Eclipse环境搭建并且运行wordcount程序
一、安装Hadoop插件
1. 所需环境
hadoop2.0伪分布式环境平台正常运行
所需压缩包:eclipse-jee-luna-SR2-linux-gtk-x86_64.tar.gz
在Linux环境下运行的eclipse软件压缩包,解压后文件名为eclipse
hadoop2x-eclipse-plugin-master.zip
在eclipse中需要安装的Hadoop插件,解压后文件名为hadoop2x-eclipse-plugin-master
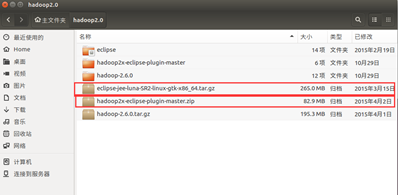
如图所示,将所有的压缩包放在同一个文件夹下并解压。
2.编译jar包
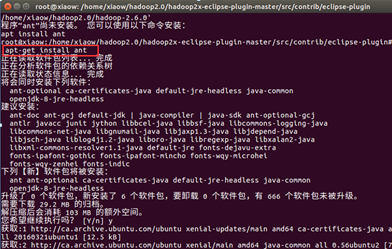
编译hadoop2x-eclipse-plugin-master的plugin 的插件源码,需要先安装ant工具
接着输入命令(注意ant命令在什么路径下使用,具体路径在下一张截图中,不然这个命令会用不了):
ant jar -Dversion=2.6.0 -Declipse.home='/home/xiaow/hadoop2.0/eclipse' # 刚才放进去的eclipse软件包的路径 -Dversion=2.6.0 hadoop的版本号
-Dhadoop.home='/home/xiaow/hadoop2.0/hadoop-2.6.0' # hadoop安装文件的路径
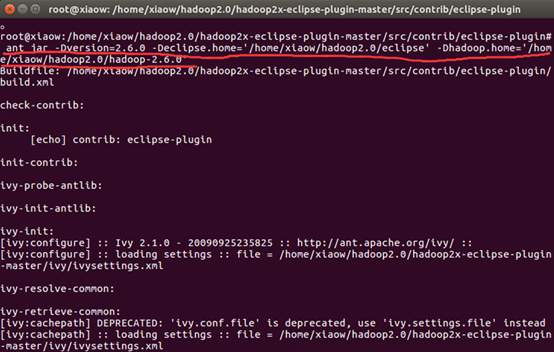
等待一小会时间就好了
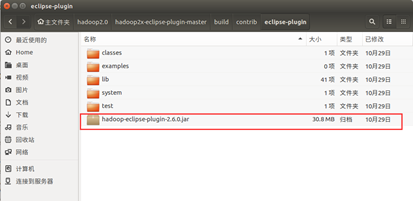
编译成功后,找到放在 /home/xiaow/ hadoop2.0/hadoop2x-eclipse-pluginmaster/build/contrib/eclipse-plugin下, 名为hadoop-eclipse-plugin-2.6.0.jar的jar包, 并将其拷贝到/hadoop2.0/eclipse/plugins下
输入命令:
