初始scrapy,简单项目创建和CSS选择器,xpath选择器(1)
一 安装
#Linux:
pip3 install scrapy
#Windows:
a. pip3 install wheel
b. 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
c. 进入下载目录,执行 pip3 install Twisted‑17.1.0‑cp35‑cp35m‑win_amd64.whl
d. pip3 install pywin32
e. pip3 install scrapy
二 实验要求
目标网站: http://quotes.toscrape.com/tag/humor/
任务:保存网页信息到本地
二 创建爬虫项目
scrapy startproject tutorial
生成项目的结构
tutorial/
scrapy.cfg # 部署配置文件 tutorial/ # 项目的Python模块,你将从这里导入你的代码
__init__.py items.py # 项目项目定义文件,用于规定存储的字段 middlewares.py # 项目中间件文件 pipelines.py # 项目持久化存储文件 settings.py # 项目配置文件 spiders/ # 这里可以创建爬虫文件 . # 若干个爬虫文件
.
.
__init__.py
三 创建爬虫文件
scrapy genspider QuotesSpider #爬虫文件名为QuotesSpider
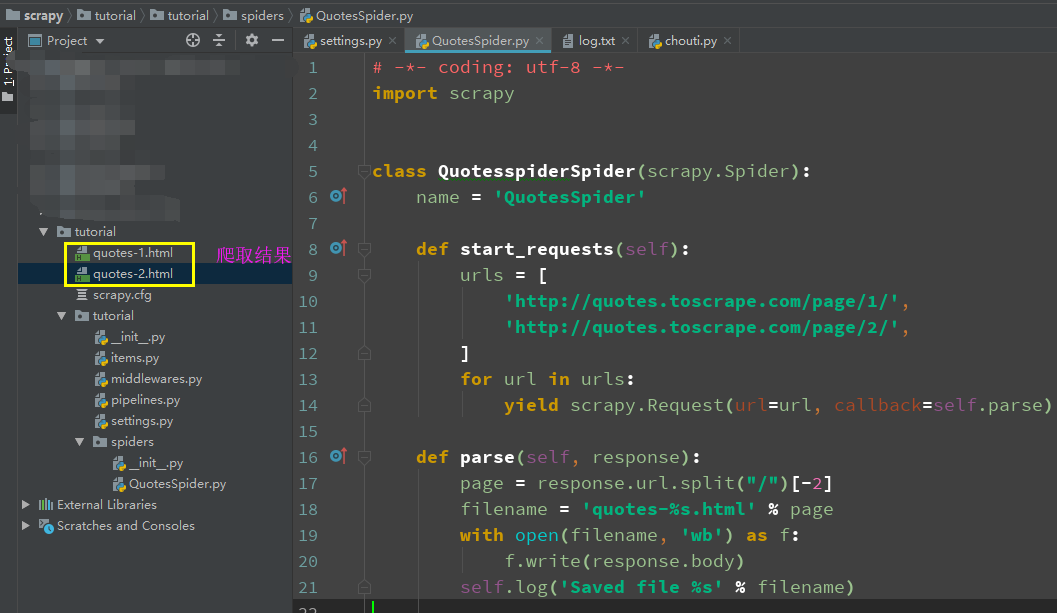
使用pycharm打开项目,修改QuotesSpider .py 文件改为
# -*- coding: utf-8 -*-
import scrapy class QuotesspiderSpider(scrapy.Spider):
name = 'QuotesSpider' #爬虫名字 def start_requests(self):
#待爬取的url列表
urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
for url in urls:
#提交请求,并制定回调函数为self.parse
yield scrapy.Request(url=url, callback=self.parse) def parse(self, response):
'解析页面,response是网页返回的数据(源码)'
page = response.url.split("/")[-2]
filename = 'quotes-%s.html' % page
# 网页保存
with open(filename, 'wb') as f:
f.write(response.body)
self.log('Saved file %s' % filename)
其中
name: 爬虫名字,项目中名字是唯一的.
start_requests():必须返回一个可迭代的对象.爬取起始url网页.指定回调函数.
