Batch normalization:accelerating deep network training by reducing internal covariate shift的笔记
说实话,这篇paper看了很久,,到现在对里面的一些东西还不是很好的理解。
下面是我的理解,当同行看到的话,留言交流交流啊!!!!!
这篇文章的中心点:围绕着如何降低 internal covariate shift 进行的, 它的方法就是进行batch normalization。
internal covariate shift 和 batch normalization
1. 什么是 internal covariate shift呢?
简单地理解为一个网络或system的输入的dirstribution不断地发生变化,导致网络的训练很难。
2. 文中的 batch normalization 怎么回事呢?
1)文中对输入data的每一维的基于batch 块的size 个数据 进行 normalization。 用公式表示:
, 这个其实就是 z-score。
2)为了不改变网络的 representation(进行normalizaiton, 肯定改变了输入的 scale了吧), 对normalization 之后的值进行scale 与 shift: (我感觉这个很重要的,真的)
分析:
首先:对于如何尽可能地使每一层的 inputs 的 distribution 不发生变化这一件事情上,文章的做法就是:对输入进行 normalizaiton, 结果呢, 每一维上的数据的分布有了相同的 均值 0 与 方差(variance). 也仅仅只能在这两点上进行对网络的输入的分布进行控制, 来达到减少 internal covariate shift的目的;
第二点:这个网络的输入是指的:上一层的输入 X 加权 W 以后的值,即 WX(也可以加上偏置,不过应该省略掉,加了也没有屁用,经过 normalization就没有作用了,另个后面对它进行调整的beta值可以代替它的使用了)。 如果想对网络的输出即 X 进行 batch normalizaiton 也是可以的,不过呢,由于呢,X 需要进行加权 W,所以呢,仅仅通过 mean 与 variance (即一阶矩与二阶矩)并不能很好地控制 输入的 distribution. 文章3.2 section的原话为: We could have also normalized the layer inputs u, but since u is likely the output of another nonlinearity, the shape of its distribution is likely t o change during training, and constraining its first and second moments would not eliminate the covariate shift。
第三点:为什么是在输入的每一维进行 normalizaiton,而不是对于输入的维度之间即每一层N个激活函数的输入之间进行呢? (在有些的神经网络中,有时最开始的输入进行标准化)
后来思考了一个这个问题: 认为就是应该在基于 batch的每一维度之间进行 normalizaiton. 在训练过程中,对于不同的 examples, 就应该让输入的每一个维度的分布尽可能一样,别瞎变来变去的。 而输入的各个维度之间的分布尽可能地不同,只能这样才可以更好地进行分类啊。 你想想,把很多类别集中在一个小的区域好呢,还是分散更好呢? 或者这么理解是对的吧。。。
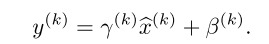
文章 section 2 的理解:
问题1: 这是想了好久呢,感觉问题在于:
这个公式,它们不相等啊。。。。 E(delta)b 不等于 (delta)b 的啊。
问题2:另外,如果考虑 EX 对 B 的影响,会发现 delta b 为0 啊。。,所以,因为经过normalization, 这个偏置对网络的输入没有什么影响啊,直接约没有了;
问题3:对于文中解释的,为什么会出现文中的那个情况,我真的没有看明白啊。。我感觉文中意思是应该把Ex中的相关参数考虑进去。 但是考虑进去的话,就出现问题2 的情况了,这个 b 直接不用更新了,反正它对输入也没有影响了。另外通过 beta 参数就可以代替偏置b 的作用了;

batch normalizaiton 的步骤与梯度公式:
在网络进行正向传导时, batch normalization的步骤为如下图,即文中的 algorithm 1:
这个不难,一看就明白;
下图为梯度更新公式:
对于上面的公式:主要明白第二个与第三个公式中的为什么要求 m 的加和:在基于mini-batch 的反向传播算法中, W 与 b 的更新都是要进行加和处理的,对吧,没有问题。而
与W 和 b 是类似的,在 batch中的examples 之间是共用的,所以呢,需要加和。 到最后更新使用的时候,要不要除以 m, 这个需要看 loss函数是怎么定义的了;
链式法则时:永远记住谁是谁的变量,就不会出错了。例如:上面公式中为什么要求对
的梯度呢,就是因为 xi 影响了
,在求对 xi 的梯度时,需要计算在包含在
中的那一部分;


对于测试过程:
需要思考:训练的时候,normalizaiton的参数由batch 的example决定,而测试时,这个参数怎么办???
