python3 爬去QQ音乐
import requests
import re
import json
import os def get_name(singer):
url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp'
params = {
'catZhida': '',
'w': singer,
}
headers = {
'referer': 'https://y.qq.com/portal/search.html',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36'
}
html = requests.get(url,headers=headers,params=params).text
content = re.compile('callback\((.*)\)').findall(html)[0]
content = json.loads(content)
data = content.get('data')
song = data.get('song')
lists = song.get('list')
name = []
for list in lists:
singer = list.get('singer')[0].get('mid')
name.append(singer)
name = name[0]
return name def get_html(name,singer):
url = 'https://c.y.qq.com/v8/fcg-bin/fcg_v8_singer_track_cp.fcg'
params = {
'singermid': name,
'order': 'listen',
'begin': '',
'num': '',
}
headers = {
'referer': 'https://y.qq.com/n/yqq/singer/003aQYLo2x8izP.html',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36'
}
html = requests.get(url,headers=headers,params=params).text
return html def get_music(vkey,songname,filename,singer):
if vkey and songname:
url3 = 'http://dl.stream.qqmusic.qq.com/' + filename + '?vkey=' + vkey + '&guid=7133372870&uin=0&fromtag=66' headers = {
'referer': 'https://y.qq.com/n/yqq/singer/003aQYLo2x8izP.html',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36'
}
music = requests.get(url3,headers=headers).content
dir = singer
if not os.path.exists(dir):
os.mkdir(dir)
with open(dir+'/'+songname+'.m4a','wb') as f:
f.write(music)
print(songname,'__',singer) def get_vkey(strMediaMid,songmid,songname,singer):
if strMediaMid and songmid and songname :
url2 = 'https://c.y.qq.com/base/fcgi-bin/fcg_music_express_mobile3.fcg'
params = {
'g_tk': '',
'jsonpCallback': 'MusicJsonCallback8571665793949388',
'loginUin': '',
'hostUin': '',
'format': 'json',
'inCharset': 'utf8',
'outCharset': 'utf-8',
'notice': '',
'platform': 'yqq',
'needNewCode': '',
'cid': '',
'callback': 'MusicJsonCallback8571665793949388',
'uin': '',
'songmid': songmid,
'filename': 'C400'+ strMediaMid + '.m4a',
'guid': ''
}
headers = {
'referer': 'https://y.qq.com/portal/player.html',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36'
}
detail_html = requests.get(url2,headers=headers,params=params).text
vkey_disc = re.compile('MusicJsonCallback8571665793949388\((.*?)\)').findall(detail_html)[0]
vkey_disc = json.loads(vkey_disc) data = vkey_disc['data']
items = data.get('items')[0]
