flume 进阶
一、flume事务
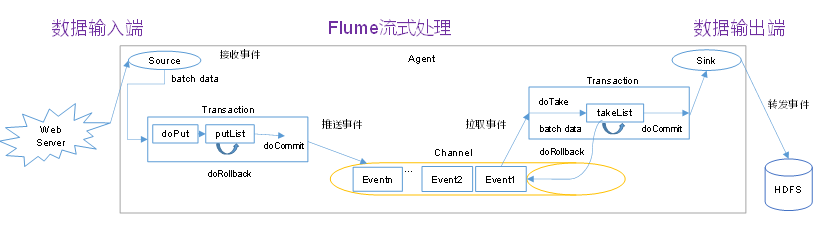
put事务流程:
1、doPut:将批量数据先写入临时缓冲区putList
2、doCommit:检查Channel内存队列是否足够,
(1)达到一定时间没有数据写入到putList
(2)达到了putListCapcity容量
3、doRollback:Channel内存队列空间不足,回滚数据到putList,会被channel打回来
take事务流程:
1、doTake:将数据取到临时缓冲区takeList,并将数据发送到HDFS
2、doCommit:如果数据全部发送成功,则清除临时缓冲区takeList
3、doRollback:数据发送过程中如果出现异常,rollback将临时缓冲区takeList中数据全部打回给Channel内存队列
二、Flume Agent内部原理
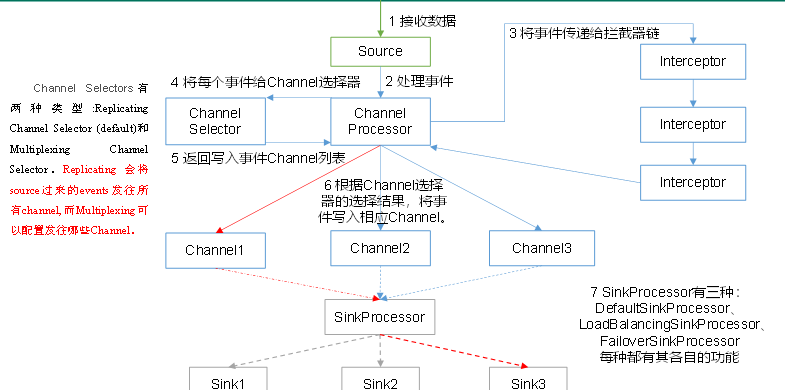
重要组件:
1)ChannelSelector
ChannelSelector的作用就是选出event将要被发往哪个Channel。
共有两种类型:Replicating(复制)和Multiplexing(多路复用)
ReplicatingSelector会将同一个event发往所有的Channel
MultiplexingSelector会根据相应的原则,将不同的event发往不同的Channel
2)SinkProcessor
sinkProcessor共有三种类型:DefaultSinkProcessor、LoadBalancingProcessor和FailoverSinkProcessor
DefaultSinkProcessor:对应的是单个sink
LoadBalancingProcessor:对应的是sink group,可以实现负载均衡
FailoverSinkProcessor:对应的是sink group,可以实现故障恢复
三、flume拓扑结构
1、简单串联
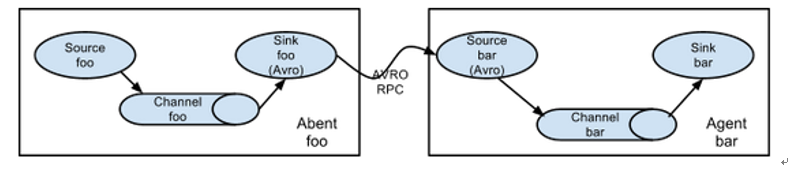
