Redis 源码简洁剖析 03 - Dict Hash 基础
Redis Hash 源码
- dict.h:定义 Hash 表的结构、哈希项,和 Hash 表的各种函数操作
- dict.c:函数的具体实现
Redis Hash 数据结构
在 dict.h 文件中,Hash 表是一个二维数组(dictEntry **table)。
typedef struct dictht {
// 二维数组
dictEntry **table;
// Hash 表大小
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
dictEntry **table 是个二维数组,其中第一维是 bucket,每一行就是 bucket 指向的元素列表(因为键哈希冲突,Redis 采用了链式哈希)。

为了实现链式哈希,Redis 的 dictEntry 结构中,除了包含键和值的指针,还包含了一个指向下一个哈希项的指针 next。
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
整体的哈希流程都是老生常谈了,和 Java 几乎是一样的,这里就不叙述了。
Redis rehash 原理
为什么要 rehash?
为了性能。如果哈希表 bucket 的数量是 1,但是里面有了 1000 个元素,不管怎么样都变成了一个链表,查询效率变得很低。同理,当哈希表里元素的个数比 bucket 数量多很多的时候,效率也会低很多。
Redis dict 数据结构
Redis 实际使用的是 dict 数据结构,内部用两个 dictht(ht[0] 和 ht[1]),用于 rehash 使用。
typedef struct dict {
……
// 两个 Hash 表,交替使用,用于 rehash 操作
dictht ht[2];
// Hash 表是否进行 rehash 的标识,-1 表示没有进行 rehash
long rehashidx;
……
} dict;
Redis rehash 过程
- 正常请求阶段,所有的键值对都写入哈希表 ht[0]
- 进行 rehash 时,键值对被迁移到 ht[1]
- 迁移完成后,是否 ht[0] 空间,把 ht[1] 的地址赋值给 ht[0],ht[1] 的表大小设置为 0

什么时候触发 rehash?
- ht[0] 大小=0
- ht[0] 里的元素个数已经超过 ht[0] 大小 && Hash 表可以扩容
- ht[0] 里的元素个数,是 ht[0] 大小的 5 倍(dict_force_resize_ratio)(类似于 Java 里 HashMap 的负载因子)
static int _dictExpandIfNeeded(dict *d)
{
/* Incremental rehashing already in progress. Return. */
if (dictIsRehashing(d)) return DICT_OK;
// Hash 表为空,将 Hash 表扩展为初始大小 DICT_HT_INITIAL_SIZE(4)
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
// Hash 表当前的元素数量超过表的大小 && (可以扩容 || 当前数量是表大小的 5 倍以上)
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio) &&
dictTypeExpandAllowed(d))
{
return dictExpand(d, d->ht[0].used + 1);
}
return DICT_OK;
}
上面代码中有个参数 dict_can_resize,设置函数为:
void dictEnableResize(void) {
dict_can_resize = 1;
}
void dictDisableResize(void) {
dict_can_resize = 0;
}
这两个函数被封装在了 server.c 中的 updateDictResizePolicy:
void updateDictResizePolicy(void) {
if (!hasActiveChildProcess())
dictEnableResize();
else
dictDisableResize();
}
/* Return true if there are active children processes doing RDB saving,
* AOF rewriting, or some side process spawned by a loaded module. */
int hasActiveChildProcess() {
return server.child_pid != -1;
}
我们可以看到,hasActiveChildProcess 函数是判断 Redis 存在 RDB 子进程、AOF 子进程是否存在。可以看到 dict_can_resize 只有在不存在 RDB 子进程、AOF 子进程时才为 TRUE。
那 _dictExpandIfNeeded 是在哪里调用的呢?
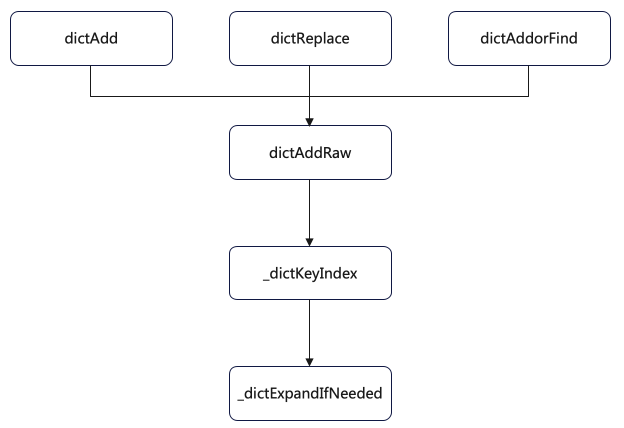
rehash 扩容多大?
