hadoopMR自定义输入格式
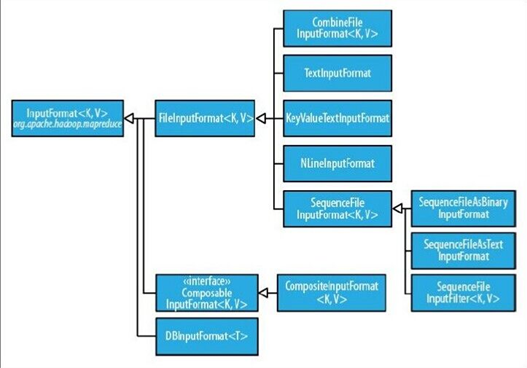
输入格式
1、输入分片与记录
2、文件输入
3、文本输入
4、二进制输入
5、多文件输入
6、数据库格式输入
详细的介绍:https://blog.csdn.net/py_123456/article/details/79766573
1、输入分片与记录
1、JobClient通过指定的输入文件的格式来生成数据分片InputSplit。
2、一个分片不是数据本身,而是可分片数据的引用。
3、InputFormat接口负责生成分片。
InputFormat 负责处理MR的输入部分,有三个作用:
验证作业的输入是否规范。
把输入文件切分成InputSplit。
提供RecordReader 的实现类,把InputSplit读到Mapper中进行处理。
2、文件输入
抽象类:FilelnputFormat
1、FilelnputFormat是所有使用文件作为数据源的InputFormat实现的基类。
2、FilelnputFormat输入数据格式的分片大小由数据块大小决定。
FileInputFormat保存作为job输入的所有文件,并实现了对输入文件计算splits的方法。至于获得记录的方法是有不同的子类如TextInputFormat进行实现的。
3.文本输入
| TextInputFormat: | 默认的输入方式,key是该行的字节偏移量,value是该行的内容<LongWritable,Text> |
| KeyValueTextInputFormat |
job.getConfiguration().setStrings(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, ":");//默认的分隔符‘\t’,可以设置分割符,分割之后以分割符前的作为key,分隔符后的作为vallue 如果不设置分隔符则key为一整行内容,value为空<Text,Text> |
| NlineInputFormat |
NLineInputFormat.setNumLinesPerSplit(job, 3);// 设置每次读3行内容为mapper输入<Text,IntWritable>,key和value与TestInputFormat一样 |
4、二进制输入
SequenceFileInputFormat 将key和value以sequencefile格式输入。<Text,IntWritable>
先使用二进制输出格式输出一个二进制文件再作为输入文件
5.多文件输入
在一个MapReduce作业中所有的文件由一个mapper来处理不能满足不同文件格式需求,可以指定不同的文件由不同的mapper来处理,然后输出一样的类型给reduce
like:
MultipleInputs.addInputPath(job,OneInputpath,TextInputFormat.class,OneMapper.class)
MultipleInputs.addInputPath(job,TowInputpath,TextInputFormat.class,TowMapper.class)
(addInputPath()只能指定一个路径,如果要想添加多个路径需要多次调用该方法:)
2、通过addInputPaths()方法来设置多路径,多条路径用分号(;)隔开
String paths = strings[0] + "," + strings[1];
FileInputFormat.addInputPaths(job, paths);
6。数据库输入:DBInputFormat
用于使用JDBC从关系数据库中读取数据,DBOutputFormat用于输出数据到数据库,适用于加载少量的数据集
(DBInputFormat map的输入(Longwriatble,Dbwritable的实现类)
自定义输入格式要点:
1自定义一个MyRecordReader类继承抽象类:RecordReader,
每一个数据格式都需要有一个recordreader,主要用于将文件中的数据拆分层具体的键值对,Textinputformat中默认的recordreader值linerecordreader
2自定义inputFormat继承Fileinputformat类,重写inputformat中的cretaeRecordReader()方法,返回自定义的MyRecordReader类
3.job.setInputformatclass(自定义的Inputformat.class)
代码:
package com.neworigin.RecordReaderDemo;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.input.KeyValueLineRecordReader;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.LineReader;
public class MyRecordReader {
static Path in=new Path("file:///F:/安装/java工程/RecordReaderDemo/data/in/test.txt");
static Path out=new Path("file:///F:/安装/java工程/RecordReaderDemo/data/out");
//自定义Recordreader
public static class DefReadcordReader extends RecordReader<LongWritable ,Text>{
private long start;
private long end;
private long pos;
private FSDataInputStream fin=null;
private LongWritable key=null;
private Text value=null;
private LineReader reader=null;
@Override
public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
FileSplit filesplit=(FileSplit)split;
//
start=filesplit.getStart();
end=filesplit.getLength()+start;
//
Path path = filesplit.getPath();
Configuration conf = new Configuration();
//Configuration conf = context.getConfiguration();
FileSystem fs=path.getFileSystem(conf);
fin=fs.open(path);
reader=new LineReader(fin);
pos=1;
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
int kkk = reader.readLine(value);//获取当前行内容的偏移量
System.out.println(kkk);
if(key==null)
{
