035 HDFS的联盟Federation
一:概述
1.单个namenode的局限性
namespace的限制
单个namenode所能存储的对象受到JVM中的heap size的限制
namenode的扩张性
不可以水平扩张
隔离性
单个namenode难以提供隔离性,各自管理自己的数据,只是共享一个存储领域。
截图:

2.好处(可以与HA兼容)
各自管理各自的数据
共享数据空间

二:配置hdfs-site.xml
1.配置
配置三台namenode,但是这里只有第一台的配置,将下面的配置再拷贝两份,修改成对应的namenode的机器。
8022,可以减缓端口号的压力。

2.分发
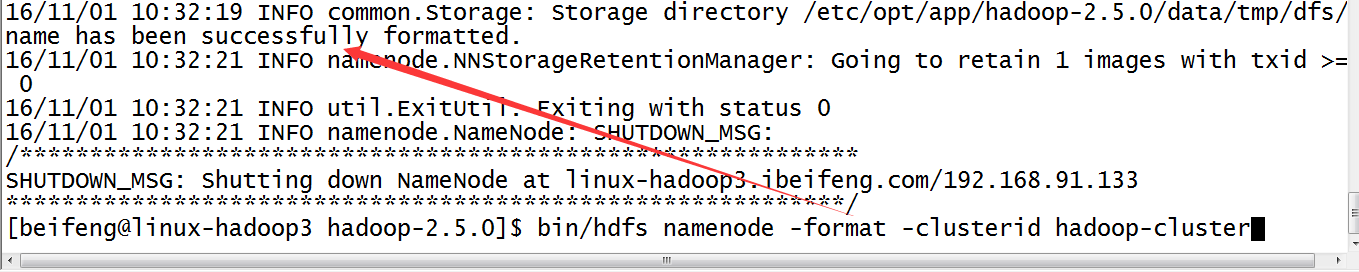
3.格式化namenodes
$HADOOP_PREFIX_HOME/bin/hdfs namenode -format [-clusterId <cluster_id>]
需要格式化三台namenode。
需要有相同的集群名,就是上面的<cluster_id>,就是说namenode所在的机器的格式化语句都是相同的。
4.启动集群
三台机器都可以启动namenode与datanode。
会发现三台机器都是active。
三:观察效果
证明,各个namenode互不影响
1.测试一
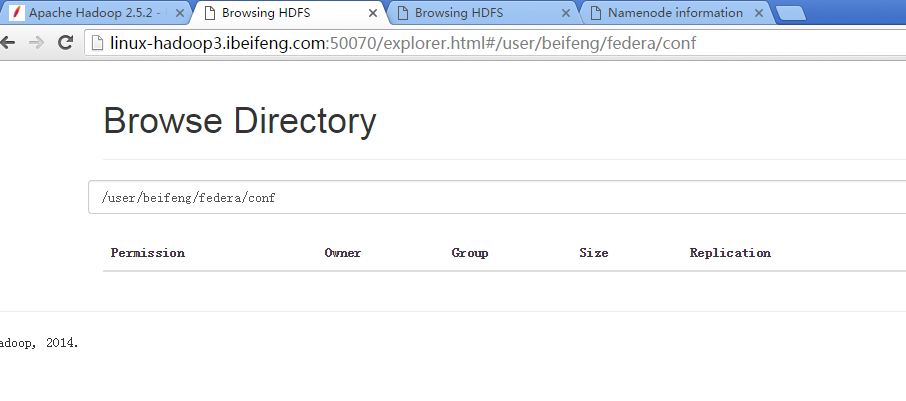
2.在第一台虚拟机上新建目录
会在第一台上看见这个目录,但是在第二台虚拟机上看不到这个目录。
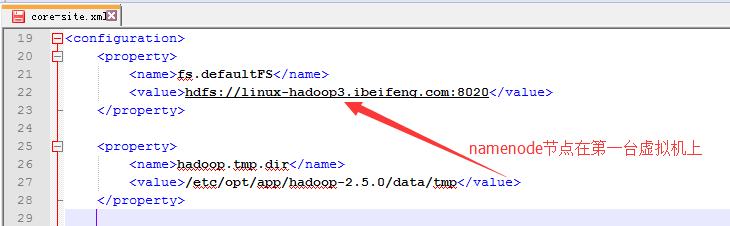
3.然后,修改core