vkey = items.get('vkey')
get_music(vkey,songname,'C400'+ strMediaMid + '.m4a',singer) def get_list(detail_html,singer):
if detail_html:
lists = re.compile('data\":{\"list\":(.*?),\"singer_id',re.S).findall(detail_html)[0]
datas = json.loads(lists)
for data in datas:
musicData = data.get('musicData')
strMediaMid = musicData.get('strMediaMid')
songmid = musicData.get('songmid')
songname = musicData.get('songname')
get_vkey(strMediaMid,songmid,songname,singer) def main():
singer = input('请输入您想要下载的歌手:')
name = get_name(singer)
detail_html = get_html(name,singer)
get_list(detail_html,singer) if __name__ == '__main__':
main()
有些地方代码有些冗余,还可以再改进 但是费了些功夫终于爬出的效果 确实想要快点编辑出来 按耐不住小激动 这应该就是敲代码的乐趣
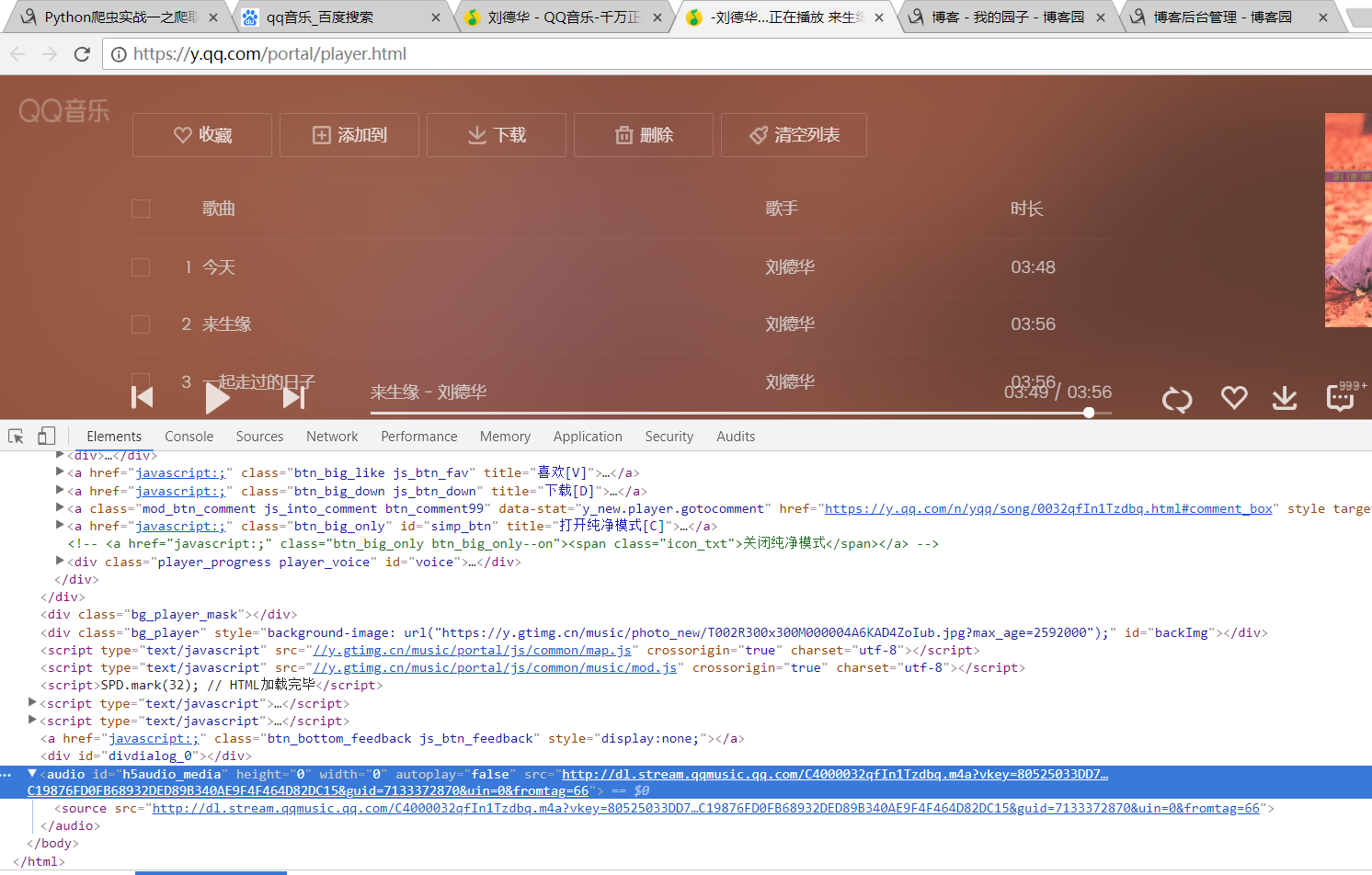
当播放一个音乐的时候 在Elements中 可以看到音乐的链接 当然是通过js 和 css 加载过的 但是 可以用逆向思维进行参数的找寻
http://dl.stream.qqmusic.qq.com/C4000032qfIn1Tzdbq.m4a?vkey=80525033DD719DAB87C0CEC7B4F9F40D8755982D3A495E3BA0810E50A89668A2AFD61C4C19876FD0FB68932DED89B340AE9F4F464D82DC15&guid=7133372870&uin=0&fromtag=66
发现 vkey 是一个很重要的参数 所以就先去翻一翻网页查一下vkey在哪
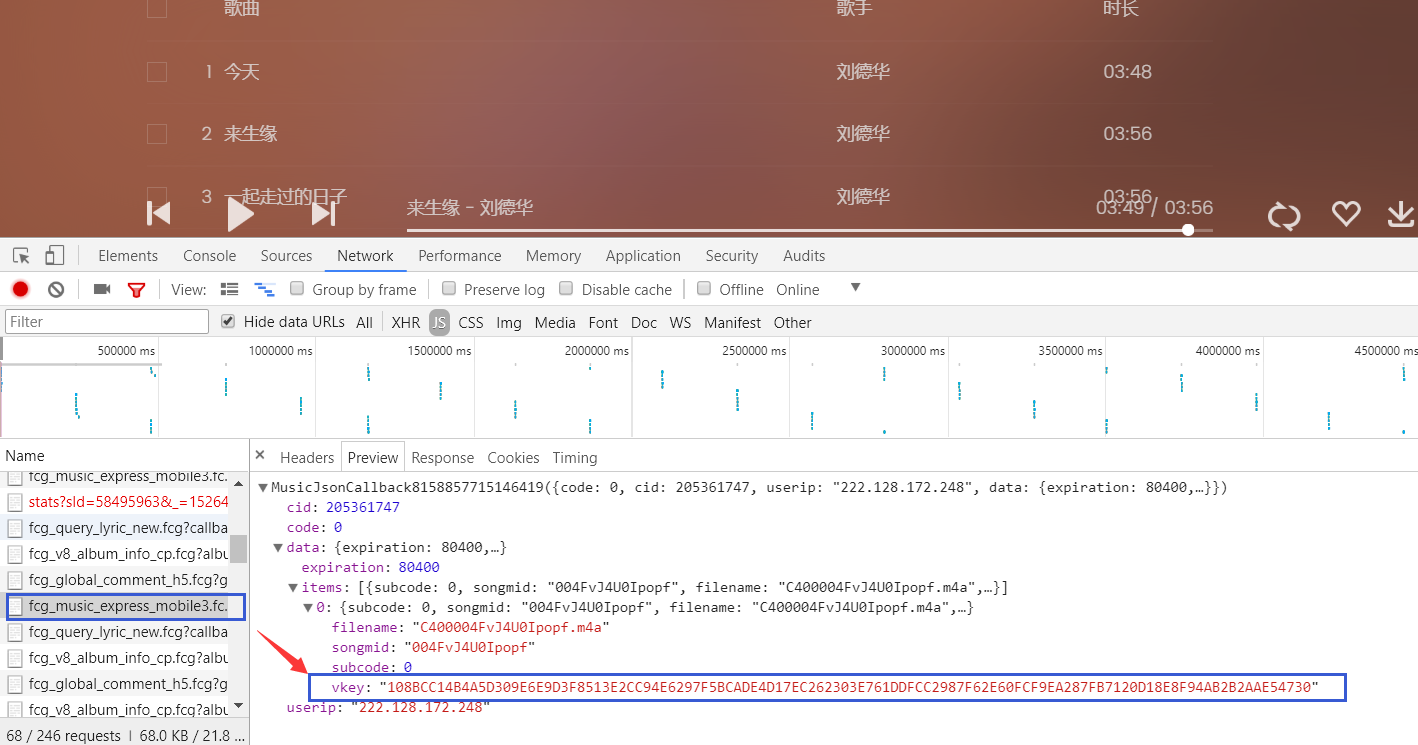
经发现 在同播放页面的JS中 但是如果想获得vkey 就需要访问这个对应的URL 也要找到相应的参数
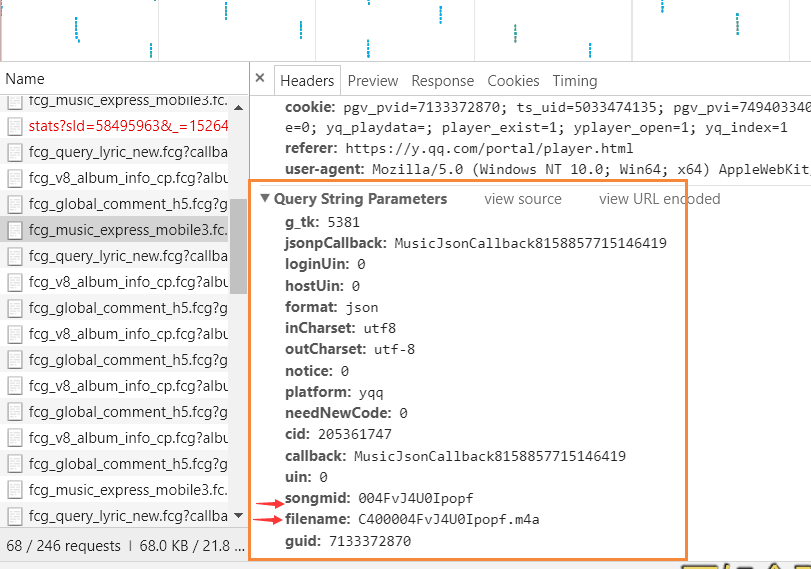
标红箭头的是一直在变化而且没有不行的参数
所以将继续往里使劲挖!
