查看topic为test的partition详情
/kafka/bin/kafka-topics.sh --describe --zookeeper zookeeper-1.default.svc.cluster.local:2181 --topic test
输出:
Topic:test PartitionCount:3 ReplicationFactor:3 Configs:
Topic: test Partition: 0 Leader: 2 Replicas: 1,2,3 Isr: 2,3,1
Topic: test Partition: 1 Leader: 3 Replicas: 1,2,3 Isr: 3,1,2
Topic: test Partition: 2 Leader: 1 Replicas: 1,2,3 Isr: 1,3,2
可以发现,副本已经改为3了!
默认配置
在java代码或者python代码中,是直接发送生产者消息。topic的名字是动态生成的(当kafka发现topic不存在时,会自动创建),那么它的partitions和replication-factor的数量是由服务端决定的
因为kafka集群有3个节点,所有需要改成3个
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=3
num.partitions=1
default.replication.factor=3
参数解释:
offsets.topic.replication.factor 用于配置offset记录的topic的partition的副本个数
transaction.state.log.replication.factor 事务主题的复制因子
transaction.state.log.min.isr 覆盖事务主题的min.insync.replicas配置
num.partitions 新建Topic时默认的分区数
default.replication.factor 自动创建topic时的默认副本的个数
注意:这些参数,设置得更高以确保高可用性!
其中 default.replication.factor 是真正决定,topi的副本数量的
关于kafka配置文件的更多解释,请参考链接:
https://blog.csdn.net/memoordit/article/details/78850086
那么默认参数,如何测试呢?
很简单,由于在应用代码,是不会主动创建topic的,由kafka集群自动创建topic。
那么由代码进行一次,生产者和消费者,就可以了!
Python测试
这个脚本是普通版的kafka消息测试,没有ACL配置!
test.py
#!/usr/bin/env python3
# coding: utf-8
import sys
import io def setup_io(): # 设置默认屏幕输出为utf-8编码
sys.stdout = sys.__stdout__ = io.TextIOWrapper(sys.stdout.detach(), encoding='utf-8', line_buffering=True)
sys.stderr = sys.__stderr__ = io.TextIOWrapper(sys.stderr.detach(), encoding='utf-8', line_buffering=True)
setup_io() import time
from kafka import KafkaProducer
from kafka import KafkaConsumer class KafkaClient(object):
def __init__(self, kafka_server, port, topic, content):
self.kafka_server = kafka_server # kafka服务器ip地址
self.port = port # kafka端口
self.topic = topic # topic名
self.content = content # 内容 def producer(self):
producer = KafkaProducer(bootstrap_servers=['%s:%s' % (kafka_server, port)])
producer.send(topic, content)
producer.flush() # flush确保所有meg都传送给broker
producer.close()
return producer def consumer(self):
consumer = KafkaConsumer(topic, group_id='test_group', bootstrap_servers=['%s:%s' % (kafka_server, port)])
# consumer.close()
return consumer def main(self):
startime = time.time() # 开始时间 client = KafkaClient(self.kafka_server, self.port, self.topic, self.content) # 实例化客户端 client.producer() # 执行生产者
print("已执行生产者")
consumer = client.consumer() # 执行消费者
print("已执行消费者")
print("等待结果输出...")
flag = False
for msg in consumer:
# recv = "%s:%d:%d: key=%s value=%s" % (msg.topic, msg.partition, msg.offset, msg.key, msg.value)
# 判断生产的消息和消费的消息是否一致
print(msg.value)
# print(self.content)
if msg.value == self.content:
flag = True
break consumer.close() # 关闭消费者对象
endtime = time.time() # 结束时间 if flag:
# %.2f %(xx) 表示保留小数点2位
return "kafka验证消息成功,花费时间", '%.2f 秒' % (endtime - startime)
else:
return "kafka验证消息失败,花费时间", '%.2f 秒' % (endtime - startime) if __name__ == '__main__':
kafka_server = "kafka-1.default.svc.cluster.local"
port = ""
topic = "test_xxx"
content = "hello honey".encode('utf-8') client = KafkaClient(kafka_server,port,topic,content) # 实例化客户端
print(client.main())
这里指定的topic为 test_xxx
执行Python脚本,然后到服务器上面,查看topic为test_xxx的详细信息
/kafka/bin/kafka-topics.sh --describe --zookeeper zookeeper-1.default.svc.cluster.local:2181 --topic test_xxx
输出如下:
Topic:test_xxx PartitionCount:3 ReplicationFactor:3 Configs:
Topic: test_xxx Partition: 0 Leader: 2 Replicas: 1,2,3 Isr: 2,3,1
Topic: test_xxx Partition: 1 Leader: 3 Replicas: 1,2,3 Isr: 3,1,2
Topic: test_xxx Partition: 2 Leader: 1 Replicas: 1,2,3 Isr: 1,3,2
可以发现副本为3,说明默认配置生效了!