parse():解析页面数据,
四 启动爬虫文件
scrapy crawl QuotesSpider
效果展示
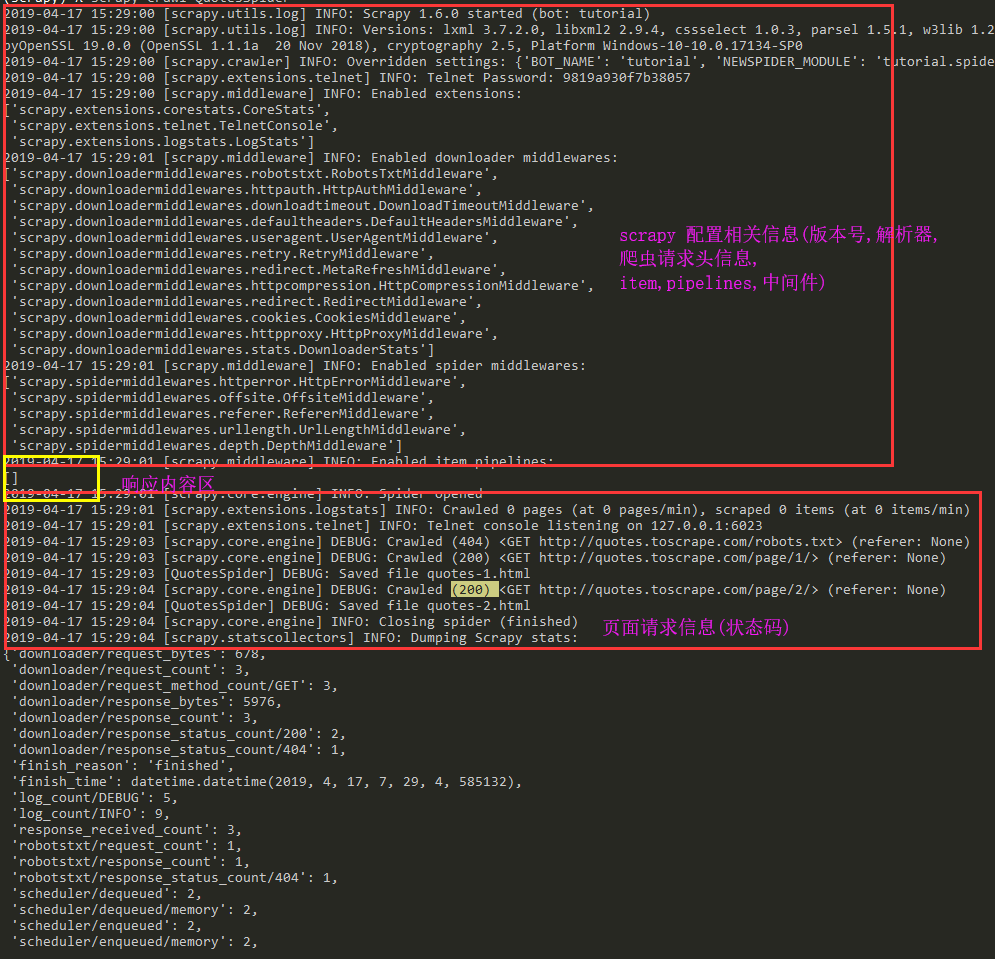
五 项目执行流程
Scrapy 执行的时候,首先会调用start_requests方法,然后执行方法中的scrapy.Request方法获取url对应网站的数据,得到Response相应对象,转而把Response对象交给Scrapy.Request的回调函数,在回调函数中解析response对象中的网页源码数据,保存到当前目录下.
六 Scrapy shell
使用Scrapy提取数据的最佳方法时使用scrapy shell 常识选择器.
scrapy shell "http://quotes.toscrape.com/page/1/"
执行此命令后可以进入交互模式(如下):

解析可选参数
[s] Available Scrapy objects: [s] scrapy # 可以使用scrapy中的模块,如contains scrapy.Request, scrapy.Selector...
