8.3 MPI
MPI 模型
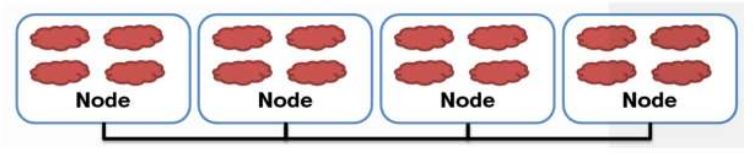
如图MPI的各个运算节点是分布式的.每一个节点可以视为是一个“Thread”,但这里的不同之处在于这些节点没有所谓的共享内存,或者说Global Memory。所以,在后面也会看到,一般会有一个节点专门处理数据传输和分配的问题。MPI和CUDA的另一个不同之处在于MPI只有一级结构,即所有的节点都在一个全局命名空间下,不像CUDA那样有Grid/Block/Thread三级层次。MPI同样也是基于SPMD模型,所有的节点执行相同的指令,而每个节点根据自己的ID来确定指令处理的数据,产生相应的输出。
MPI API介绍
以下面这段代码来介绍API: 这段代码的功能是实现向量相加
int main(int argc, char *argv[]) {
int size = ;
int pid = -;
int np = -;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &pid);
MPI_Comm_size(MPI_COMM_WORLD, &np);
if (np < ) {
if (pid == ) printf("Need 3 or more processes.\n");
MPI_Abort(MPI_COMM_WORLD, );
return ;
}
if (pid < np - )
compute_node(size / (np - ));
else
data_server(size);
MPI_Finalize();
return ;
}
1. MPI_Init()和MPI_Finalize()用于初始化和结束MPI框架;
2. MPI_COMM_WORLD代表了所有分配到的节点的集群;
3. MPI_Comm_rank()用于获取节点在集群中的标号,相当与CUDA中的threadIdx.x;
4. MPI_Comm_size()用于获取集群节点的数量,相当于blockDim.x;
5. MPI_Abort()用于中止执行。
上面代码中,有一个节点,也就是np-1节点,来负责数据的传输和分配,而其他的节点则负责计算。
数据传输data_server(size)是如何实现的呢?
MPI 通信
void data_server(unsigned int size) {
int np;
int first = ;
unsigned int num_bytes = size * sizeof(float);
float *a = ; float *b = ; float *c = ;
MPI_Comm_size(MPI_COMM_WORLD, &np);
a = (float *) malloc(num_bytes);
b = (float *) malloc(num_bytes);
c = (float *) malloc(num_bytes);
random_data(a, size);
random_data(b, size);
float *ptr_a = a;
float *ptr_b = b;
// send data
for (int i = ; i < np - ; i++) {
MPI_Send(ptr_a, size / (np - ), MPI_FLOAT, i, DATA_DISTRIBUTE, MPI_COMM_WORLD);
ptr_a += size / (np - );
MPI_Send(ptr_b,size / (np - ), MPI_FLOAT, i, DATA_DISTRIBUTE, MPI_COMM_WORLD);
ptr_b += size / (np - );
}
// wait for nodes to compute
MPI_Barrier(MPI_COMM_WORLD);
// collect output data
MPI_Status status;
for (int i = ; i < np -; i++) {
MPI_Recv(c + i * size /(np - ), size / (np - ), MPI_REAL, i, DATA_COLLECT, MPI_COMM_WORLD, &status);
}
store_output(c);
free(a); free(b); free(c);
}
int MPI_Send(void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm)
buf: 发送buffer的地址值.
count: 发送buffer的元素个数.
datatype: 发送buffer的数据类型.
dest: 个人理解为目标处理单元的索引,比如当前这个就是发送给第i个处理单元.
tag: 信息tag
comm: 传播者,handler
int MPI_Barrier(MPI_Comm comm): 阻塞调用者直到组内所有成员都调用它. 类似于cuda中的__syncthreads();
说完MPI 通信,下面来说MPI 计算部分.
MPI Compute
若节点支持CUDA,则还可以与CUDA结合起来进一步提高运算速度。以上面的计算节点为例:
void compute_node(unsigned int vector_size ) {
int np;
unsigned int num_bytes = vector_size*sizeof(float);
float *h_a, *h_b, *h_output;
float* d_A, d_B, d_output;
MPI_Status status;
MPI_Comm_size(MPI_COMM_WORLD, &np);
int server_process = np - ;
/* Allocate memory */
cudaHostAlloc((void **)&h_a, num_bytes, cudaHostAllocDefault);
cudaHostAlloc((void **)&h_b, num_bytes, cudaHostAllocDefault);
cudaHostAlloc((void **)&h_output, num_bytes, cudaHostAllocDefault);
/* Get the input data from server process */
MPI_Recv(h_a, vector_size, MPI_FLOAT, server_process, DATA_DISTRIBUTE, MPI_COMM_WORLD, &status);
MPI_Recv(h_b, vector_size, MPI_FLOAT, server_process, DATA_DISTRIBUTE, MPI_COMM_WORLD, &status);
/* Transfer data to CUDA device */
cudaMalloc((void **) &d_A, size);
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
cudaMalloc((void **) &d_B, size);
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
cudaMalloc((void **) &d_output, size);
/* Compute the partial vector addition */
dim3 Db(BLOCK_SIZE);
dim3 Dg((vector_size + BLOCK_SIZE – )/BLOCK_SIZE);
vector_add_kernel<<<Dg, Db>>>(d_output, d_a, d_b, vector_size);
MPI_Barrier(d_output);
/* Send the output */
MPI_Send(output, vector_size, MPI_FLOAT, server_process, DATA_COLLECT, MPI_COMM_WORLD);
/* Release device memory */
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_output);
}
上面使用了Pinned Memory,可以提高数据传输的效率。这里所做的工作,就是将原来串行的向量.