cp -r /home/xiaow/hadoop2.0/hadoop2x-eclipse-plugin-master/build/contrib/eclipse-plugin/hadoop-eclipse-plugin-2.6.0.jar /home/xiaow/hadoop2.0/eclipse/plugins/


二、Eclipse配置
接下来打开eclipse软件
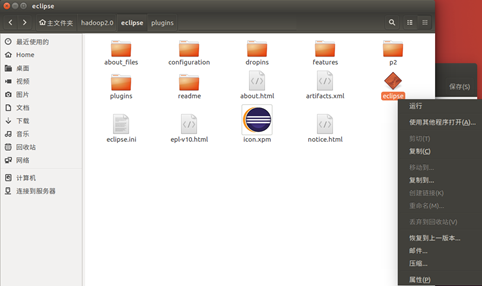
一定要出现这个图标,没有出现的话前面步骤可能错了,或者重新启动几次Eclipse
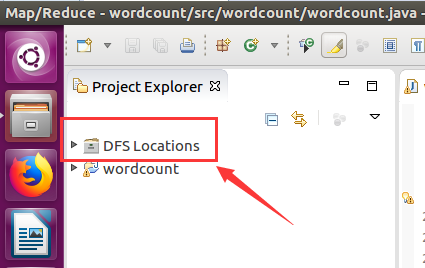
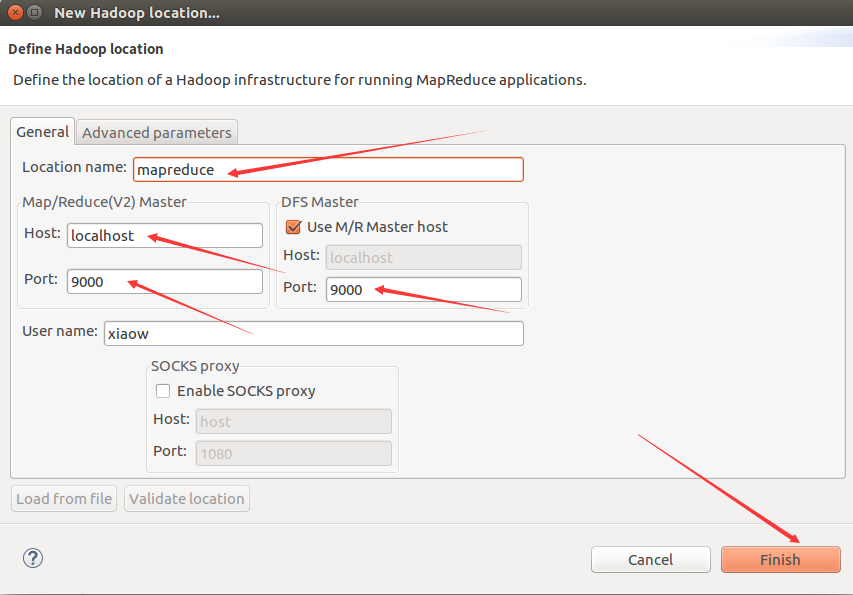
然后按照下面的截图操作:
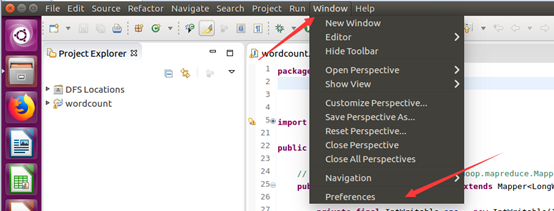
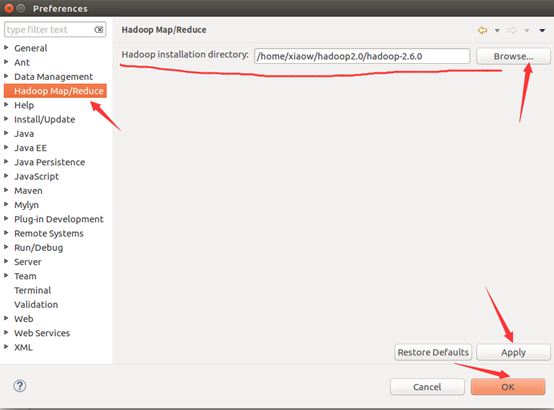
如此,Eclipse环境搭建完成。
三、wordcount程序
建工程:
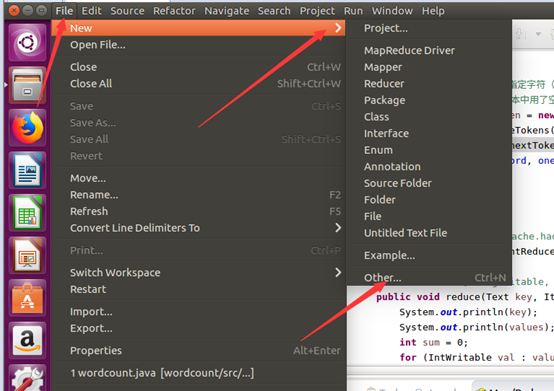
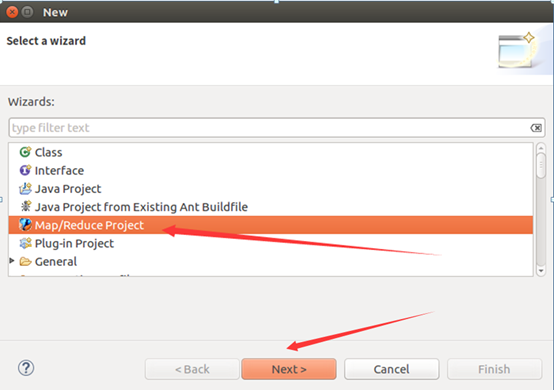
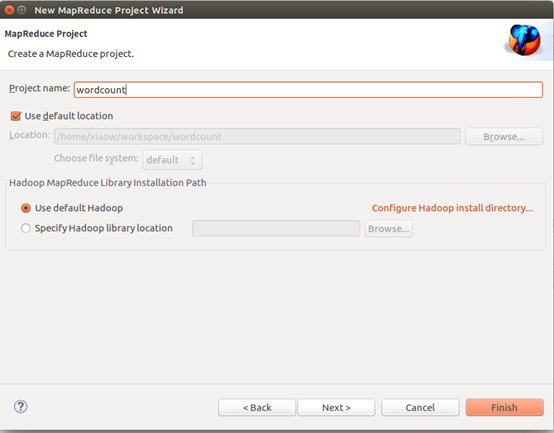
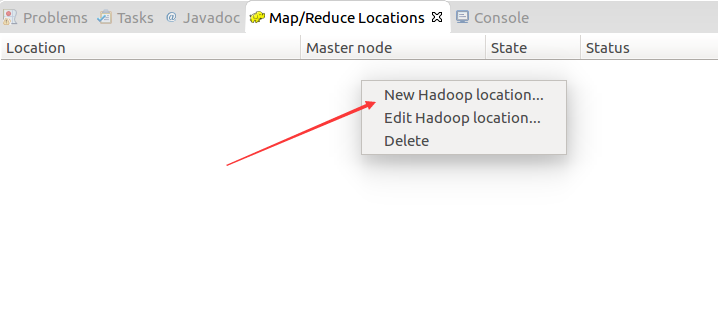
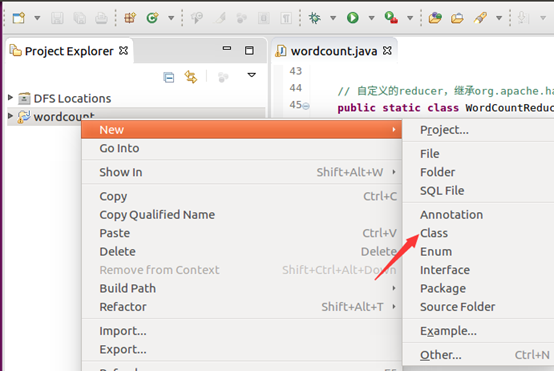
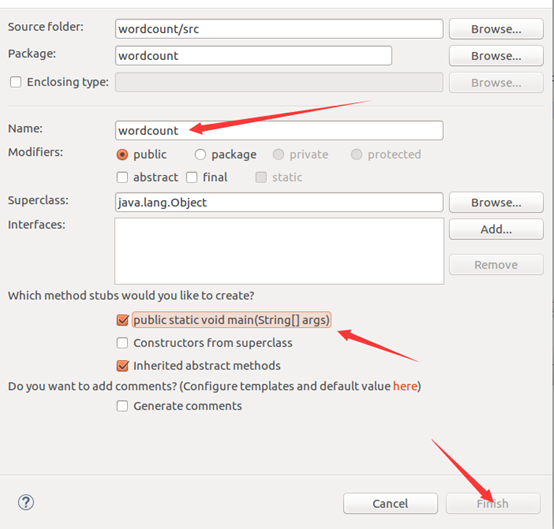
输入如下代码:
package wordcount; import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.reduce.IntSumReducer;
import org.apache.hadoop.util.GenericOptionsParser; public class wordcount { // 自定义的mapper,继承org.apache.hadoop.mapreduce.Mapper
public static class WordCountMap extends Mapper<LongWritable, Text, Text, IntWritable> { private final IntWritable one = new IntWritable(1);
private Text word = new Text(); // Mapper<LongWritable, Text, Text, LongWritable>.Context context
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
System.out.println(line);
// split 函数是用于按指定字符(串)或正则去分割某个字符串,结果以字符串数组形式返回,这里按照“\t”来分割text文件中字符,即一个制表符
// ,这就是为什么我在文本中用了空格分割,导致最后的结果有很大的出入
StringTokenizer token = new StringTokenizer(line);
while (token.hasMoreTokens()) {
word.set(token.nextToken());
context.write(word, one);
}
}
} // 自定义的reducer,继承org.apache.hadoop.mapreduce.Reducer
public static class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable> { // Reducer<Text, LongWritable, Text, LongWritable>.Context context
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
System.out.println(key);
System.out.println(values);
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
} // 客户端代码,写完交给ResourceManager框架去执行
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf,"word count"); // 打成jar执行
job.setJarByClass(wordcount.class); // 数据在哪里?
