Scrapy爬取人人网
Scrapy发送Post请求


防止爬虫被反主要有以下几个策略
动态设置User-Agent(随机切换User-Agent,模拟不同用户的浏览器信息)
禁用Cookies(也就是不启用cookies middleware,不向Server发送cookies,有些网站通过cookie的使用发现爬虫行为)
可以通过COOKIES_ENABLED 控制 CookiesMiddleware 开启或关闭
设置延迟下载(防止访问过于频繁,设置为 2秒 或更高)
Google Cache 和 Baidu Cache:如果可能的话,使用谷歌/百度等搜索引擎服务器页面缓存获取页面数据。
使用IP地址池:VPN和代理IP,现在大部分网站都是根据IP来的。
Request/Response重要参数
request
url: 就是需要请求,并进行下一步处理的url
callback: 指定该请求返回的Response,由那个函数来处理。
method: 请求一般不需要指定,默认GET方法,可设置为"GET", "POST", "PUT"等,且保证字符串大写
headers: 请求时,包含的头文件。一般不需要
meta: 比较常用,在不同的请求之间传递数据使用的。字典dict型
encoding: 使用默认的 'utf-8' 就行。
dont_filter: 表明该请求不由调度器过滤。这是当你想使用多次执行相同的请求,忽略重复的过滤器。默认为False
Response
status: 响应码
_set_body(body): 响应体
_set_url(url):响应url
logging设置
通过在setting.py中进行以下设置可以被用来配置logging:
LOG_ENABLED 默认: True,启用logging
LOG_ENCODING 默认: 'utf-8',logging使用的编码
LOG_FILE 默认: None,在当前目录里创建logging输出文件的文件名
LOG_LEVEL 默认: 'DEBUG',log的最低级别
LOG_STDOUT 默认: False 如果为 True,进程所有的标准输出(及错误)将会被重定向到log中。例如,执行 print "hello" ,其将会在Scrapy log中显示。
开发工作中经常会加上以下两行:
LOG_FILE = “文件名.log"
LOG_LEVEL = "INFO"
爬取人人网
1.创建project
2.spider文件
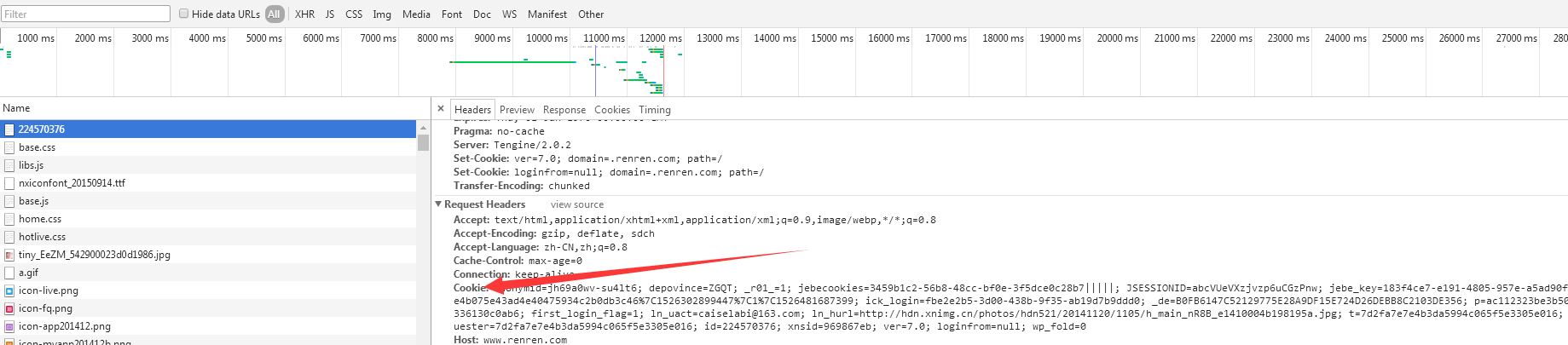

# -*- coding: utf-8 -*-
import scrapy class RenSpider(scrapy.Spider):
name = 'ren'
allowed_domains = ['renren.com']
start_urls = ['http://www.renren.com/224570376']
#
# def parse(self, response):
# pass
cookies ={
"anonymid":"jh7sb9et-4tc38k",
"depovince":"ZGQT",
"_r01_":"",
"JSESSIONID":"abchwEf-VGdFQ9MRUpKnw",
"ick_login":"aa78cdea-7fa6-4f6f-a5d4-1506323cb55e",
"jebecookies":"3b7201da-0aba-40b3-ad00-6b9d5808875e|||||",
"_de":"B0FB6147C52129775E28A9DF15E724D26DEBB8C2103DE356",
"p":"8353bac56f02e1e0172b6833946ea0076",
"first_login_flag":"",
"ln_uact":"caiselabi@111.com",
"ln_hurl":"http://hdn.xnimg.cn/photos/hdn521/20141120/1105/h_main_nR8B_e1410004b198195a.jpg",
"t":"ac38040778d340717a703a4900c225c46",
"societyguester":"ac38040778d340717a703a4900c225c46",
