高性能MySQL-索引
创建索引-高效索引
1.1 索引初体验
1.1.1 介绍
索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。
索引的作用是做数据的快速检索,而快速检索的实现的本质是数据结构。通过不同数据结构的选择,实现各种数据快速检索。在数据库中,高效的查找算法是非常重要的,因为数据库中存储了大量数据,一个高效的索引能节省巨大的时间。
1.1.2 索引类型
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
推荐使用上面的网站来可视化查看各种数据结构
B-Tree索引
尽管名称为B-Tree索引,但事实上,其不同引擎对其内部实现结构还是会不一样,Inno DB使用的是B+Tree这种结构来存储索引
注意: InnoDB 的数据文件本身就是索引文件 即
表数据文件本身就是按 B+Tree 组织的一个索引结构,这棵树的叶点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此 InnoDB 表数据文件本身就是主索引。
对于MyISAM引擎,其采用了非聚集索引的方式来实现
即数据和索引落在不同的两个文件上。MyISAM 在建表时以主键作为 KEY 来建立主索引 B+树,非叶子结点只存储下一节点的指针,树的叶子节点存的是对应数据的物理地址。我们拿到这个物理地址后,就可以到 MyISAM 数据文件中直接定位到具体的数据记录了。
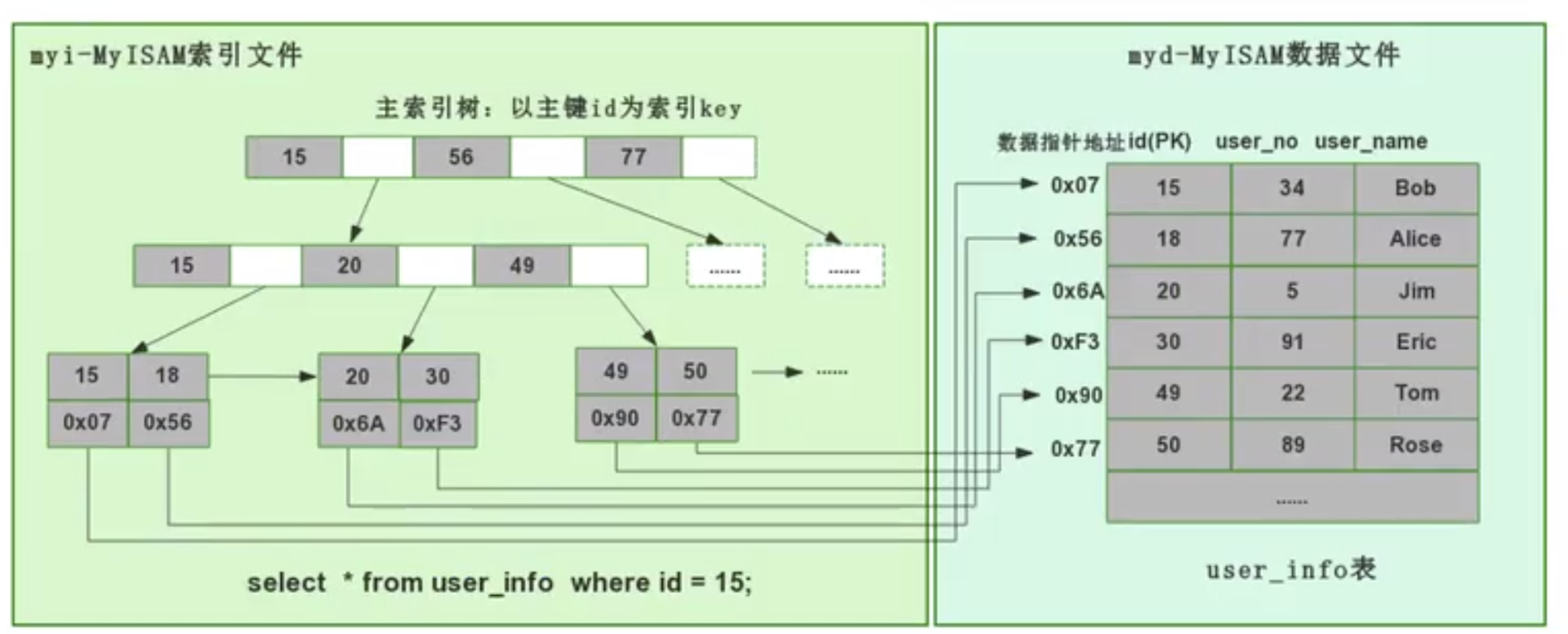
对于InnoDB引擎,其使用聚集索引的方式来建表
即数据和索引都存储在同一个文件 ,对于InnoDB使用的B+Tree结构,其非叶子节点是不存储数据的,只存储索引,所有的数据都存储在叶子节点页,并且叶子节点存储的是主键ID对应的数据,这也是为什么Mysql在建表时要求必须指定主键的原因。由于数据真正的排序方式只能有一种,所以在每张表中只能存在着一个以主键为索引的聚集索引。 因此上面我们才说了InnoDB的数据文件就是索引文件

注意:InnoDB只在主键索引树的叶子节点存储了具体数据,但是其他索引树却不存具体数据,而要先找到主键,再在主键索引树找到对应的数据。 别问,问就是节省空间,拿时间换空间。这也证明了选择合适的主键的重要性。
B+Tree索引查询类型:
全值匹配
和索引中的所有列进行匹配,例如key(A,B,C),匹配(A,B,C)
匹配最左前缀
例如key(A,B,C),可以匹配(A) (A,B) (A,B,C)
匹配列前缀
例如数据changtong,加上索引后可以匹配(c*),这也就是为什么我们对某一添加了索引的列使用模糊查询时like a% 就会使用索引,如果是%a就只能够完全检索了
匹配范围值
B-tree索引是顺序存储数据的,因此能够使用索引进行范围匹配
精确匹配某一列并范围匹配另外一列
例如key(A,B)可以匹配(A,B*)
只访问索引的查询
这里主要是覆盖索引,只访问索引,不访问数据行
Hash索引
顾名思义,使用哈希表实现,这也就意味着其只有对精确匹配才有效,这个实现有点像HashMap,根据数据的Hash值确定位置,这里索引只存哈希值和行指针,不存数据,由于Hash算法的特点,也无法排序