key=new LongWritable();
}
key.set(pos);
if(value==null)
{
value=new Text();
}
// value.set(pos);
if(reader.readLine(value)==0)
{
return false;
}
pos++;
return true;
}
@Override
public LongWritable getCurrentKey() throws IOException, InterruptedException {
// TODO Auto-generated method stub
return key;
}
@Override
public Text getCurrentValue() throws IOException, InterruptedException {
// TODO Auto-generated method stub
return value;
}
@Override
public float getProgress() throws IOException, InterruptedException {
// TODO Auto-generated method stub
return 0;
}
@Override
public void close() throws IOException {
// TODO Auto-generated method stub
if(fin!=null)
{
fin.close();
}
}
}
//自定义输入格式
public static class MyFileInputFormat extends FileInputFormat<LongWritable,Text>{
@Override
public RecordReader<LongWritable, Text> createRecordReader(InputSplit split, TaskAttemptContext context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
DefReadcordReader reader = new DefReadcordReader();//返回自定义的recordReader类
return reader;
}
@Override
protected boolean isSplitable(JobContext context, Path filename) {
// TODO Auto-generated method stub
return false;
}
}
public static class MyMapper extends Mapper<LongWritable,Text,LongWritable,Text>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, LongWritable, Text>.Context context)
throws IOException, InterruptedException {
context.write(key,value);
}
}
//根据奇偶数行来分区
public static class MyPartition extends Partitioner<LongWritable,Text>{
@Override
public int getPartition(LongWritable key, Text value, int numPartitions) {
if(key.get()%2==0)
{
key.set(1);
return 1;
}
else
{
key.set(0);
return 0;
}
}
}
public static class MyReducer extends Reducer<LongWritable,Text,Text,IntWritable>{
@Override
protected void reduce(LongWritable key, Iterable<Text> values,
Reducer<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
Text write_key=new Text();
IntWritable write_value=new IntWritable();
int sum=0;
for (Text value:values)
{
sum+=Integer.parseInt(value.toString());
}
if(key.get()==0)
{
write_key.set("奇数行之和");
}
else
{
write_key.set("偶数行之和");
}
write_value.set(sum);
context.write(write_key, write_value);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
FileSystem fs=FileSystem.get(conf);
if(fs.exists(out))
{
fs.delete(out);
}
Job job = Job.getInstance(conf,"MyRedordReader");
job.setJarByClass(MyRecordReader.class);//打包运行时需哟啊
FileInputFormat.addInputPath(job, in);
job.setInputFormatClass(MyFileInputFormat.class);
//job.setInputFormatClass(KeyValueTextInputFormat.class);
//conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, " ");
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setPartitionerClass(MyPartition.class);
job.setReducerClass(MyReducer.class);
job.setNumReduceTasks(2);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileOutputFormat.setOutputPath(job, out);
//TextInputFormat
System.exit(job.waitForCompletion(true)?0:1);
}
}
hadoopMR自定义输入格式的更多相关文章
- MapReduce实战:自定义输入格式实现成绩管理
1. 项目需求 我们取有一份学生五门课程的期末考试成绩数据,现在我们希望统计每个学生的总成绩和平均成绩. 样本数据如下所示,每行数据的数据格式为:学号.姓名.语文成绩.数学成绩.英语成绩.物理成绩.化 ...
- hadoopMR自定义输入类型
hadoop中的输入输出数据类型: BooleanWritable:标准布尔型数值 ByteWritable:单字节数值 DoubleWritable:双字节数值 FloatWritable:浮点数 ...
