jieba(结巴)常用方法
python jieba库的基本使用
第一步:先安装jieba库
输入命令:pip install jieba

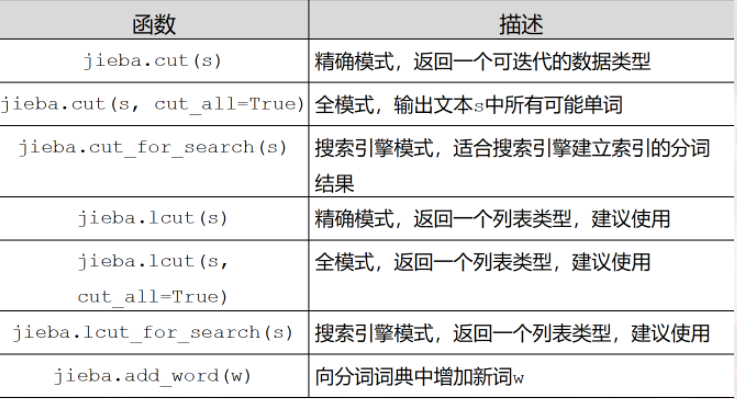
jieba库常用函数:
jieba库分词的三种模式:
1、精准模式:把文本精准地分开,不存在冗余
2、全模式:把文中所有可能的词语都扫描出来,存在冗余
3、搜索引擎模式:在精准模式的基础上,再次对长词进行切分
精准模式:
>>> import jieba
>>> jieba.lcut("中国是一个伟大的国家")
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\25282\AppData\Local\Temp\jieba.cache
Loading model cost 0.869 seconds.
Prefix dict has been built succesfully.
['中国', '是', '一个', '伟大', '的', '国家']
全模式:
>>> jieba.lcut("中国是一个伟大的国家",cut_all=True)
['中国', '国是', '一个', '伟大', '的', '国家']
搜索引擎模式:
>>> jieba.lcut_for_search("中华人民共和国是伟大的")
['中华', '华人', '人民', '共和', '共和国', '中华人民共和国', '是', '伟大', '的']
向分词词典增加新词:
>>> jieba.add_word("蟒蛇语言")
>>> jieba.lcut("python是蟒蛇语言")
['python', '是', '蟒蛇语言']
jieba库应用举例1 ——统计八荣八耻中出现的词汇


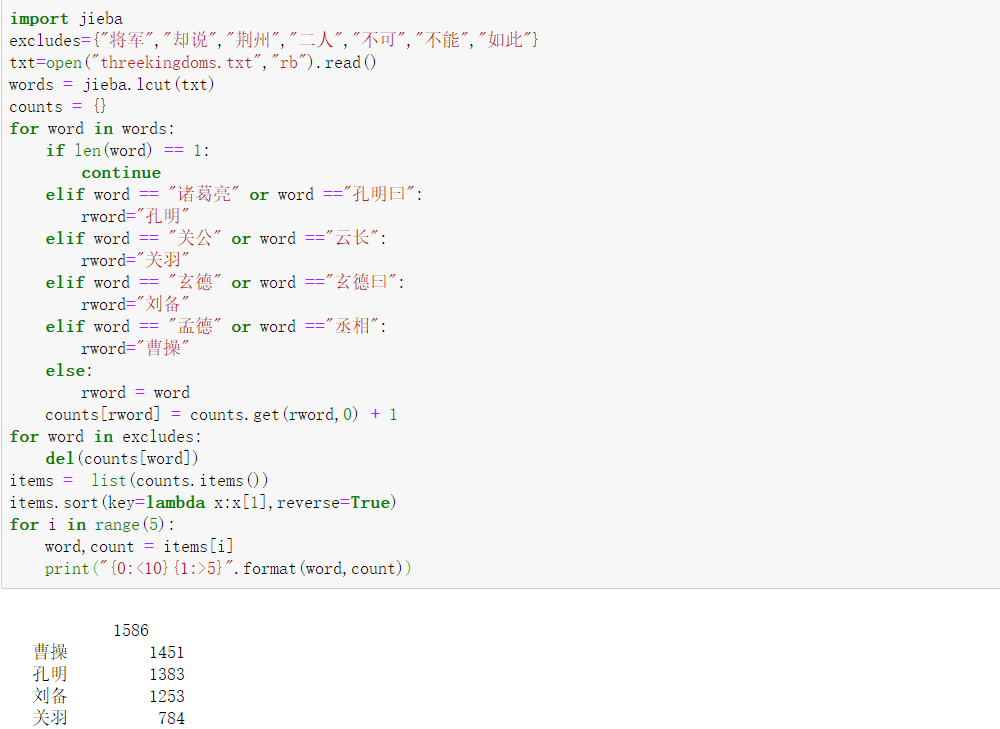
jieba库分词统计实例2--三国演义词汇
(1)查找出“threekingdoms.txt”文件中出现频率前十位的词汇