InnoDB一般不使用Hash索引,但是其有一项功能叫“自适应哈希索引”,当它发现某些数据访问非常频繁,可能会基于B-Tree的基础上再创建一个Hash索引,该过程自发且不可控,可以选择关闭。
综上所述,对于使用InnoDB引擎的我们来说,Hash索引了解一下就好了,不过这也给我们提供了一个思路,例如我们存储网络链接这样的无序长字符串,是不是可以使用上Hash算法?我们可以新建一列url_hash,存放该链接对应的Hash值,然后我们对该Hash值建立索引,就能得到更好的查询体验了,在查询时使用以下查询语句即可
select id from url where url="http://changtong1819.top"
and url_hash = CR32("http://changtong1819.top")
当然,缺点是我们可能需要使用触发器等工具维护我们的Hash值
空间索引
MyISAM支持该索引
全文索引
全文索引是一种特殊类型的索引,它查找的是文本中的关键词,而不是简单的where
1.2 索引的优点
索引可以让服务器快速地定位到表的指定位置。但是这并不是索引的唯一作用,到目前为止可以看到,根据创建索引的数据结构不同,索引也有一些其他的附加作用。
最常见的B-Tree索引,由于其按照顺序存储数据,所以 MySQL可以用来做ORDER BY和GROUPBY操作。因为数据是有序的,所以B-Tree也就会将相关的列值都存储在一起。
最后,因为索引中存储了实际的列值,所以某些查询只使用索引就能够完成全部查询。据此特性,总结下来索引有如下三个优点:
- 索引大大减少了服务器需要扫描的数据量。
- 索引可以帮助服务器避免排序和临时表。
- 索引可以将随机IO变为顺序IO。
注意:索引并非总是好的解决方案
只有当索引帮助存储引擎快速查找到记录带来的好处大于其带来的额外工作时,索引才是有效的。对于非常小的表,大部分情况下简单的全表扫描更高效。对于中到大型的表,索引就非常有效。但对于特大型的表,建立和使用索引的代价将随之增长。这种情况下,则需要一种技术可以直接区分出查询需要的一组数据,而不是一条记录一条记录地匹配。例如可以使用分区技术。
1.3 高性能索引
1.3.1 独立的列
如果查询的列不是独立的,则不会使用索引。独立的列意味着索引列不能是表达式、函数的一部分
例如:
select id from user where id + 1 = 10
尽管上面的写法看着很智障,但貌似我以前好像写过这样的查询语句,靠!总而言之,能在业务层简化就尽量简化,直接写id = 9就会使用索引了。
1.3.2 前缀索引和索引选择性
当我们需要索引长字符串怎么办?这会让索引变得大且慢,前面提到了仿Hash索引是一个思路,也有其它类似方法,总而言之就是简化索引字段长度
我们如果存储了一列全是类似"changtong1819hahahahahahahahhhehehehehhehehexixixiixixii "这样的长数据列的话,我们可以增加一列,这一列只保存上面数据列中的前10个字符,对该列添加索引,在查询时匹配这两列能够极大的提高查询速度。
那么问题来了,具体截取多少个字符呢?什么是索引选择性?