FileInputFormat.addInputPath(job, new Path(args[0])); // 使用哪个mapper处理输入的数据?
job.setMapperClass(WordCountMap.class);
// map输出的数据类型是什么?
//job.setMapOutputKeyClass(Text.class);
//job.setMapOutputValueClass(LongWritable.class); job.setCombinerClass(IntSumReducer.class); // 使用哪个reducer处理输入的数据
job.setReducerClass(WordCountReduce.class); // reduce输出的数据类型是什么?
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); // job.setInputFormatClass(TextInputFormat.class);
// job.setOutputFormatClass(TextOutputFormat.class); // 数据输出到哪里?
FileOutputFormat.setOutputPath(job, new Path(args[1])); // 交给yarn去执行,直到执行结束才退出本程序
job.waitForCompletion(true); /*
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length<2){
System.out.println("Usage:wordcount <in> [<in>...] <out>");
System.exit(2);
}
for(int i=0;i<otherArgs.length-1;i++){
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
System.exit(job.waitForCompletion(tr0ue)?0:1);
*/
}
}
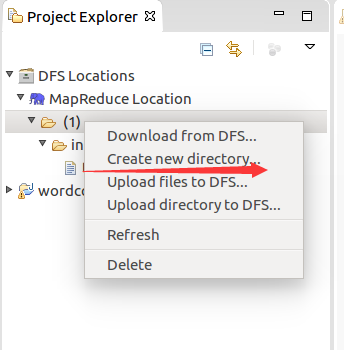
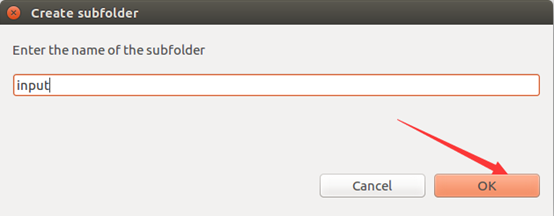
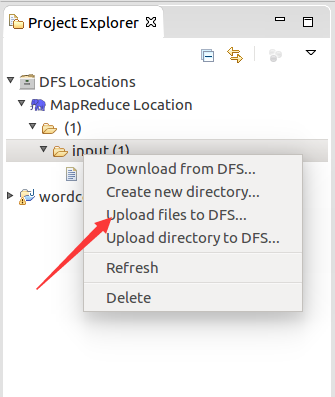
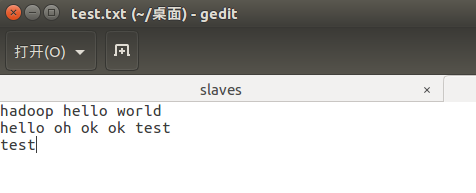
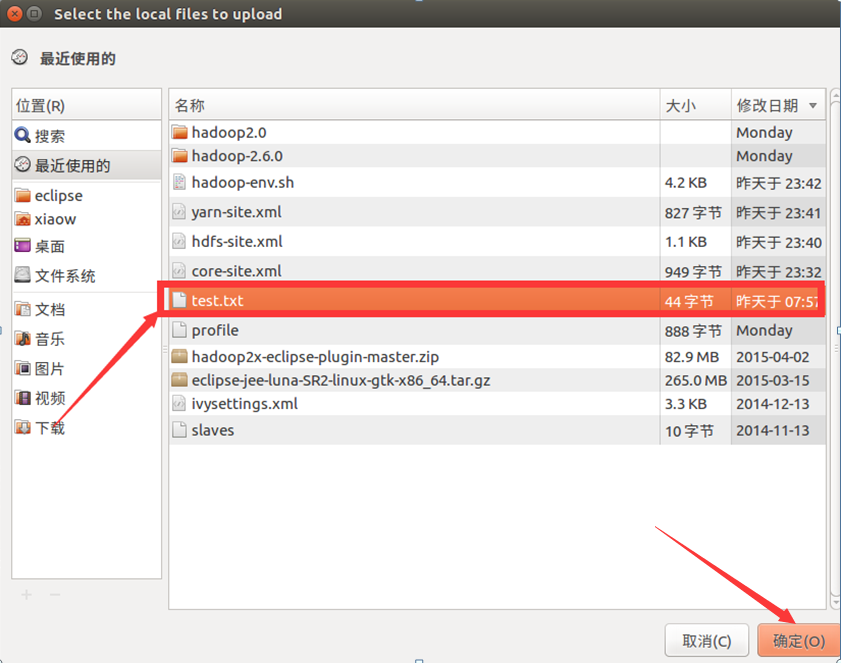
将准备到的文档导入进去
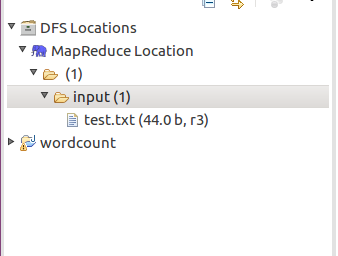
目录结构如下:
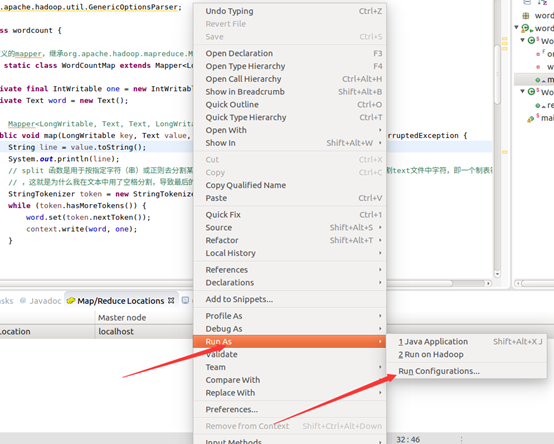
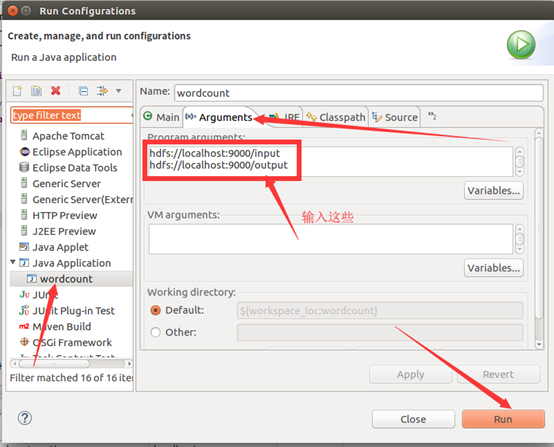
运行mapreduce程序
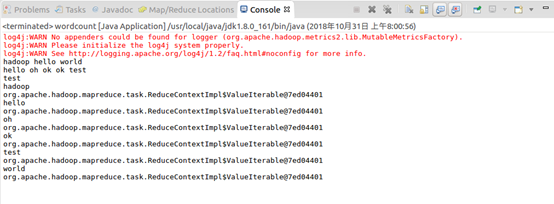
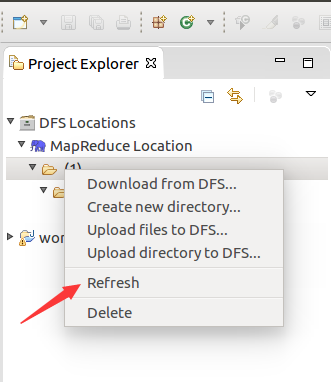
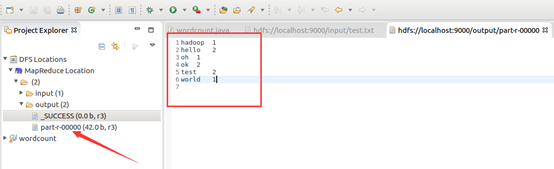
OK,搞定收工!!!
Eclipse环境搭建并且运行wordcount程序的更多相关文章
- (三)配置Hadoop1.2.1+eclipse(Juno版)开发环境,并运行WordCount程序
配置Hadoop1.2.1+eclipse(Juno版)开发环境,并运行WordCount程序 一. 需求部分 在ubuntu上用Eclipse IDE进行hadoop相关的开发,需要在Eclip ...