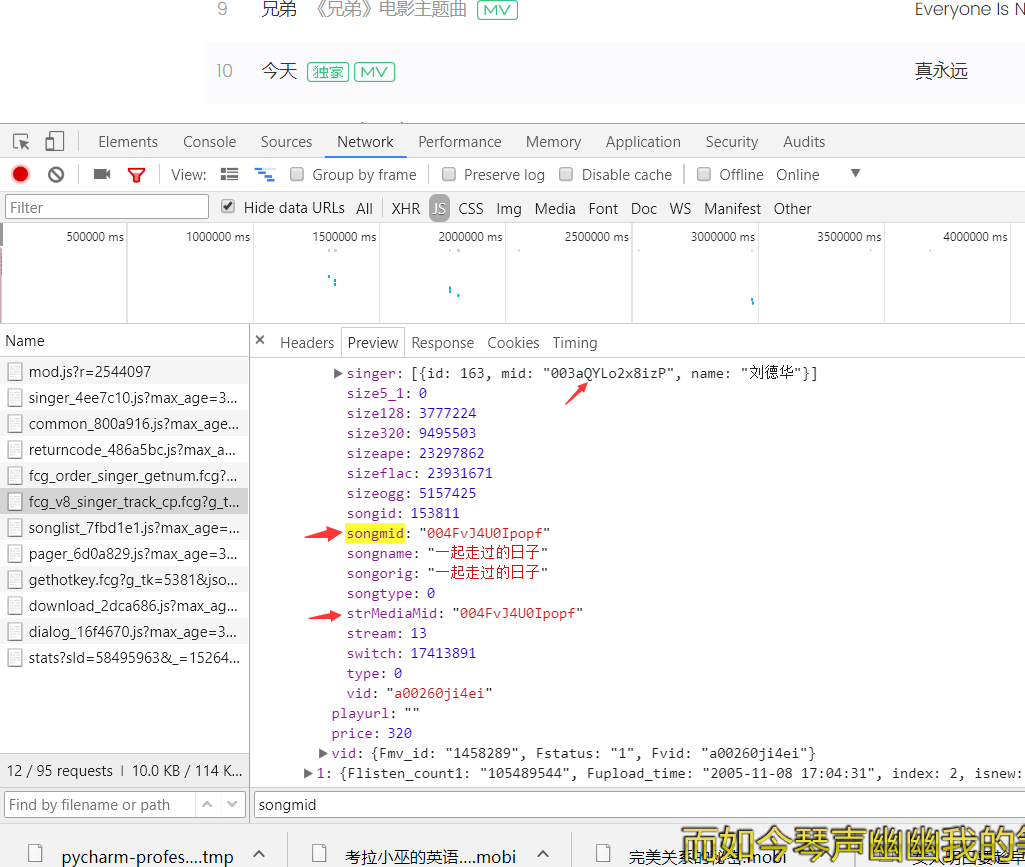
目前处于列表页 发现参数已经浮现
但发现第一个红箭头是歌手的意思 被不知道用了什么样的格式换了一种形式 因为后续还想通过段小乱码找到每个歌手所对应的歌曲 所以 还是找到每个歌手所对应的小乱码比较好
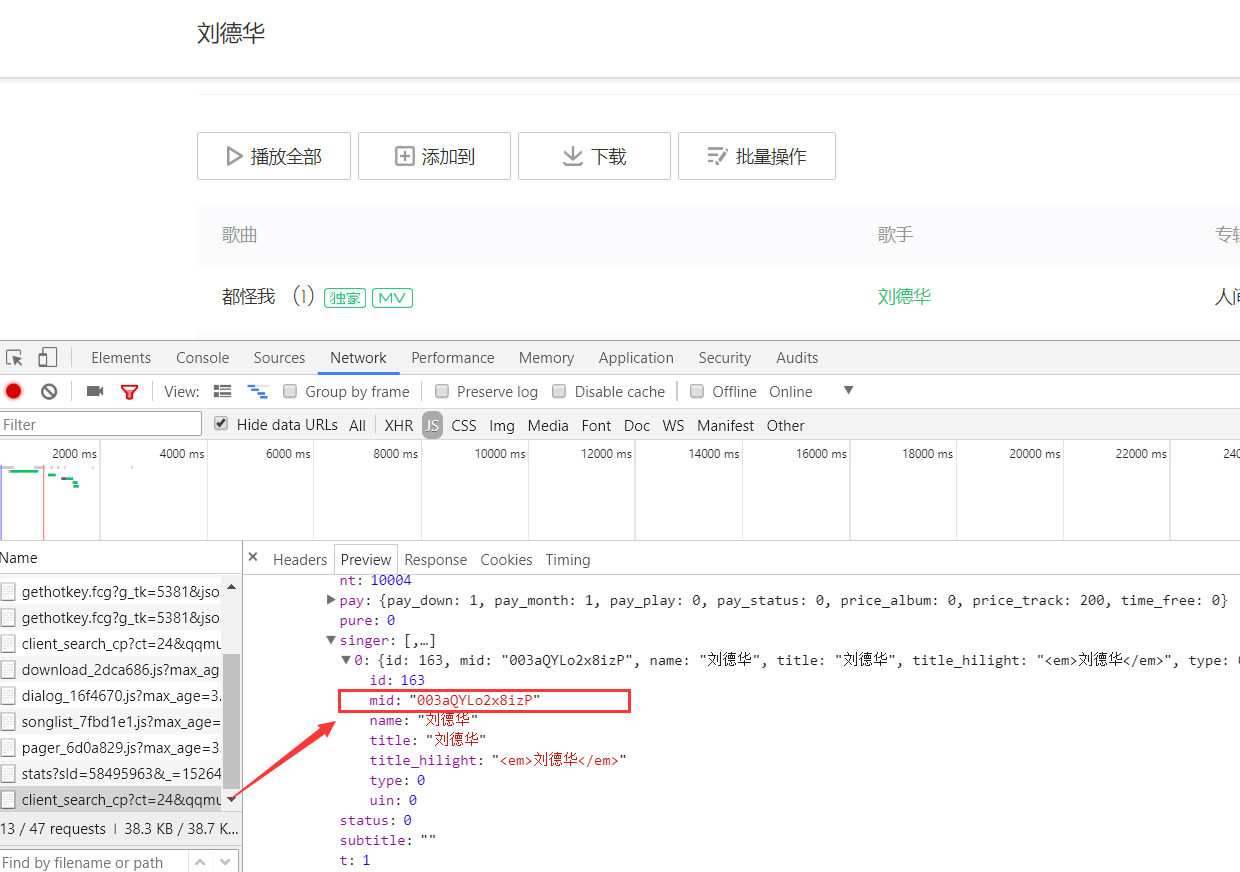
找到了!!!
但是 写代码的话 要用正向思维来写 Year!
python3 爬去QQ音乐的更多相关文章
- python3 爬取qq音乐作者所有单曲 并且下载歌曲
1 import requests import re import json import os # 便于存放作者的姓名 zuozhe = [] headers = {'User-Agent': ' ...
- Python爬虫实战一之爬取QQ音乐
一.前言 前段时间尝试爬取了网易云音乐的歌曲,这次打算爬取QQ音乐的歌曲信息.网易云音乐歌曲列表是通过iframe展示的,可以借助Selenium获取到iframe的页面元素, 而QQ音乐采用的是 ...
- 爬取QQ音乐(讲解爬虫思路)
一.问题描述: 本次爬取的对象是QQmusic,为自己后面做django音乐网站的开发获取一些资源. 二.问题分析: 由于QQmusic和网易音乐的方式差不多,都是讲歌曲信息放入到播放界面播放,在其他 ...