对于我们上面的例子来说,截取太长,匹配效果好,但是既然这个索引还是长,那我要它干嘛?截取太短的话,就会导致我们该索引的相同值太多了,我们知道B-Tree好就好在其实顺序存储的,当相同值越多,就导致索引效果会越差,即选择性差。因此,我们要权衡两种效果来选择合适的长度,这肯定是和实际数据库的存放数据相关了。
1.3.3 多列索引
我们知道,每创建一个索引字段就会产生一个B-Tree来存储对应的索引,那么我们分别对两个字段创建了索引会有什么效果?我们该如何查询呢?
MySQL引入了索引合并策略,在一定程度上可以帮助我们通过多个单列索引来定位到指定的数据,当然,尽管有该策略,我们应该也能想到其效率也不会有多高。这是MySQL对我们的查询操作进行的优化,但是我们要尽量创建合适的索引。
1.3.4 索引列顺序
我们遇到的最容易引起困惑的问题就是索引列的顺序。正确的顺序有利于使用该索引的查询,并且同时需要考虑如何更好地满足排序和分组的需要。当然,这一切都是在于我们使用了B-Tree这种顺序存储结构的情况下
通常情况下我们将选择性最高的列放在索引的最前列,这有利于我们的where语句。但考虑到其他情况的话,这样做就可能不是最好的选择了。我们使用where语句时,要充分考虑到联合索引的执行与否。
1.3.5 聚簇索引
聚簇索引并不是一种索引类型,而是一种数据存储方式,前面提到过了,InnoDB的聚簇索引即是在一个结构中保存了索引与数据行。
如果没有定义主键,InnoDB会选择一个唯一的非空索引代替。如果没有这样的索引,InnoDB会隐式定义一个主键来作为聚簇索引。InnoDB 只聚集在同一个页面中的记录。包含相邻键值的页面可能会相距甚远。
注意:InnoDB只会对主键索引才回使用聚簇索引这一存储方式,同时InnoDB表数据的保存形式其实就是对主键的聚簇索引。即对于InnoDB,聚簇索引就是表。
我们平时手动创建的索引称为二级索引,而通过二级索引查找行,存储引擎需要找到二级索引的叶子节点获得对应的主键值(二级索引没有行数据),然后根据这个值去聚簇索引中查找到对应的行。对于InnoDB,自适应哈希索引能够减少这样的重复工作。
在InnoDB表中按主键顺序插入行
如果正在使用InnoDB表并且没有什么数据需要聚集,那么可以定义一个代理键(surrogate key)作为主键,这种主键的数据应该和应用无关,最简单的方法是使用AUTO_INCREMENT自增列。这样可以保证数据行是按顺序写入,对于根据主键做关联操作的性能也会更好。
最好避免随机的(不连续且值的分布范围非常大)聚簇索引,特别是对于IО密集型的应用。例如,从性能的角度考虑,使用UUID来作为聚簇索引则会很糟糕:它使得聚簇索引的插入变得完全随机,这是最坏的情况,使得数据没有任何聚集特性。
使用InnoDB时应该尽可能地按主键顺序插入数据,并且尽可能地使用单调增加的聚簇键的值来插入新行。
1.3.6 覆盖索引
如果索引的叶子节点中已经包含要查询的数据,那么就不需要再回表查询
如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。
MySQL不能在索引中执行LIKE操作。这是底层存储引擎API的限制,MySQL 5.5和更早的版本中只允许在索引中做简单比较操作(例如等于、不等于以及大于)。
MySQL 能在索引中做最左前缀匹配的LIKE比较,因为该操作可以转换为简单的比较操作,但是如果是通配符开头的LIKE查询,存储引擎就无法做比较匹配。这种情况下,MySQL服务器只能提取数据行的值而不是索引值来做比较。
1.3.7 使用索引扫描
MySQL有两种方式可以生成有序的结果:通过排序操作;或者按索引顺序扫描。
扫描索引本身是很快的,因为只需要从一条索引记录移动到紧接着的下一条记录。但如果索引不能覆盖查询所需的全部列,那就不得不每扫描一条索引记录就都回表查询一次对应的行。这基本上都是随机I/o,因此按索引顺序读取数据的速度通常要比顺序地全表扫描慢,尤其是在IO密集型的工作负载时。
MySQL可以使用同一个索引既满足排序,又用于查找行。因此,如果可能,设计索引时应该尽可能地同时满足这两种任务,这样是最好的。