这个参数只能中训练样本决定(千万别想着由测试样本决定,怎么可能), 文章中采用无偏估计,理论为中全部的样本的均值与方差,但是计算公式如下:
公式表示把每一个batch的参数再求无偏估计的期望值, 而不是重新把样本全部相加计算;因为, batch 参数在训练过程的已经求出了啊,避免再次计算了,并且用无偏估计可以更好的估计出用全部样本计算出来的方差与均值;
再想一个问题:
很多时候,我们基于样本集1 训练出来的网络模型,可以通过 tuning,应用到 样本集中。 而采用 batch normalizaiton 的方法训练得到的网络模型,很大程度上应该受到了这样的限制。 因为参数中的均值与方差很依赖训练样本的;
训练与测试的总过程:


对于卷积的情况:
在全连接层的网络中的每一个神经元相当于卷积层的中每一个 feature map. 在同一个feature map中的神经元之间共享权值与偏置。对于卷积神经网络的 bath normalization, 这里的batch 指的是同一个 feature map 以及 batch 上的二者 联合起来的 batch . 例如: batch 大小为32, feature map 为 5*5 ,则应该在 32* 5*5 个输入之间求均值与方差;
bath normalization 是怎么enable higher learning rate的:
文章的解释为:当大的 lr时, 会使权值变大,而权值变大不会影响 layer jacobian(它决定了反向传播过程中的梯度在网络中的传播), 并且使 对权值的更新的梯度变小; 公式如下:
这个公式简单证明一下:
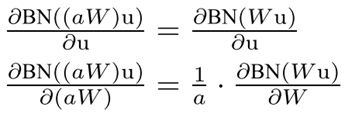

对于其它:
文章其它就是说了实验部分了,以及对 batch normalization 的其它一些功能的推测;
在实验部分最让我吃惊的地方就是: 使用batch normalization以后,学习速度明显加快了很多,这一点很重要啊;我感觉特厉害;
另外,文章有很多用于协方差矩阵、奇异值等的地方,这个需要加强演习;
论文引用:
Ioffe S, Szegedy C. Batch normalization: Accelerating deep network training by reducing internal covariate shift[J]. arXiv preprint arXiv:1502.03167, 2015.
Batch normalization:accelerating deep network training by reducing internal covariate shift的笔记的更多相关文章
- Deep Learning 27:Batch normalization理解——读论文“Batch normalization: Accelerating deep network training by reducing internal covariate shift ”——ICML 2015
这篇经典论文,甚至可以说是2015年最牛的一篇论文,早就有很多人解读,不需要自己着摸,但是看了论文原文Batch normalization: Accelerating deep network tr ...
- 图像分类(二)GoogLenet Inception_v2:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Inception V2网络中的代表是加入了BN(Batch Normalization)层,并且使用 2个 3*3卷积替代 1个5*5卷积的改进版,如下图所示: 其特点如下: 学习VGG用2个 3* ...
- 论文笔记:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
ICML, 2015 S. Ioffe and C. Szegedy 解决什么问题(What) 分布不一致导致训练慢:每一层的分布会受到前层的影响,当前层分布发生变化时,后层网络需要去适应这个分布,训 ...