_dictExpandIfNeeded 里调用了扩容函数 dictExpand。
/* return DICT_ERR if expand was not performed */
int dictExpand(dict *d, unsigned long size) {
return _dictExpand(d, size, NULL);
}
int _dictExpand(dict *d, unsigned long size, int* malloc_failed)
{
……
dictht n; /* the new hash table */
unsigned long realsize = _dictNextPower(size);
……
}
里面有一个 _dictNextPower 函数,啥都不说了,都在注释里。
static unsigned long _dictNextPower(unsigned long size) {
unsigned long i = DICT_HT_INITIAL_SIZE;
// 要扩容的大小已经超过了最大值
if (size >= LONG_MAX) return LONG_MAX + 1LU;
// 要扩容的大小没有超过最大值,找到第一个比 size 大的 2^i
while (1) {
if (i >= size)
return i;
i *= 2;
}
}
渐进式 rehash
为什么需要渐进式 rehash?
Hash 表空间很大,全量 rehash 时间会很长,阻塞 Redis 主线程。为了降低 rehash 开销,Redis 使用了「渐进式 rehash」。
具体一点
渐进式 rehash 并不是一次性把当前 Hash 表的所有键,都拷贝到新的位置,而是「分批拷贝」,每次只拷贝 Hash 表中一个 bucket 中的哈希项。
int dictRehash(dict *d, int n) {
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
// 循环 n 次后停止,或 ht[0] 迁移完成
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
assert(d->ht[0].size > (unsigned long) d->rehashidx);
// 如果要迁移的 bucket 中没有元素
while (d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
// 获取待迁移的 ht[0] 的 bucket
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while (de) {
uint64_t h;
// 获取下一个迁移项
nextde = de->next;
// 计算 de 在 ht[1](扩容后)中的位置
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
// 将当前的哈希项放到扩容后的 ht[1] 中
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
//指向下一个哈希项
de = nextde;
}
// 当前 bucket 已经没有哈希项了,将该 bucket 设置为 null
d->ht[0].table[d->rehashidx] = NULL;
// 将 rehash+1,下次迁移下一个 bucket
d->rehashidx++;
}
// 判断 ht[0] 是否已经全部迁移
if (d->ht[0].used == 0) {
// ht[0] 已经全部迁移到 ht[1] 了,释放 ht[0]
zfree(d->ht[0].table);
// ht[0] 指向 ht[1]
d->ht[0] = d->ht[1];
// 重置 ht[1] 大小为 0
_dictReset(&d->ht[1]);
//设置全局哈希表的 rehashidx=-1,表示 rehash 结束
d->rehashidx = -1;
return 0;
}
// ht[0] 中仍然有元素没有迁移完
return 1;
}
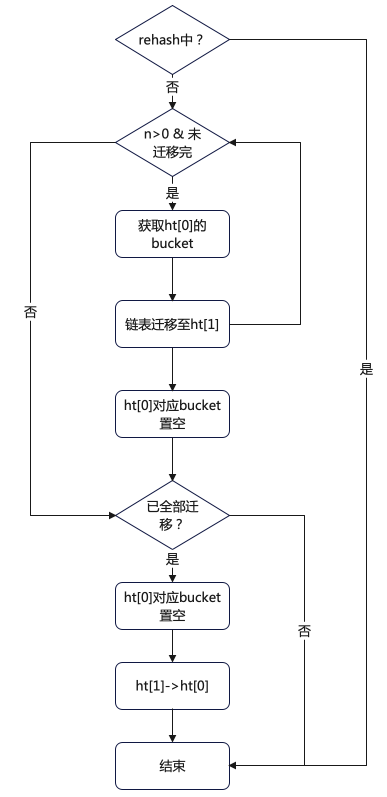
几点说明:
- rehashidx 表示当前 rehash 在对哪个 bucket 做数据迁移,每次迁移完对应 bucket 时,会将 rehashidx+1。
- empty_visits 表示连续 bucket 为空的情况,此时渐进式 rehash 不会一直递增检查 rehashidx,因为一直检测会阻塞主线程,Redis 主线程就无法处理其他请求了。
那么 rehash 是在什么哪些步骤进行操作的呢?查看源码发现 dictRehash 是在 _dictRehashStep 函数中调用的,且传入的 n=1。
static void _dictRehashStep(dict *d) {
if (d->pauserehash == 0) dictRehash(d,1);
}
而 _dictRehashStep 分别被 5 个方法调用了:
- dictAddRaw
- dictGenericDelete
- dictFind
- dictGetRandomKey
- dictGetSomeKeys
下面是 dictAddRaw 部分代码:
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing)
{
……
if (dictIsRehashing(d)) _dictRehashStep(d);
……
}
下面是 dictAdd 部分代码:
int dictAdd(dict *d, void *key, void *val)
{
dictEntry *entry = dictAddRaw(d,key,NULL);
if (!entry) return DICT_ERR;
dictSetVal(d, entry, val);
return DICT_OK;
}
Redis 源码简洁剖析系列
Java 编程思想-最全思维导图-GitHub 下载链接,需要的小伙伴可以自取~
原创不易,希望大家转载时请先联系我,并标注原文链接。
Redis 源码简洁剖析 03 - Dict Hash 基础的更多相关文章
- Redis 源码简洁剖析 07 - main 函数启动
前言 问题 阶段 1:基本初始化 阶段 2:检查哨兵模式,执行 RDB 或 AOF 检测 阶段 3:运行参数解析 阶段 4:初始化 server 资源管理 初始化数据库 创建事件驱动框架 阶段 5:执 ...