- 021_在Eclipse Indigo中安装插件hadoop-eclipse-plugin-1.2.1.jar,直接运行wordcount程序
1.工具介绍 Eclipse Idigo.JDK1.7-32bit.hadoop1.2.1.hadoop-eclipse-plugin-1.2.1.jar(自己网上下载) 2.插件安装步骤 1)将ha ...
- 《从0到1学习Flink》—— Mac 上搭建 Flink 1.6.0 环境并构建运行简单程序入门
准备工作 1.安装查看 Java 的版本号,推荐使用 Java 8. 安装 Flink 2.在 Mac OS X 上安装 Flink 是非常方便的.推荐通过 homebrew 来安装. brew in ...
- OSGI企业应用开发(二)Eclipse中搭建Felix运行环境
上篇文章介绍了什么是OSGI以及使用OSGI构建应用的优点,接着介绍了两款常用的OSGI实现,分别为Apache Felix和Equinox,接下来开始介绍如何在Eclipse中使用Apache Fe ...
- scala 入门Eclipse环境搭建及第一个入门经典程序HelloWorld
scala 入门Eclipse环境搭建及第一个入门经典程序HelloWorld 学习了: http://blog.csdn.net/wangmuming/article/details/3407911 ...
- eclipse连hadoop2.x运行wordcount 转载
转载地址:http://my.oschina.net/cjun/blog/475576 一.新建java工程,并且导入hadoop相关jar包 此处可以直接创建mapreduce项目就可以,不用下面折 ...
- Java学习不走弯路教程(7.Eclipse环境搭建)
7.Eclipse环境搭建 在前几章,我们熟悉了DOS环境下编译和运行Java程序,对于大规模的程序编写,开发工具是必不可少的.Java的开发工具比较常用的是Eclipse.在接下来的教程中,我们将基 ...
- scala 入门Eclipse环境搭建
scala 入门Eclipse环境搭建及第一个入门经典程序HelloWorld IDE选择并下载: scala for eclipse 下载: http://scala-ide.org/downloa ...
- Cesium入门2 - Cesium环境搭建及第一个示例程序
Cesium入门2 - Cesium环境搭建及第一个示例程序 Cesium中文网:http://cesiumcn.org/ | 国内快速访问:http://cesium.coinidea.com/ 验 ...
随机推荐
- 十三、实现Comparable接口和new Comparator<T>(){ }排序的实现过程
参考:https://www.cnblogs.com/igoodful/p/9517784.html Collections有两种比较规则方式,第一种是使用自身的比较规则: 该类必须实现Compara ...
- python rsa 加密
rsa 非对称加密, 公钥加密, 私钥解密, 有公钥无法推导出私钥, 私钥保密 import rsa n = 1024 # n 越大生成公钥, 秘钥及加密解密所需时间就越长 key = rsa.new ...
- Angular中不同的组件间传值与通信的方法
主要分为父子组件和非父子组件部分. 父子组件间参数与通讯方法 使用事件通信(EventEmitter,@Output): 场景:可以在父子组件之间进行通信,一般使用在子组件传递消息给父组件: 步骤: ...
- windows 上安装冷门python模块
最近在逼乎看到 笑虎大大 的python 撸代码学知识专栏..就下载他的Pspider 框架 安装了一下,准备耍耍. 由于是在Windows下的pycharm 有个 pybloom_live 模块 老 ...
- django添加控件
function bindRemoveCls() { $('#removeCls').click(function () { var options = $('#sel')[0].selectedOp ...
- windows socket 文件下载上传
socket 图片 文件 下载上传 数据库 线程池 存入图片 等
- Sum of Subsequence Widths LT891
Given an array of integers A, consider all non-empty subsequences of A. For any sequence S, let the ...
- Springboot异常:org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'userController'
今天本菜鸟编写程序时,遇到了一个异常. org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating ...
- 实现一个简易版的SpringMvc框架
先来看我们的程序入口DispatcherServlet 主要核心处理流程如下: 1 扫描基础包下的带有controller 以及 service注解的class,并保存到list中 2 对第一步扫描到 ...
- http://www.cnblogs.com/langjt/p/4281477.html
http://www.cnblogs.com/langjt/p/4281477.html