注意:只有当索引的列顺序和ORDER BY子句的顺序完全一致,并且所有列的排序方向(倒序或正序)都一样时,MySQL才能够使用索引来对结果做排序。如果查询需要关联多张表,则只有当ORDER BY子句引用的字段全部为第一个表时,才能使用索引做排序。ORDER BY子句和查找型查询的限制是一样的:需要满足索引的最左前缀的要求。
1.3.8 压缩索引
MyISAM使用前缀压缩来减少索引的大小,从而让更多的索引可以放入内存中,这在某些情况下能极大地提高性能。默认只压缩字符串,但通过参数设置也可以对整数做压缩。
1.3.9 冗余和重复索引
MySQL允许在相同列上创建多个索引,无论是有意的还是无意的。MySQL需要单独维护重复的索引,并且优化器在优化查询的时候也需要逐个地进行考虑,这会影响性能。
重复索引是指在相同的列上按照相同的顺序创建的相同类型的索引。应该避免这样创建重复索引,发现以后也应该立即移除。
通常情况下,我们不会写出两个KEY(A)这样的索引。但是像主键、外键MySQL会自动创建索引,我们再去添加索引就会导致重复了。至于冗余索引,我们创建了KEY(A,B)之后在创建KEY(A)就很明显冗余了。
1.3.10 未使用的索引
有些索引可能从未被使用,可以用工具查看,然后删除
1.3.11 索引和锁
索引可以让查询锁定更少的行。如果你的查询从不访问那些不需要的行,那么就会锁定更少的行,从两个方面来看这对性能都有好处。首先,虽然InnoDB的行锁效率很高,内存使用也很少,但是锁定行的时候仍然会带来额外开销﹔其次,锁定超过需要的行会增加锁争用并减少并发性。
MySQL 5.1之后,InnoDB可以在服务端过滤掉行之后就释放锁,此前版本需要事务提交后才释放锁
如果不能使用索引查找和锁定行的话,MySQL会做全表扫描并锁住所有的行,而不管是不是需要。
InnoDB在二级索引上使用共享(读)锁,但访问主键索引需要排他(写)锁。
1.4 合理使用索引
1.4.1 支持多种过滤条件
创建索引时我们需要考虑哪些列拥有很多不同的取值,哪些列在WHERE子句中出现得最频繁。在有更多不同值的列上创建索引的选择性会更好。一般来说这样做都是对的,因为可以让MySQL更有效地过滤掉不需要的行。
像性别这样的选择性就两个的字段,单独添加个索引毫无必要,索引的最主要目的就是快速查找、定位数据。而性别这样的数据在表中的定位性比较差,即便加上索引,优化器也是会认为此索引使用的成本过高,而不会使用索引。
但并不是性别就一定不能成为索引字段,如果该表经常出现性别和其他字段往往同时出现在where后面,那么你可以将性别和其他字段作为联合索引。即能够帮助我们多过滤一些数据行还是好的。
1.4.2 避免多范围条件
前面我们提到了,InnoDB使用B+Tree作为索引存储结构,而这是一种顺序存储结构,因此InnoDB是支持索引的范围匹配的,但是这并不意味着我们可以随意在where后面添加多个范围匹配。
不过我尝试了几种多范围条件的查询,发现都使用了索引
1.4.3 优化排序
对于那些选择性非常低的列,可以增加一些特殊的索引来做排序。例如,可以创建(sex,x)索引用于对x字段和性别字段的查询。
高性能MySQL-索引的更多相关文章
- 如何构建高性能MySQL索引
本文的重点在于如何构建一个高性能的MySQL索引,从中你可以学到如何分析一个索引是不是好索引,以及如何构建一个好的索引. 索引误区 多列索引 一个索引的常见误区是为每一列创建一个索引,如下面创建的索引 ...
- MySQL索引基础知识点
什么是索引 索引类似于书本目录,是数据库存储引擎维护的用于快速查找到记录的一种数据结构,它是对查询性能优化的最有效手段. MySQL索引是在存储引擎层而不是服务器层实现的,不同存储引擎的索引工作方式也 ...
- 高性能MySQL笔记 第5章 创建高性能的索引
索引(index),在MySQL中也被叫做键(key),是存储引擎用于快速找到记录的一种数据结构.索引优化是对查询性能优化最有效的手段. 5.1 索引基础 索引的类型 索引是在存储引擎层而 ...