- 爬取QQ音乐歌手的歌单
import requests# 引用requests库res_music = requests.get('https://c.y.qq.com/soso/fcgi-bin/client_search ...
- python3爬取咪咕音乐榜信息(附源代码)
参照上一篇爬虫小猪短租的思路https://www.cnblogs.com/aby321/p/9946831.html,继续熟悉基础爬虫方法,本次爬取的是咪咕音乐的排名 咪咕音乐榜首页http://m ...
- 爬取qq音乐巅峰榜---内地音乐的榜单
import requestsimport jsonimport sys for i in range(0,10): url = "https://szc.y.qq.com/v8/fcg-b ...
- 手把手教你使用Python抓取QQ音乐数据(第一弹)
[一.项目目标] 获取 QQ 音乐指定歌手单曲排行指定页数的歌曲的歌名.专辑名.播放链接. 由浅入深,层层递进,非常适合刚入门的同学练手. [二.需要的库] 主要涉及的库有:requests.json ...
- 手把手教你使用Python抓取QQ音乐数据(第二弹)
[一.项目目标] 通过Python爬取QQ音乐数据(一)我们实现了获取 QQ 音乐指定歌手单曲排行指定页数的歌曲的歌名.专辑名.播放链接. 此次我们在之前的基础上获取QQ音乐指定歌曲的歌词及前15个精 ...
- Python Scrapy的QQ音乐爬虫 音乐下载、爬取歌曲信息、歌词、精彩评论
QQ音乐爬虫(with scrapy)/QQ Music Spider UPDATE 2019.12.23 已实现对QQ音乐文件的下载,出于版权考虑,不对此部分代码进行公开.此项目仅作为学习交流使用, ...
随机推荐
- android 高仿京东
android 高仿京东源码,两年前的作品,最近发现一些老代码,发布出来给初学者学习,下面附上几张展示的效果,有需要的请到下面地址下载,记得stare哦 https://github.com/xian ...
- RTMPdump(libRTMP) 源代码分析 10: 处理各种消息(Message)
===================================================== RTMPdump(libRTMP) 源代码分析系列文章: RTMPdump 源代码分析 1: ...
- Linux - vim按键说明
第一部份:一般模式可用的按钮说明,光标移动.复制贴上.搜寻取代等 移动光标的方法 h 或 向左箭头键(←) 光标向左移动一个字符 j 或 向下箭头键(↓) 光标向下移动一个字符 k 或 向上箭头键(↑ ...
- Socket层实现系列 — bind()的实现(二)
本文主要内容:bind()的TCP层实现.端口的冲突处理,以及不同内核版本的实现差异. 内核版本:3.6 Author:zhangskd @ csdn blog TCP层实现 SOCK_STREAM套 ...
- objc一个NetConnector类示例
NetConnector是自定义的一个类,该类使用代理的方法实现异步下载特定url页面的内容. HyNetConnector.h // // HyNetConnector.h // HyNetConn ...
- Mybatis源码之CallableStatementHandler
/** * @author Clinton Begin */ public class CallableStatementHandler extends BaseStatementHandler { ...
- SharePoint 2010 电子书下载网站推荐
最近一直搜集SharePoint2010的资料,偶尔发现一个网站还不错,推荐给大家,皮皮书屋http://www.ppurl.com/tag/sharepoint,里面有很多SharePoint201 ...
- Git学习备忘
本文参考廖雪峰写的精彩的git学习文档,大家可以直接去官网看原版,我这里只是便于自己记录梳理 原版地址:http://www.liaoxuefeng.com/wiki/0013739516305929 ...
- Configure the MySQL account associate to the domain user via MySQL Windows Authentication Plugin
在此记录如何将之前一次做第三发软件在配置的过程. 将AD user通过代理映射到mysql 用户. 在Mysql官网有这样一段话: The server-side Windows authentica ...
- IOS常用第三方库《转》
UI 动画 网络相关 Model 其他 数据库 缓存处理 PDF 图像浏览及处理 摄像照相视频音频处理 响应式框架 消息相关 版本新API的Demo 代码安全与密码 测试及调试 AppleWatch ...