- Redis 源码简洁剖析 04 - Sorted Set 有序集合
Sorted Set 是什么 Sorted Set 命令及实现方法 Sorted Set 数据结构 跳表(skiplist) 跳表节点的结构定义 跳表的定义 跳表节点查询 层数设置 跳表插入节点 zs ...
- Redis 源码简洁剖析 12 - 一条命令的处理过程
命令的处理过程 Redis server 和一个客户端建立连接后,会在事件驱动框架中注册可读事件--客户端的命令请求.命令处理对应 4 个阶段: 命令读取:对应 readQueryFromClient ...
- Redis 源码简洁剖析 13 - RDB 文件
RDB 是什么 RDB 文件格式 Header Body DB Selector AUX Fields Key-Value Footer 编码算法说明 Length 编码 String 编码 Scor ...
- Redis 源码简洁剖析 16 - 客户端
整体概述 客户端属性 套接字描述符 标志 输入缓冲区 命名及命令参数 命令的实现函数 输出缓冲区 客户端的创建与关闭 创建普通客户端 关闭普通客户端 参考链接 Redis 源码简洁剖析系列 整体概述 ...
- Redis 源码简洁剖析 02 - SDS 字符串
C 语言的字符串函数 C 语言 string 函数,在 C 语言中可以使用 char* 字符数组实现字符串,C 语言标准库 string.h 中也定义了多种字符串操作函数. 字符串使用广泛,需要满足: ...
- Redis 源码简洁剖析 05 - ziplist 压缩列表
ziplist 是什么 Redis 哪些数据结构使用了 ziplist? ziplist 特点 优点 缺点 ziplist 数据结构 ziplist 节点 pre_entry_length encod ...
- Redis 源码简洁剖析 06 - quicklist 和 listpack
quicklist 为什么要设计 quicklist 特点 数据结构 quicklistCreate quicklistDelIndex quicklistDelEntry quicklistInse ...
- Redis 源码简洁剖析 09 - Reactor 模型
Reactor 模型 事件驱动框架 Redis 如何实现 Reactor 模型 事件的数据结构:aeFileEvent 主循环:aeMain 函数 事件捕获与分发:aeProcessEvents 函数 ...
随机推荐
- 【LeetCode】49. Group Anagrams 解题报告(Python & Java & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 排序+hash 日期 题目地址:https://le ...
- Polyomino Composer(UVA12291)
Description Polyomino Composer A polyomino is a plane geometric figure formed by joining one or m ...
- Chapter 5 Interaction
目录 5.1 Interaction requires a joint intervention 5.2 Identifying interaction 5.3 Counterfactual resp ...
- .NET6: 三分钟搭建WPF三维应用
要运行本文中的示例,请先安装Vistual Studio 2022,社区版就可以了. 1 创建项目 选择创建WPF应用 给程序起一个酷酷的名字,选一个酷酷的位置: 选一下.NET6 2 配置项目 从n ...
- python 使用hashlib进行md5加密
使用场景,某个接口或某个场景的数据需要做md5处理,就可以通过hashlib模块进行md5加密,如一个接口,需要传入md5加密后的数据 导入模块 import hashlib def exchange ...
- 初识python: xml 操作
导入模块: import xml.etree.ElementTree as ET 创建xml文件: new_xml = ET.Element("namelist") # 创建根节点 ...
- Pytest_allure报告(11)
一.allure工具环境配置 windows安装allure 1.下载allure工具包 进入工具包官网:https://github.com/allure-framework/allure2/rel ...
- Pytest_用例分组(6)
用例分组 pytest进行分组测试的方法是使用装饰器 @pytest.mark.标记名称,被标记为相同名称的用例可以看做为同一个组. 分组用例的运行方式是在执行命令中追加 -m "标记名称& ...
- vue2.0多页面开发
我们平常用vue开发的时候总觉得vue好像就是专门为了单页面应用而诞生的,其实不是.因为vue在工程化开发的时候很依赖webpack,而webpack是将所有的资源整合到一块,弄成一个单页面.但是vu ...
- JAVA8-STREAM 使用说明
概述 本人在java开发过程中,有些知识点需要记录整理,我尽量严谨的叙述我学习的经过和心得,以便备份和和大家一起进步学习,此篇文章是在网上多出搜集整理验证,结尾会注明出处,今天学习一个java8新的功 ...