- mysql笔记02 创建高性能的索引
创建高性能的索引 1. 索引(在MySQL中也叫做"键(key)")是存储引擎用于快速找到记录的一种数据结构. 2. 索引可以包含一个或多个列的值.如果索引包含多个列,那么列的顺序 ...
- 高性能Mysql笔记 — 索引
index优化 对于频繁作为查询条件的字段使用索引 注意索引字段类型的隐式转换,数据库类型和应用类型要一致 索引的种类 唯一索引,成为索引的列不能重复 单列索引,一个索引只包含一列 单列前缀索引,有些 ...
- 高性能MySQL中的三星索引
高性能MySQL中的三星索引 我对此提出了深深的疑问: 一星:相关的记录指的是什么??(相关这个词很深奥,“相关部门”是什么部门) 二星:如果建立了B-Tree(B+Tree)索引,数据就有序了.三星 ...
- 高性能mysql:创建高性能的索引
本文系阅读<高性能MySQL>,Baron Schwartz等著一书中第五章 创建高性能的索引的笔记,索引是存储引擎用于快速找到记录的一种数据结构. 索引对于良好的性能非常关键,尤其是当表 ...
- MySQL实战 | 05 如何设计高性能的索引?
原文链接:MySQL | 05 如何设计高性能的索引? 上回我们主要研究了为什么使用索引,以及索引的数据结构.今天带你了解如何设计高性能的索引. 其中,有这么一个点,说的是 InnoDB 引擎中使用的 ...
- 《高性能MySQL》读书笔记之创建高性能的索引
索引是存储引擎用于快速找到记录的一种数据结构.索引优化是对查询性能优化的最有效手段.索引能够轻易将查询性能提高几个数量级.创建一个最优的索引经常需要重写查询.5.1 索引基础 在MySQL中,存储引擎 ...
- 高性能mysql——高性能索引策略
<高性能MySQL>读书笔记 一. 索引的优点 1. 索引可以让服务器快速定位到表的指定位置,大大减少了服务器需要扫描的数量: 2. 最常见的B-Tree索引按照顺序存储数据,可以用来做o ...
随机推荐
- Matplotlib图例中文乱码
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 plt.rcParams['axes.unicode_minus']=False #用来正 ...
- Flutter学习简记
StatefulWidget和StatelessWidget StatefulWidget : 具有可变状态的窗口部件,也就是你在使用应用的时候就可以随时变化,比如我们常见的进度条,随着进度不断变化. ...
- 一个名叫Sentinel-Rules-SDK的组件,使得Sentinel的流控&熔断规则的配置更加方便
原文链接:一个名叫Sentinel-Rules-SDK的组件,使得Sentinel的流控&熔断规则的配置更加方便 1 Sentinel 是什么? 随着微服务的流行,服务和服务之间的稳定性变得越 ...
- ajax函数
使用三个函数是按ajax请求的处理 1.$.ajax() jQuery中实现ajax的核心函数 2.$.post() 使用post方式做ajax请求 3.$.get 使用get方式做ajax请求 $. ...
- go语言的初体验
分享最近学习 Go 语言的心得和体会,适合有编程基础的人,因为这里只做经验性的总结概述,不做基础教学的入门知识讲解,如果想要学习编程语言的基础知识,请出门左转进入官方文档,查看基础教学文档. Go 概 ...
- Android Studio 之生成正式签名的 APK 文件
生成 APK 文件 •步骤 点击 Build -> Generate Signed...... : 来到如下界面: 选择 APK 选项,点击 Next 来到如下界面: 如果你电脑上没有一个正式 ...
- IT培训有哪些坑(二)?
今天继续给大家分享一下IT培训都有哪些坑?有哪些不靠谱? 做招转的不靠谱.什么是招转?就是招聘转招生,名义上说的是招聘,但实际上做的就是招生.有很多大学刚毕业的计算机相关专业的同学,他们大学毕业之后, ...
- Elasticsearch中最重要的文档CRUD要牢记
Elasticsearch文档CRUD要牢记 转载参考:https://juejin.im/post/5ddbf298e51d4523053c42e7 在Elasticsearch中,文档(docum ...
- redis的线程模型
一.单进程模型来处理客户端的请求 Redis 基于 Reactor 模式开发了自己的网络事件处理器: 这个处理器被称为文件事件处理器(file event handler): 文件事件处理器是单线程的 ...
- Java读取图片exif信息实现图片方向自动纠正
起因 一个对试卷进行OCR识别需求,需要实现一个功能,一个章节下的题目图片需要上下拼接合成一张大图,起初写了一个工具实现图片的合并,程序一直很稳定的运行着,有一反馈合成的图片方向不对,起初怀疑是本身图 ...