将多个flume顺序连接起来,从最初的Source开始到最终sink传送的目的存储系统。
此模式不建议桥接过多的flume数量,flume数据过多不仅会影响传输速率,而且一旦传输过程中某个节点flume宕机,会影响整个传输系统
2、复制和多路复用
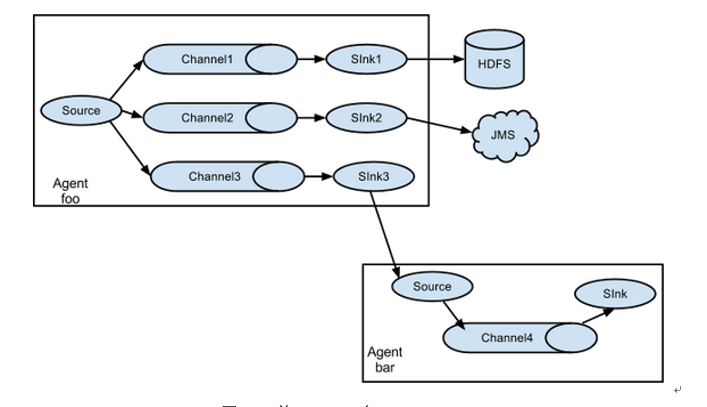
flume支持将事件流向一个或者多个目的地。
这种模式可以将相同数据复制到多个Channel中,或者将不同数据分发到不同的Channel中,sink可以选择传送到不同的目的地
3、负载均衡和故障转移
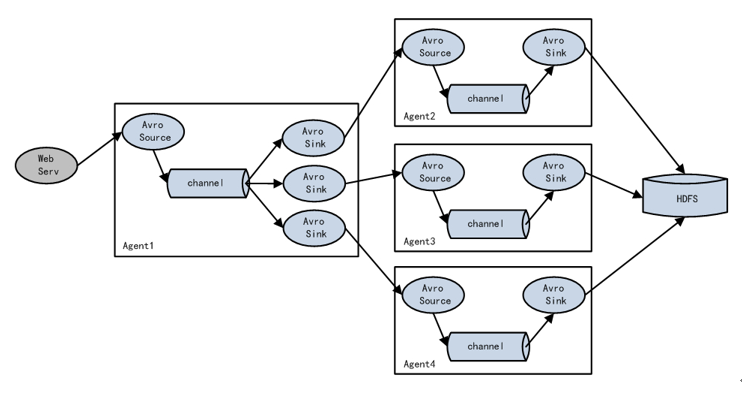
flume支持使用将多个sink逻辑上分到一个sink组,sink组配合不同的sinkProcessor可以实现负载均衡和错误恢复的功能
4、聚合
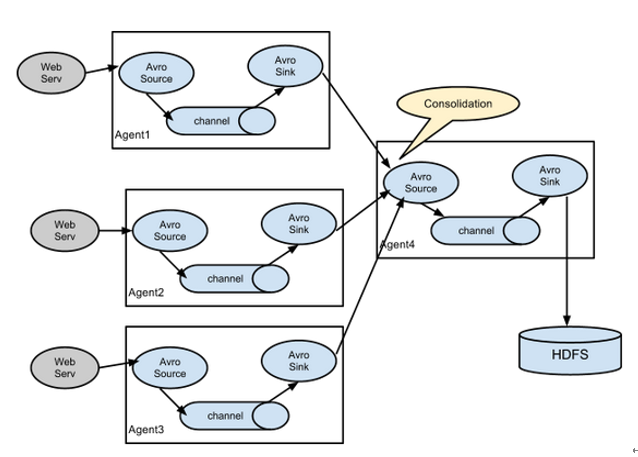
这种模式是我们最常见的,也非常实用,日常web应用通常分布在上百个服务器,大者甚至上千个、上万个服务器。产生的日志,处理 起来也非常麻烦。
用flume的这种组合方式能很好的解决这一问题,每台服务器部署一个flume采集日志,传送到一个集中收集日志的flume,再由此flume 上传到hdfs、hive、hbase等,进行日志分析。
flume 进阶的更多相关文章
- flume进阶
上一张初识里面谢了一些flume入门的内容,其实在真正工作环境里面这种情况使用的是很少的,大部分情况,我们可能需要从多台设备的日志里面汇总收集数据并存储到HDFS上,以便于后期对数据进行处理,真实的情 ...
- Flume 详解&实战
Flume 1. 概述 Flume是一个高可用,高可靠,分布式的海量日志采集.聚合和传输的系统.Flume基于流式架构,灵活简单. Flume的作用 Flume最主要的作用就是,实时读取服务器本地磁盘 ...
- Flume(三)【进阶】
[toc] 一.Flume 数据传输流程 重要组件: 1)Channel选择器(ChannelSelector) ChannelSelector的作用就是选出Event将要被发往哪个Channel ...