- Batch Normalization:Accelerating Deep Network Training by Reducing Internal Covariate Shift(BN)
internal covariate shift(ics):训练深度神经网络是复杂的,因为在训练过程中,每层的输入分布会随着之前层的参数变化而发生变化.所以训练需要更小的学习速度和careful参数初 ...
- Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
1. 摘要 训练深层的神经网络非常困难,因为在训练的过程中,随着前面层数参数的改变,每层输入的分布也会随之改变.这需要我们设置较小的学习率并且谨慎地对参数进行初始化,因此训练过程比较缓慢. 作者将这种 ...
- Batch Normalization原理及其TensorFlow实现——为了减少深度神经网络中的internal covariate shift,论文中提出了Batch Normalization算法,首先是对”每一层“的输入做一个Batch Normalization 变换
批标准化(Bactch Normalization,BN)是为了克服神经网络加深导致难以训练而诞生的,随着神经网络深度加深,训练起来就会越来越困难,收敛速度回很慢,常常会导致梯度弥散问题(Vanish ...
- 深度学习网络层之 Batch Normalization
Batch Normalization Ioffe 和 Szegedy 在2015年<Batch Normalization: Accelerating Deep Network Trainin ...
- 【深度学习】深入理解Batch Normalization批标准化
这几天面试经常被问到BN层的原理,虽然回答上来了,但还是感觉答得不是很好,今天仔细研究了一下Batch Normalization的原理,以下为参考网上几篇文章总结得出. Batch Normaliz ...
- 解读Batch Normalization
原文转自:http://blog.csdn.net/shuzfan/article/details/50723877 本次所讲的内容为Batch Normalization,简称BN,来源于<B ...
随机推荐
- 行为类模式(十一):访问者(Visitor)
定义 表示一个作用于某对象结构中的各元素的操作.它使你可以在不改变各元素类的前提下定义作用于这些元素的新操作. UML 优点 符合单一职责原则:凡是适用访问者模式的场景中,元素类中需要封装在访问者中的 ...
- http缓存机制之304状态码
在网上看到一篇关于解释浏览器缓存更新机制304状态码的文章,里面说如果请求头中的If-Modified-Since字段和If-None-Match字段的值分别和响应头中的Last-Modified字段 ...
- oracle 负载均衡连接方式常用SQL语句备忘录
1.---表中有重复记录用SQL语句查询出来 select * from Recharge where RechargeSerial in (select RechargeSerial from Re ...
- Lua 自己实现排序sort比较方法,抛出错误invalid order function for sorting
明天新功能就要上了,结果刚刚突然QA说项目抛出了错误.握草,吓得立马出了一身汗. 查了一下错误,发现可能是自己写的不稳定排序造成的.自己感觉应该就是.把排序方法写成稳定的之后,代码分离编译进手机,跑了 ...
- Spring Boot(三):RestTemplate提交表单数据的三种方法
http://blog.csdn.net/yiifaa/article/details/77939282 ********************************************** ...
- 7个华丽的基于Canvas的HTML5动画
说起HTML5,可能让你印象更深的是其基于Canvas的动画特效,虽然Canvas在HTML5中的应用并不全都是动画制作,但其动画效果确实让人震惊.本文收集了7个最让人难忘的HTML5 Canvas动 ...
- MATLAB中-27开3次方得不到-3的原因
原代码: y=@(x) x.^(/); 运行结果: >> y(-27) ans = 1.5000 + 2.5981i 原因: 用(-8)^(1/3)时,matlab其实是调用C = pow ...
- Python3 ctypes简单使用
>>> from ctypes import * >>> c_int() c_long(0) >>> c_char_p(b'hello') c_c ...
- How Not to Crash系列地址
http://inessential.com/hownottocrash How Not to Crash #1: KVO and Manual Bindings How Not to Crash # ...
- 【Java笔记】配置文件java.util.Properties类的使用
配置文件的路径:项目名/src/main/resources/mmall.properties mmall.properties的内容是键值对.例如假设写了ftp服务器的一些信息. ftp.serve ...