"id":"",
"xnsid":"9bb6c227",
"ver":"7.0",
"loginfrom":"null",
"jebe_key":"912e89dc-2c29-4be9-9ba4-1c5582b12e1d%7C8e4b075e43ad4e40475934c2b0db3c46%7C1526395913348%7C1%7C1526395915790",
"wp_fold":0
} def start_requests(self):
for url in self.start_urls:
yield scrapy.FormRequest(url=url,cookies=self.cookies,callback=self.parse) def parse(self, response):
print(response.body.decode()) # 打印源码文本
name = response.xpath('//p[@class="status"]/text()').extract_first()
with open('renren.txt','w',encoding='utf-8') as f:
f.write(name)
# name_element = '//p[@class="status]/text()'
# friend_element = '//div[@class="userhead"]/span/text()'
#
# def start_requests(self):
# url = "http://www.renren.com/PLogin.do"
#
# yield scrapy.FormRequest(
# url=url,
# formdata={"email":"caiselabi@111.com","password":"111111"},
# callback=self.parse
# )
# print('*'*30)
#
#
# def parse(self, response):
# print(response.body.decode()) # 打印源码文本
# name = response.xpath('//p[@class="status"]/text()').extract_first()
# print(name)
# friend =response.xpath('//div[@class="userhead"]/span/text()').extract_first()
# print(friend)
# # with open('renren.txt','w',encoding='utf-8') as f:
# # # f.write(name)
3.settings
BOT_NAME = 'renren' SPIDER_MODULES = ['renren.spiders']
NEWSPIDER_MODULE = 'renren.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0' # Obey robots.txt rules
ROBOTSTXT_OBEY = True # log日志
LOG_ENABLED = True # 默认: True,启用logging
LOG_FILE = 'renren.log'
LOG_LEVEL = 'DEBUG'
LOG_ENCODING = 'utf-8'
LOG_DATEFORMAT='%m/%d/%Y %H:%M:%S %p'
LOG_STDOUT = True
# 默认: False 如果为 True,进程所有的标准输出(及错误)将会被重定向到log中。例如,执行 print "hello" ,其将会在Scrapy log中显示
4.运行
scrapy crawl ren
Scrapy爬取人人网的更多相关文章
- Scrapy爬取美女图片 (原创)
有半个月没有更新了,最近确实有点忙.先是华为的比赛,接着实验室又有项目,然后又学习了一些新的知识,所以没有更新文章.为了表达我的歉意,我给大家来一波福利... 今天咱们说的是爬虫框架.之前我使用pyt ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- scrapy爬取西刺网站ip