[s] crawler # 当前爬虫对象
[s] item {}
[s] request #当前的请求页面
[s] response #当前请求的响应
[s] settings # 当前的配置文件
[s] spider <DefaultSpider 'default' at 0x7fa91c8af990> [s] Useful shortcuts:
[s] shelp() Shell help (print this help)
[s] fetch(req_or_url) # 爬取url或者request获取新的response
[s] view(response) # 使用网页打开response
使用栗子:

>>> response.css('title::text').getall() #获取标题中提取文本
['Quotes to Scrape']
七 scrapy 中的数据解析
Scrapy带有自己的提取数据机制。它们被称为选择器,因为它们“选择”由XPath或CSS表达式指定的HTML文档的某些部分。
测试代码
'''
<html>
<head>
<base href='http://example.com/' />
<title>Example website</title>
</head>
<body>
<div id='images'>
<a href='image1.html'>Name: My image 1 <br /><img src='image1_thumb.jpg' /></a>
<a href='image2.html'>Name: My image 2 <br /><img src='image2_thumb.jpg' /></a>
<a href='image3.html'>Name: My image 3 <br /><img src='image3_thumb.jpg' /></a>
<a href='image4.html'>Name: My image 4 <br /><img src='image4_thumb.jpg' /></a>
<a href='image5.html'>Name: My image 5 <br /><img src='image5_thumb.jpg' /></a>
</div>
</body>
</html>
'''
1 css解析器
>>> response.css('title').getall() #获取所有的匹配结果
['<title>Quotes to Scrape</title>']
>>> response.css('title::text')[0].get() #获取第一个匹配结果
'Quotes to Scrape'
使用正则匹配结果
>>> response.css('title::text').re(r'Quotes.*')
['Quotes to Scrape']
>>> response.css('title::text').re(r'Q\w+')
['Quotes']
>>> response.css('title::text').re(r'(\w+) to (\w+)')
['Quotes', 'Scrape']
2 xpath 解析数据
>>> response.xpath('//title')
[<Selector xpath='//title' data='<title>Quotes to Scrape</title>'>]
>>> response.xpath('//title/text()').get()
'Quotes to Scrape'
注意:scrapy使用xpath解析出来的数据返回的是select对象,一般提取数据信息的方法如下
# 获取第一个元素
author = div.xpath('./div[1]/a[2]/h2/text()')[0].extract()
# 获取第一个元素
author = div.xpath('./div[1]/a[2]/h2/text()').extract_first() #获取所有元素,结果为一个列表
content = div.xpath('./a[1]/div/span//text()').extract()
现在我们将获得基本URL和一些图像链接:
>>> response.xpath('//base/@href').get()
'http://example.com/'
>>> response.css('base::attr(href)').get()
'http://example.com/'
>>> response.css('base').attrib['href']
'http://example.com/'
>>> response.xpath('//a[contains(@href, "image")]/@href').getall()
['image1.html',
'image2.html',
'image3.html',
'image4.html',
'image5.html']
>>> response.css('a[href*=image]::attr(href)').getall()
['image1.html',
'image2.html',
'image3.html',
'image4.html',
'image5.html']
>>> response.xpath('//a[contains(@href, "image")]/img/@src').getall()
['image1_thumb.jpg',
'image2_thumb.jpg',
'image3_thumb.jpg',
'image4_thumb.jpg',
'image5_thumb.jpg']
>>> response.css('a[href*=image] img::attr(src)').getall()
['image1_thumb.jpg',
'image2_thumb.jpg',
'image3_thumb.jpg',
'image4_thumb.jpg',
'image5_thumb.jpg']
最后归纳:
获取元素中的文本推荐使用
- get( ) #获取第一个值
- getall( ) #获取所有,返回列表
八 调整代码进行所有页面数据爬取
# -*- coding: utf-8 -*-
import scrapy class QuotesspiderSpider(scrapy.Spider):
name = 'QuotesSpider' start_urls = [
'http://quotes.toscrape.com/page/1/',
] def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
#获取下一页的url
next_page = response.css('li.next a::attr(href)').get()
if next_page is not None:
#urljoin用于构建下一页的绝对路径url
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse)
使用css选择器获取下一页的url(相对路径),在使用response.urljoin()获取绝对路径,再次回调self.parse()实现所有页面数据爬取.
九 scrapy 文件输出参数
scrapy crawl quotes -o quotes-humor.json
'''
- o 把详情页返回结果,输入到文件
'''
初始scrapy,简单项目创建和CSS选择器,xpath选择器(1)的更多相关文章
- 王立平--java se的简单项目创建以及具体解释
创建项目的简单步骤: watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvdTAxMzQyNTUyNw==/font/5a6L5L2T/fontsize/400/ ...
- cube.js 学习(一)简单项目创建
cube.js 是一个很不错的模块化分析框架,基于schema生成sql 同时内置可代码生成,可以快速的搞定 web 分析应用的开发 安装cli 工具 npm install -g cubejs-cl ...