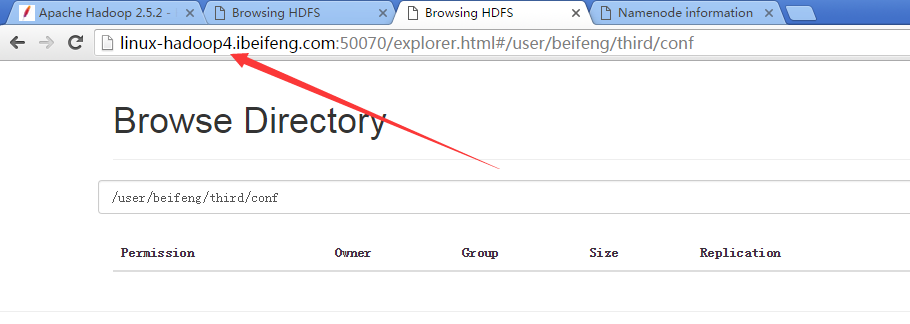
4.在第一台虚拟机上新建目录
但是因为配置文件改成第二台虚拟机,所以,第二台上可以看见被修改了。
5.结论
说名上面的操作结论。
现在只是修改第一台机器的core,以及操作第一台机器。
但是在页面上的结果变化需要到core文件中修改的对应的机器上观看datanode的文件变化情况。
说明,第一台机器可以随意操作集群中想要操作的那个datanode。
同理,第二台上可以通过配置core中的namenode所在主机,进行修改对应的datanode。
所以,这样就完成了想要的结果。
每个namenode都可以操作不同的datanode。
四:结论
不管操作的是哪台虚拟机,core中的namenode定义的哪台虚拟机,新建的HDFS就属于哪个namenode管理。
035 HDFS的联盟Federation的更多相关文章
- HDFS的联盟Federation
一:概述 1.单个namenode的局限性 namespace的限制 单个namenode所能存储的对象受到JVM中的heap size的限制 namenode的扩张性 不可以水平扩张 隔离性 单个n ...
- Hadoop2.2.0--Hadoop Federation、Automatic HA、Yarn完全分布式集群结构
Hadoop有很多的上场时间,与系统上线.手头的事情略少.So,抓紧时间去通过一遍Hadoop2在下面Hadoop联盟(Federation).Hadoop2可用性(HA)及Yarn的全然分布式配置. ...
- Hadoop 5、HDFS HA 和 YARN
Hadoop 2.0 产生的背景Hadoop 1.0 中HDFS和MapReduce存在高可用和扩展方面的问题 HDFS存在的问题 NameNode单点故障,难以用于在线场景 NameNode压力过大 ...
- [转]HDFS HA 部署安装
1. HDFS 2.0 基本概念 相比于 Hadoop 1.0,Hadoop 2.0 中的 HDFS 增加了两个重大特性,HA 和 Federaion.HA 即为 High Availability, ...
- 带您详细解读分布式文件系统HDFS
一.HDFS的由来: 本地系统:一个节点作为系统,以前数据是存放在本地文件系统上的,但本地文件系统存在两个问题:1.本地节点存储容量不够大:2.本地节点会坏,数据不够安全.这时,人们开始利用闲置的计算 ...
- HDFS原理解析
一.HDFS简介 HDFS为了做到可靠性(reliability)创建了多分数据块(data blocks)的复制(replicas),并将它们放置在服务器群的计算节点中(computer nodes ...
- hadoop权威指南(第四版)要点翻译(4)——Chapter 3. The HDFS(1-4)
Filesystems that manage the storage across a network of machines are called distributed filesystems. ...
- 大数据基础总结---HDFS分布式文件系统
HDFS分布式文件系统 文件系统的基本概述 文件系统定义:文件系统是一种存储和组织计算机数据的方法,它使得对其访问和查找变得容易. 文件名:在文件系统中,文件名是用于定位存储位置. 元数据(Metad ...
- hdfs架构详解(防脑裂fencing机制值得学习)
HDFS(Hadoop Distributed File System)是一个分布式文件存储系统,几乎是离线存储领域的标准解决方案(有能力自研的大厂列外),业内应用非常广泛.近段抽时间,看一下 HDF ...
随机推荐
- 字体选择框QFontComboBox
self.combobox_2 = QFontComboBox(self) # 实例化字体列表框 combobox.currentFont() 返回字体选择框中当前的字体 self.combobo ...
- resolution will not be reattempted until the update interval of repository-group has elapsed or updates are forced
Failed to execute goal on project safetan-web: Could not resolve dependencies for project com.safeta ...
- Python 入门基础19 --面向对象、封装
2019.04.17 一.面向对象与面向过程 二.名称空间操作 三.类与对象的概念 四.语法 五.对象查找属性的顺序 2019.04.18 1.类与对象的所有概念:__init__方法 2.类的方法与 ...
- java 两个list 交集 并集 差集 去重复并集
前提需要明白List是引用类型,引用类型采用引用传递. 我们经常会遇到一些需求求集合的交集.差集.并集.例如下面两个集合: List<String> list1 = new ArrayLi ...
- Oracle 正则表达式函数-REGEXP_REPLACE
背景 当初写oracle的一个存储过程,以前不知道sql里也有正则表达式,关于正则表达式教程很多了,这里只是记录下Oracle也有这个功能,下次再有类似需求用这个处理的确方便很多. 想起存储过程,就想 ...
- VMware环境和Window环境进行网络连接的问题
一. 首先贴出本人在网络上找到与VMware网络连接相关的知识点 安装完虚拟机后,默认安装了两个虚拟网卡,VMnet1和VMnet8,其他的未安装(当然也可以手动安装其他的).其中VMnet1是hos ...
- Android软件更新
Android软件更新 //得到当前版本编码和版本名称. public static int getVerCode(Context context) { ; try { verCode =).vers ...
- canvas图像裁剪、压缩、旋转
转载于:http://www.cnblogs.com/dailc/p/7843204.html 前言 前段时间遇到了一个移动端对图像进行裁剪.压缩.旋转的需求.考虑到已有各轮子的契合度都不高,于是自己 ...
- 解读使用Daisy-chain(菊花链)方式筛选一定范围内素数的代码
go version go1.11 windows/amd64 本文为解读 参考链接1 中的 菊花链 一节 的示例程序,此程序和 参考链接2 中代码有些类似:前者有范围,后者是无限循环.清楚了 参考链 ...
- SQL Server 触发器demo
GO /****** Object: Trigger [dbo].[tri_device] Script Date: 2018/6/11 10:56:08 ******/ SET ANSI_NUL ...