- Hadoop MapReduce编程 API入门系列之自定义多种输入格式数据类型和排序多种输出格式(十一)
推荐 MapReduce分析明星微博数据 http://git.oschina.net/ljc520313/codeexample/tree/master/bigdata/hadoop/mapredu ...
- MapReduce输入格式
文件是 MapReduce 任务数据的初始存储地.正常情况下,输入文件一般是存储在 HDFS 里面.这些文件的格式可以是任意的:我们可以使用基于行的日志文件, 也可以使用二进制格式,多行输入记录或者其 ...
- MapReduce的输入格式
1. InputFormat接口 InputFormat接口包含了两个抽象方法:getSplits()和creatRecordReader().InputFormat决定了Hadoop如何对文件进行分 ...
- Hadoop MapReduce编程 API入门系列之MapReduce多种输入格式(十七)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.ScoreCount; import java.io.DataInput; import java.i ...
- Hadoop(七):自定义输入输出格式
MR输入格式概述 数据输入格式 InputFormat. 用于描述MR作业的数据输入规范. 输入格式在MR框架中的作用: 文件进行分块(split),1个块就是1个Mapper任务. 从输入分块中将数 ...
- hadoop编程小技巧(5)---自定义输入文件格式类InputFormat
Hadoop代码测试环境:Hadoop2.4 应用:在对数据需要进行一定条件的过滤和简单处理的时候可以使用自定义输入文件格式类. Hadoop内置的输入文件格式类有: 1)FileInputForma ...
- ELK收集Nginx自定义日志格式输出
1.ELK收集日志的有两种常用的方式: 1.1:不修改源日志格式,简单的说就是在logstash中转通过 grok方式进行过滤处理,将原始无规则的日志转换为规则日志(Logstash自定义日志格式) ...
随机推荐
- Ubuntu fcitx CPU占用率很高解决方法
在Ubuntu中,有时候电脑的风扇突然狂装,用 pidstat -u 5 1 命令查看后台应用的资源占用情况,发现fcitx的占用率接近百分之百. 原因是搜狗云输入的问题,关闭后,在用kill命令干掉 ...
- position relative top失效的问题,温习下常用两种的居中方式
因为body和html,默认高度是auto 所以相对于他们作为父元素设置position:relative的top值需要加上body,html{height:100%;} <!DOCTYPE h ...
- Derek解读Bytom源码-创世区块
作者:Derek 简介 Github地址:https://github.com/Bytom/bytom Gitee地址:https://gitee.com/BytomBlockchain/bytom ...
- _map
地图属性控制表 comment 备注 Map 地图ID,.gps第一个参数 Zone 区域ID,.gps第二个参数,整个地图时填0 Area 地域ID,.gps第三个参数,整个地图或区域时填0 Cha ...
- P1230 智力大冲浪
题目描述 小伟报名参加中央电视台的智力大冲浪节目.本次挑战赛吸引了众多参赛者,主持人为了表彰大家的勇气,先奖励每个参赛者m元.先不要太高兴!因为这些钱还不一定都是你的?!接下来主持人宣布了比赛规则: ...
- MAC office2016 安装及激活
Office 下载地址: http://www.xitongtiandi.net/soft_yy/4285.html 破解补丁下载地址: https://bbs.feng.com/tencentdow ...
- centos7安装tomcat8 新手入门 图文教程
系统环境 操作系统:64位CentOS Linux release 7.2.1511 (Core) JDK版本:1.8.0_121 下载tomcat8压缩包 访问官网:http://tomcat.ap ...
- java 二维数组的行列长度
在 java 中,其实只有一维数组,而二维数组是在一维数组中嵌套实现的.比如 int[][] a = {{},{},{},{}} 要取行数和某一行的列数可以 : int rowLen = a.leng ...
- CentOS 7系统安装配置图解教程
操作系统:CentOS 7.3 备注: CentOS 7.x系列只有64位系统,没有32位.生产服务器建议安装CentOS-7-x86_64-Minimal-1611.iso版本 一.安装CentOS ...
- webpack踩坑之路 (2)——图片的路径与打包
刚开始用webpack的同学很容易掉进图片打包这个坑里,比如打包出来的图片地址不对或者有的图片并不能打包进我们的目标文件夹里(bundle).下面我们就来分析下在webpack项目中图片的应用场景. ...