如果节点不支持cuda,则可以像普通C语言那样写:
for(int i=0; i<vector_size; ++i) {
output[i] = input_a[i] + input_b[i]
}
8.3 MPI的更多相关文章
- 查找素数Eratosthenes筛法的mpi程序
思路: 只保留奇数 (1)由输入的整数n确定存储奇数(不包括1)的数组大小: n=(n%2==0)?(n/2-1):((n-1)/2);//n为存储奇数的数组大小,不包括基数1 (2)由数组大小n.进 ...
- kmeans算法并行化的mpi程序
用c语言写了kmeans算法的串行程序,再用mpi来写并行版的,貌似参照着串行版来写并行版,效果不是很赏心悦目~ 并行化思路: 使用主从模式.由一个节点充当主节点负责数据的划分与分配,其他节点完成本地 ...
- MPI Maelstrom - POJ1502最短路
Time Limit: 1000MS Memory Limit: 10000K Description BIT has recently taken delivery of their new sup ...
- MPI之求和
// MPI1.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include "mpi.h" #include &l ...
- VS2012下配置MPI
并行处理结课实验,要用到MPI编程,我的电脑和VS2012都是64位的,以为MPICH也得是64位才行,结果饶了很大的弯——配置正确,添加引用之后,仍然无法识别MPI函数. 后来换了个32位的MPIC ...
- MPI+WIN10并行试运行
系统:2015 win10专业版 x64 MPI安装包:mpich2-1.4.1p1-win-x86-64.man 将后缀改为.msi 以管理员身份安装 安装过程一路默认,注意<behappy为 ...
- Parallel Computing–Cannon算法 (MPI 实现)
原理不解释,直接上代码 代码中被注释的源程序可用于打印中间结果,检查运算是否正确. #include "mpi.h" #include <math.h> #includ ...
- 基于MPI的并行计算—矩阵向量乘
以前没接触过MPI编程,对并行计算也没什么了解.朋友的期末课程作业让我帮忙写一写,哎,实现结果很一般啊.最终也没完整完成任务,惭愧惭愧. 问题大概是利用MPI完成矩阵和向量相乘.输入:Am×n,Bn× ...
- 大数据并行计算利器之MPI/OpenMP
大数据集群计算利器之MPI/OpenMP ---以连通域标记算法并行化为例 1 背景 图像连通域标记算法是从一幅栅格图像(通常为二值图像)中,将互相邻接(4邻接或8邻接)的具有非背景值的像素集合提取出 ...
- C++程序中调用MPI并行的批处理命令
问题来源:在使用MPI时,将程序并行实现了,运行时需要在dos窗口下输入批处理命令,以完成程序的执行. 如:mpiexec -localroot -n 6 d:/mpi/pro.exe 但每次这样挺麻 ...
随机推荐
- 电商安全无小事,如何有效地抵御 CSRF 攻击?
现在,我们绝大多数人都会在网上购物买东西.但是很多人都不清楚的是,很多电商网站会存在安全漏洞.比如乌云就通报过,国内很多家公司的网站都存在 CSRF 漏洞.如果某个网站存在这种安全漏洞的话,那么我们在 ...
- Chp3: Stacks and Queue
1. 说明如何用两个队列来实现一个栈,并分析有关栈操作的运行时间. 解法:1.有两个队列q1和q2,先往q1内插入a,b,c,这做的都是栈的push操作.2.现在要做pop操作,即要得到c,这时可以将 ...
- JAVA面试题:Spring中bean的生命周期
Spring 中bean 的生命周期短暂吗? 在spring中,从BeanFactory或ApplicationContext取得的实例为Singleton,也就是预设为每一个Bean的别名只能维持一 ...
- hibernate 数据行数统计 count(*)
Hibernate关于sql中的count(*)数据统计: ①如果使用的是HQL: 直接在HQL中使用count(*)即可获取行数 Long count = (Long)HibernateUtil.g ...
- mvc学习
视频: http://edu.51cto.com/index.php?do=lession&id=14581 博客: http://www.cnblogs.com/chsword/archiv ...
- Android中如何取消调转界面后EditText默认获取聚焦问题
最近在做一个项目,当我点击跳转至一个带有EditText的界面后,模拟器中的软键盘会自动弹出,严重影响了用户体验.在网上找了资料,现总结如下. 我们知道,EditText有一个 android:foc ...
- JavaWeb学习总结(四十九)——简单模拟Sping MVC
在Spring MVC中,将一个普通的java类标注上Controller注解之后,再将类中的方法使用RequestMapping注解标注,那么这个普通的java类就够处理Web请求,示例代码如下: ...
- 影响pogo pin连接器使用寿命的因素
精细化.安装简易化及使用寿命长是现在数码电子产品的趋势发展,pogo pin连接器体积小而且弹簧伸缩式设计,可以更好的缩小数码电子产品的尺寸并且连接安装更加的简单方便,因此pogo pin连接器得到了 ...
- 新的HTTP框架:Daraja Framework
https://www.habarisoft.com/daraja_framework.html
- linux系统相关的任务[fg、bg、jobs、&、ctrl + z]
转自: http://blog.chinaunix.net/space.php?uid=20697318&do=blog&id=1891382 fg.bg.jobs.&.ctr ...