Kafka动态增加Topic的副本的更多相关文章
- (二)Kafka动态增加Topic的副本(Replication)
(二)Kafka动态增加Topic的副本(Replication) 1. 查看topic的原来的副本分布 [hadoop@sdf-nimbus-perf ~]$ le-kafka-topics.sh ...
- 一脸懵逼学习Hdfs---动态增加节点和副本数量管理(Hdfs动态扩容)
1:按照上篇博客写的,将各个进程都启动起来: 集群规划: 主机名 IP 安装的软件 运行的进程 master ...
- 5 weekend01、02、03、04、05、06、07的分布式集群的HA测试 + hdfs--动态增加节点和副本数量管理 + HA的java api访问要点
weekend01.02.03.04.05.06.07的分布式集群的HA测试 1) weekend01.02的hdfs的HA测试 2) weekend03.04的yarn的HA测试 1) wee ...
- 如何使用kafka增加topic的备份数量,让业务更上一层楼
本文由云+社区发表 一.困难点 建立topic的时候,可以通过指定参数 --replication-factor 设置备份数量.但是,一旦完成建立topic,则无法通过kafka-topic.sh 或 ...
- Kafka Java consumer动态修改topic订阅
前段时间在Kafka QQ群中有人问及此事——关于Java consumer如何动态修改topic订阅的问题.仔细一想才发现这的确是个好问题,因为如果简单地在另一个线程中直接持有consumer实例然 ...
- Kafka动态配置实现原理解析
问题导读 Apache Kafka在全球各个领域各大公司获得广泛使用,得益于它强大的功能和不断完善的生态.其中Kafka动态配置是一个比较高频好用的功能,下面我们就来一探究竟. 动态配置是如何设计的? ...
- kafka 日常使用和数据副本模型的理解
kafka 日常使用和数据副本模型的理解 在使用Kafka过程中,有时经常需要查看一些消费者的情况.Kafka健康状况.临时查看.同步一些数据,又由于Kafka只是用来做流式存储,又没有像Mysql或 ...
- kafka之partition分区及副本replica升级
修改kafka的partition分区 bin/kafka-topics.sh --zookeeper datacollect-2:2181 --alter --partitions 3 --topi ...
- hdfs以及hbase动态增加和删除节点
一个知乎上的问题:Hbase的Region server和hadoop的datanode是否可以部署在一台服务器上?如果是的话,二者是否是一对一的关系?部署在同一台服务器上,可以减少数据跨网络传输的流 ...
随机推荐
- NET 4 中 内存映射文件
原文链接 : http://blogs.msdn.com/salvapatuel/archive/2009/06/08/working-with-memory-mapped-files-in-net- ...
- CodeBlock 快捷键大全
一款开源的C/C++ IDE(集成开发环境),基于wxWidgets GUI体系,跨平台支持. 编辑器 快捷键 功能 Ctrl+Z 恢复上一次操作 Ctrl+Shift+Z 重复上一次操作 F1 ...
- ActiveMQ进阶配置
配置web管理页面的安全认证 配置web管理页面的绑定IP和端口 配置MQ连接的安全认证 禁用不使用的连接协议 绑定协议连接端口到指定IP 使用MySql作为持久化保存 配置基于JDBC的高可用环境 ...
- .Net进阶系列(15)-异步多线程(线程的特殊处理和深究委托赋值)(被替换)
1. 线程的异常处理 我们经常会遇到一个场景,开启了多个线程,其中一个线程报错,导致整个程序崩溃.这并不是我们想要的,我需要的结果是,其中一个线程报错,默默的记录下,其它线程正常进行,保证程序整体可以 ...
- STM32固件库下载地址
http://www.stmcu.org/document/list/index/sort-hot/category-517找标准外设库命名的资源
- Swift下使用Xib设计界面
虽然Swift可以纯代码设计界面,不过不利用现有的可视化工具有时候有点效率低.下面是使用xib设计方法,部分代码来自网上. (1)新建View 2.新建View class 3.DemoView.sw ...
- Sqoop异常:Exception in thread "main" java.lang.NoClassDefFoundError: org/json/JSONObject
18/12/07 01:09:03 INFO mapreduce.ImportJobBase: Beginning import of staffException in thread "m ...
- chrome面板介绍
Chrome开发者工具详解(1):Elements.Console.Sources面板 Chrome 开发者工具详解(2):Network 面板 Chrome开发者工具详解(3):Timeline面板 ...
- 【转贴】Linux下MySQL 5.5的修改字符集编码为UTF8(彻底解决中文乱码问题)
原文地址; http://www.ha97.com/5359.html PS:昨天一同事遇到mysql 5.5中文乱码问题,找我解决.解决了,有个细节问题网上没人说,我就总结一下. 一.登录MySQL ...
- media属性
media=“screen”是什么意思?? media 属性规定目标 URL 是为什么类型的媒介/设备进行优化的. 该属性用于规定目标 URL 是为特殊设备(比如 iPhone).语音或打印媒介设计的 ...