- 基于Hadoop技术实现的离线电商分析平台(Flume、Hadoop、Hbase、SpringMVC、highcharts)
离线数据分析平台是一种利用hadoop集群开发工具的一种方式,主要作用是帮助公司对网站的应用有一个比较好的了解.尤其是在电商.旅游.银行.证券.游戏等领域有非常广泛,因为这些领域对数据和用户的特性把握 ...
- Flume简介及安装
Hadoop业务的大致开发流程以及Flume在业务中的地位: 从Hadoop的业务开发流程图中可以看出,在大数据的业务处理过程中,对于数据的采集是十分重要的一步,也是不可避免的一步,从而引出我们本文的 ...
- 大数据学习之Linux进阶02
大数据学习之Linux进阶 1-> 配置IP 1)修改配置文件 vi /sysconfig/network-scripts/ifcfg-eno16777736 2)注释掉dhcp #BOOTPR ...
- Java进阶步骤
一.基础篇 面向对象 什么是面向对象 面向对象.面向过程 面向对象的三大基本特征和五大基本原则 平台无关性 Java如何实现的平台无关 JVM还支持哪些语言(Kotlin.Groovy.JRuby.J ...
- 转:java 进阶之路
转: https://www.zhihu.com/question/39139518 一.基础篇1.1 JVM1.1.1. Java内存模型,Java内存管理,Java堆和栈,垃圾回收 http:// ...
- Java进阶专题(二十一) 消息中间件架构体系(3)-- Kafka研究
前言 Kafka 是一款分布式消息发布和订阅系统,具有高性能.高吞吐量的特点而被广泛应用与大数据传输场景.它是由 LinkedIn 公司开发,使用 Scala 语言编写,之后成为 Apache 基金会 ...
随机推荐
- 安装suds,提示No module named 'client'
最近在研究webservice,但是在线安装suds的时候提示No module named 'client' 提示没有client模块,提示这个错误主要还是因为没有安装client模块 在线安装cl ...
- 【串线篇】spring boot自定义starter
starter: 一.这个场景需要使用到的依赖是什么? 二.如何编写自动配置 启动器只用来做依赖导入:(启动器模块是一个空 JAR 文件,仅提供辅助性依赖管理,这些依赖可能用于自动装配或者其他类库) ...
- 如何保证Redis与数据库的数据一致性
一般来说,只要你用到了缓存,不管是Redis还是memcache,就可能会涉及到数据库缓存与数据的一致性问题,这里我们以Redis为例. 我们该如何保证Redis与数据库的一致性呢? So easy: ...
- ubuntu16.04 开启FTP服务
配置ftp 1.安装 vsftpd服务器 sudo apt install vsftpd 2.创建一个ftp文件夹 (可以跳过) sudo mkdir /home/ftp 3.新建ftp用户,并指向它 ...
- MongoDB之$关键字,以及$修饰器$set,$inc,$push,$pull,$pop
一.查询中常见的 等于 大于 小于 大于等于 小于等于 等于:在MongoDB中,什么字段等于什么值就是" : ",比如 "name":"路飞学城&q ...
- JSON提取器
如果返回的数据是JSON格式的,我们可以用JSON提取器来提取需要的字段,这样更简单一点 Variable names:保存的变量名,后面使用${Variable names}引用 JSON Path ...
- DNS域名解析系统
1.DNS的组成 DNS系统是为解析域名为IP地址而存在的,它是由域名空间.资源记录.名称服务器和解析器组成. 域名空间是包含一个树状结构,用于存储资源记录的空间. 资源记录是与域名相关的数据,如IP ...
- webkit内核的浏览器常见7种分别是..
Google Chrome Safari 遨游浏览器 3.x 搜狗浏览器 阿里云浏览器 QQ浏览器 360浏览器 ...
- visual studio 2017激活
VS2017专业版和企业版激活密钥 Enterprise: NJVYC-BMHX2-G77MM-4XJMR-6Q8QF Professional: KBJFW-NXHK6-W4WJM-CRMQB- ...
- maven整合eclise
-Dmaven.multiModuleProjectDirectory=$M2_HOME