# scrapy爬取西刺网站ip # -*- coding: utf-8 -*- import scrapy from xici.items import XiciItem class Xicispi ...
- scrapy爬取豆瓣电影top250
# -*- coding: utf-8 -*- # scrapy爬取豆瓣电影top250 import scrapy from douban.items import DoubanItem class ...
- scrapy爬取极客学院全部课程
# -*- coding: utf-8 -*- # scrapy爬取极客学院全部课程 import scrapy from pyquery import PyQuery as pq from jike ...
- scrapy爬取全部知乎用户信息
# -*- coding: utf-8 -*- # scrapy爬取全部知乎用户信息 # 1:是否遵守robbots_txt协议改为False # 2: 加入爬取所需的headers: user-ag ...
- Scrapy爬取Ajax(异步加载)网页实例——简书付费连载
这两天学习了Scrapy爬虫框架的基本使用,练习的例子爬取的都是传统的直接加载完网页的内容,就想试试爬取用Ajax技术加载的网页. 这里以简书里的优选连载网页为例分享一下我的爬取过程. 网址为: ht ...
- Scrapy爬取静态页面
Scrapy爬取静态页面 安装Scrapy框架: Scrapy是python下一个非常有用的一个爬虫框架 Pycharm下: 搜索Scrapy库添加进项目即可 终端下: #python2 sudo p ...
- 用scrapy爬取京东的数据
本文目的是使用scrapy爬取京东上所有的手机数据,并将数据保存到MongoDB中. 一.项目介绍 主要目标 1.使用scrapy爬取京东上所有的手机数据 2.将爬取的数据存储到MongoDB 环境 ...
随机推荐
- [转载]三款SDR平台对比:HackRF,bladeRF和USRP
这篇文章是 Taylor Killian 13年8月发表在自己的博客上的.他对比了三款平价的SDR平台,认为这三款产品将是未来一年中最受欢迎的SDR平台.我觉得这篇文章很有参考价值,简单翻译一份转过来 ...
- UIWebView和UIWebViewDelegate的基本用法 (转)
一.UIWebView主要有三种方法实现页面的装载,分别是: 1. (void)loadRequest:(NSURLRequest *)request; (直接装载URL) 2. (void)loa ...
- 第十章 企业项目开发--分布式缓存Redis(2)
注意:本章代码是在上一章的基础上进行添加修改,上一章链接<第九章 企业项目开发--分布式缓存Redis(1)> 上一章说了ShardedJedisPool的创建过程,以及redis五种数据 ...
- VC++ 6.0 C8051F340 USB 通信 CAN 数据解析
// HelloWorld.cpp : Defines the entry point for the console application. // /*********************** ...
- Android中对文件的读写进行操作
1. 在文件的地方生成一个read.txt文件,并且写入一个read数据.IO流用完之后一定要记得关闭. 对于try和catch是对于错误的抓取. 2. 首先先new file来找到那个文件,然后在通 ...
- 很全面的WinRAR实用技巧系列 - imsoft.cnblogs
WinRAR也可以管理我的桌面时间长了,桌面上堆的东西实在太多,平时该如何管理呢?安装了WinRAR的朋友可以请它来帮忙,用它管理清除无用的桌面文件或图标. 以XP系统为例,系统所在目录是“c:\wi ...
- 新建Android一个项目-菜鸟篇
①打开Eclipse,单击菜单栏的“File”->把鼠标光标移动到“New”->在弹出的列表框中,如果直接能看到“Android Applicaion Project”选项项,则直接单击此 ...
- jquery中.prev()
☆ 遍历 - .prev()方法:取得一个包含匹配的元素集合中每一个元素紧邻的前一个同辈元素的元素集合.选择性筛选的选择器. (previous:上一个,上一页,前一个,以前的......) 示例: ...
- SVN命令行使用总结
1.上传项目到SVN服务器上svn import project_dir(本地项目全路径) http://192.168.1.242:8080/svn/IOS/Ben/remote_dir(svn项目 ...
- 转详解Zoosk千万用户实时通信背后的开源技术
导语:本文由Zoosk(一个具有5000万会员的浪漫的社交约会网站)工程副总裁Peter Offringa所写,讲述了Zoosk的实时通信技术. 当我们的会员从Zoosk获得的最有价值的消息时,他们可 ...