- Spring Cloud简单项目创建
一.Zuul 原文链接 Zuul的主要功能是路由转发和过滤器.路由功能是微服务的一部分,比如/api/user转发到到user服务,/api/shop转发到到shop服务.zuul默认和Ribbon结 ...
- 从0开始,手把手教你用Vue开发一个答题App01之项目创建及答题设置页面开发
项目演示 项目演示 项目源码 项目源码 教程说明 本教程适合对Vue基础知识有一点了解,但不懂得综合运用,还未曾使用Vue从头开发过一个小型App的读者.本教程不对所有的Vue知识点进行讲解,而是手把 ...
- scrapy简单入门及选择器(xpath\css)
简介 scrapy被认为是比较简单的爬虫框架,资料比较齐全,网上也有很多教程.官网上介绍了它的四种安装方法,PyPI.Conda.APT.Source,我们只介绍最简单的安装方法. 安装 Window ...
- Python -- Scrapy 框架简单介绍(Scrapy 安装及项目创建)
Python -- Scrapy 框架简单介绍 最近在学习python 爬虫,先后了解学习urllib.urllib2.requests等,后来发现爬虫也有很多框架,而推荐学习最多就是Scrapy框架 ...
- Windows 8.1 应用再出发 (WinJS) - 创建一个简单项目
前面几篇我们介绍了如何利用 C# + XAML 完成Windows Store App 功能的实现,接下来的几篇我们来看看如何利用 Html + WinJS 来完成这些功能. 本篇我们使用WinJS ...
- python爬虫框架—Scrapy安装及创建项目
linux版本安装 pip3 install scrapy 安装完成 windows版本安装 pip install wheel 下载twisted,网址:http://www.lfd.uci.edu ...
- m2eclipse简单使用,创建Maven项目 ,运行mvn命令(转)
前面介绍了如何安装m2eclipse,现在,我们使用m2ecilpse导入Hello World项目. 选择菜单项File,然后选择Import,我们会看到一个Import对话框,在该对话框中选择Ge ...
随机推荐
- 【转】怎么解决java.lang.NoClassDefFoundError错误 ,以及类的加载机制
转自http://blog.csdn.net/jamesjxin/article/details/46606307 前言 在日常Java开发中,我们经常碰到java.lang.NoClassDefFo ...
- SSM-Spring-20:Spring中事务基础
------------吾亦无他,唯手熟尔,谦卑若愚,好学若饥------------- 事务 事务是什么? 我记得当初的百度百科上讲,事务是执行的最小逻辑单元,它们要么都执行,要么都不执行 (同生共 ...
- PiggyMetrics windows 部署
PiggyMetrics 是springcloud的demo,其特性就不细说了,主要描述在win10下部署的坑. 官网是:https://github.com/sqshq/PiggyMetrics 官 ...
- linux安装vsftpd服务器
最近看到python的网络编程,看到用python写ftp客户端的小项目,打算着手连连.为了模仿真实环境,我并没有在本机上开个ftp服务器,选择了在虚拟机中的linux中做ftp服务器,我选择了vsf ...
- 自动化测试--protractor
前戏 面向模型编程: 测试驱动开发: 先保障交互逻辑,再调整细节.---by 雪狼. 为什么要自动化测试? 1,提高产出质量. 2,减少重构时的痛.反正我最近重构多了,痛苦经历多了. 3,便于新人接手 ...
- Hibernate验证器
第 4 章 Hibernate验证器 http://hibernate.org/validator/documentation/getting-started/#applying-constrain ...
- LeetCode Javascript实现 100. Same Tree 171. Excel Sheet Column Number
100. Same Tree /** * Definition for a binary tree node. * function TreeNode(val) { * this.val = val; ...
- Android监测手指上下左右滑动屏幕
在开发android程序时,有时会需要监测手指滑动屏幕,当手指朝上下左右不同方向滑动时做出不同的响应,那怎么去实现呢? 利用Android提供的手势监测器就可以很方便的实现,直接上代码(已测试通过) ...
- MongoDB与python交互
1.Pymongo PyMongo是Mongodb的Python接口开发包,是使用python和Mongodb的推荐方式.官方文档 2.安装 进入虚拟环境 sudo pip install pymon ...
- 问题(一) DebugAugmenter
问题: DebugAugmenter的作用是什么?是任何一个自创建的变量都可以取代它还是它有特定含义? public class DebugAugmenter Test { @Test public ...