(2)统计出“threekingdoms.txt”文件 “关羽”、“曹操”、“诸葛亮”、“刘备” 等人名出现的次数
jieba(结巴)常用方法的更多相关文章
- 模块 jieba结巴分词库 中文分词
jieba结巴分词库 jieba(结巴)是一个强大的分词库,完美支持中文分词,本文对其基本用法做一个简要总结. 安装jieba pip install jieba 简单用法 结巴分词分为三种模式:精确 ...
- Python3.7+jieba(结巴分词)配合Wordcloud2.js来构造网站标签云(关键词集合)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_138 其实很早以前就想搞一套完备的标签云架构了,迫于没有时间(其实就是懒),一直就没有弄出来完整的代码,说到底标签对于网站来说还是 ...
- solr+jieba结巴分词
为什么选择结巴分词 分词效率高 词料库构建时使用的是jieba (python) 结巴分词Java版本 下载 git clone https://github.com/huaban/jieba-ana ...
- python调用jieba(结巴)分词 加入自定义词典和去停用词功能
把语料从数据库提取出来以后就要进行分词啦,我是在linux环境下做的,先把jieba安装好,然后找到内容是build jieba PKG-INFO setup.py test的那个文件夹(我这边是ji ...
- jieba结巴分词
pip install jieba安装jieba模块 如果网速比较慢,可以使用豆瓣的Python源:pip install -i https://pypi.douban.com/simple/ jie ...
- 结巴(jieba)分词
一.介绍: jieba: “结巴”中文分词:做最好的 Python 中文分词组件 “Jieba” (Chinese for “to stutter”) Chinese text segmentatio ...
- python 结巴分词(jieba)详解
文章转载:http://blog.csdn.net/xiaoxiangzi222/article/details/53483931 jieba “结巴”中文分词:做最好的 Python 中文分词组件 ...
- python第三方库------jieba库(中文分词)
jieba“结巴”中文分词:做最好的 Python 中文分词组件 github:https://github.com/fxsjy/jieba 特点支持三种分词模式: 精确模式,试图将句子最精确地切开, ...
- python之jieba库
jieba “结巴”中文分词:做最好的 Python 中文分词组件 "Jieba" (Chinese for "to stutter") Chinese tex ...
随机推荐
- PostGIS 爆管分析之找出上游阀门(优化版)
说明 前面描述过利用postgis查找上游阀门的原理,以及代码,其实当初写完就发现又很大的优化空间,但一直没有时间去做. 最近遇到一个情况,处理60w+条管网数据时,效率太慢了,于是腾时间优化了一版. ...
- Linux FTP的安装与权限配置
ftp安装部分,操作步骤如下: 1.切换到root用户 2.查看是否安装vsftp,我这个是已经安装的. [root@localhost vsftpd]# rpm -qa |grep vsftpd v ...
- 093、如何用Graylog 管理日志? (2019-05-17 周五)
参考https://www.cnblogs.com/CloudMan6/p/7821817.html 上节我们已经部署好了 Graylog ,现在学习如何使用他来管理日志. 首先运行测试容器, ...
- JavaSE基础:集合类
JavaSE基础:集合类 简单认识类集 我们学习的是面向对象语言,而面向对象语言对事物的描述是通过对象体现的,为了方便对多个对象进行操作,我们就必须把这多个对象进行存储. 而要向存储多个对象,就不能是 ...
- cookie Web Storage API
https://developer.mozilla.org/zh-CN/docs/Web/API/Web_Storage_API/Using_the_Web_Storage_API https://d ...
- Ajax轮询请求
Ajax轮询请求 什么是轮询? 轮询(polling):客户端按规定时间定时向服务端发送ajax请求,服务器接到请求后马上返回响应信息并关闭连接. Ajax轮询需要服务器有很快的处理速度与快速响应. ...
- MWPhotoBrowser.bundle: bundle format unrecognized, invalid, or unsuitable
今天在github下载了MWPhotoBrowser的demo想跑一下,却发现报了MWPhotoBrowser.bundle: bundle format unrecognized, invalid, ...
- MySQL数据库数据类型以及INT(M)的含义
nt(M)我们先来拆分,int是代表整型数据那么中间的M应该是代表多少位了,后来查mysql手册也得知了我的理解是正确的,下面我来举例说明. MySQL 数据类型中的 integer types ...
- 2019-11-29-Roslyn-使用-Directory.Build.props-文件定义编译
title author date CreateTime categories Roslyn 使用 Directory.Build.props 文件定义编译 lindexi 2019-11-29 08 ...
- Spring基础20——AOP基础
1.什么是AOP AOP(Aspect-Oriented Programming)即面向切面编程,是一种新的方法论,是对那个传统OOP面向对象编程的补充.AOP的主要编程对象是切面(aspect),而 ...