tenorflow 模型调优
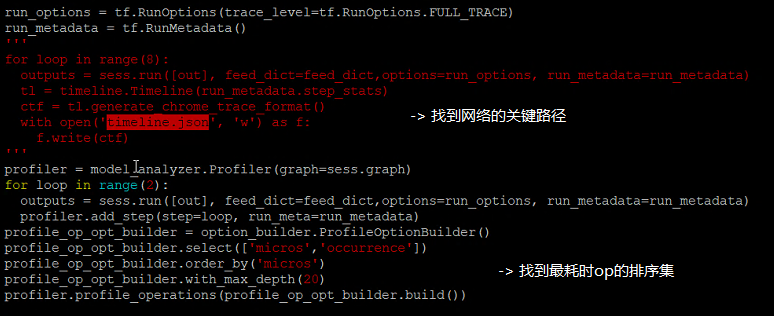
# Create the Timeline object, and write it to a json
from tensorflow.python.client import timeline
tl = timeline.Timeline(run_metadata.step_stats)
ctf = tl.generate_chrome_trace_format()
with tf.gfile.GFile("timeline.json", 'w') as f:
f.write(ctf)
chrome://tracing/
from tensorflow.core.framework import graph_pb2
from tensorflow.python.profiler import model_analyzer
from tensorflow.python.profiler import option_builder
graph = tf.Graph()
with graph.as_default():
graph_def = graph_pb2.GraphDef()
with open(args.input_graph, "rb") as f:
graph_def.ParseFromString(f.read())
_ = tf.import_graph_def(graph_def, name='')
config = tf.ConfigProto(inter_op_parallelism_threads=args.num_inter_threads, intra_op_parallelism_threads=args.num_intra_threads)
with tf.Session(config=config, graph=graph) as sess:
# warm up
...
# benchmark
...
# profiling
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
run_metadata = tf.RunMetadata()
profiler = model_analyzer.Profiler(graph=graph)
for i in range(10):
outputs = sess.run(output_data, feed_dict=input_data, options=run_options, run_metadata=run_metadata)
profiler.add_step(step=i, run_meta=run_metadata)
profile_op_opt_builder = option_builder.ProfileOptionBuilder()
profile_op_opt_builder.select(['micros','occurrence'])
profile_op_opt_builder.order_by('micros')
profile_op_opt_builder.with_max_depth(50)
profiler.profile_operations(profile_op_opt_builder.build())
tenorflow 模型调优的更多相关文章
- 使用sklearn进行数据挖掘-房价预测(6)—模型调优
通过上一节的探索,我们会得到几个相对比较满意的模型,本节我们就对模型进行调优 网格搜索 列举出参数组合,直到找到比较满意的参数组合,这是一种调优方法,当然如果手动选择并一一进行实验这是一个十分繁琐的工 ...
- 深度学习模型调优方法(Deep Learning学习记录)
深度学习模型的调优,首先需要对各方面进行评估,主要包括定义函数.模型在训练集和测试集拟合效果.交叉验证.激活函数和优化算法的选择等. 那如何对我们自己的模型进行判断呢?——通过模型训练跑代码,我们可以 ...
- Spark-内存管理调优
这篇文章主要是对官网内容学习过程的总结,大部分是原文,加上自己的学习笔记!!! spark 2.0+内存模型 调优内存使用时需要考虑三个因素: 对象使用的内存数量(您可能希望您的整个数据集都能装入内存 ...
- JVM内存模型与性能调优
堆内存(Heap) 堆是由Java虚拟机(JVM,下文提到的JVM特指Sun hotspot JVM)用来存放Java类.对象和静态成员的内存空间,Java程序中创建的所有对象都在堆中分配空间,堆只用 ...
- Java虚拟机内存模型及垃圾回收监控调优
Java虚拟机内存模型及垃圾回收监控调优 如果你想理解Java垃圾回收如果工作,那么理解JVM的内存模型就显的非常重要.今天我们就来看看JVM内存的各不同部分及如果监控和实现垃圾回收调优. JVM内存 ...
- 深入理解JAVA虚拟机(内存模型+GC算法+JVM调优)
目录 1.Java虚拟机内存模型 1.1 程序计数器 1.2 Java虚拟机栈 局部变量 1.3 本地方法栈 1.4 Java堆 1.5 方法区(永久区.元空间) 附图 2.JVM内存分配参数 2.1 ...
- XGBoost模型的参数调优
XGBoost算法在实际运行的过程中,可以通过以下要点进行参数调优: (1)添加正则项: 在模型参数中添加正则项,或加大正则项的惩罚力度,即通过调整加权参数,从而避免模型出现过拟合的情况. (2)控制 ...
- Spark机器学习——模型选择与参数调优之交叉验证
spark 模型选择与超参调优 机器学习可以简单的归纳为 通过数据训练y = f(x) 的过程,因此定义完训练模型之后,就需要考虑如何选择最终我们认为最优的模型. 如何选择最优的模型,就是本篇的主要内 ...
- Spark2 Model selection and tuning 模型选择与调优
Model selection模型选择 ML中的一个重要任务是模型选择,或使用数据为给定任务找到最佳的模型或参数. 这也称为调优. 可以对诸如Logistic回归的单独Estimators进行调整,或 ...
随机推荐
- Ubuntu安装过程中的问题
1.win10系统安装32bit ubuntu,使用VM安装ubuntu 的iso文件,刚启动不停按F2,进入BIOS,boot设置为 CD-ROM drive 2.安装界面都没有出现,电脑老是重启, ...
- Internet History, Technology, and Security(week2)——History: The First Internet - NSFNet
前言: 上周学习了<电子计算机的曙光>,对战时及战后的计算机的历史发展有了更丰富的了解,今天继续coursera的课程,感觉已经有点适应了课程的节奏(除了经常有些奇奇怪怪的词汇看都看不懂@ ...
- navigator组件(相当于a标签)
navigator组件:页面链接: navigator组件属性: target:类型 字符串 在哪个目标上发生跳转,默认当前小程序 属性值:self 当前小程序 miniProgram 其他小程序 u ...
- 关于 Visual stdio 编译报错:error MSB6006: “CL.exe”已退出
网上查看,原因有多种. 1,我自己遇到的是这样的: 环境:VS2019,编译项目 image-master,中间自己重整了原来的目录,移动了很多文件.编译报错:error MSB6006: “CL.e ...
- C# 防火墙操作之特定程序
将特定程序加入防火墙组,与将特定端口加入防火墙流程类似.详情见“C# 防火墙操作之特定端口”.其主要代码为: /// <summary> /// 允许应用程序通过防火墙 /// </ ...
- 阶段1 语言基础+高级_1-3-Java语言高级_1-常用API_1_第8节 Math类_18_数学工具类Math
常用几个数学的方法 abs绝对值 ceil向上取整,它并不是四舍五入 floor向下取整 round四舍五入 PI 按住Ctrl+鼠标左键 进入Math这个类的源码里面 Ctrl+F12 然后输入PI ...
- curl发json
linux 模拟post请求 curl -X POST \ -H "Content-Type: application/json" \ -H "token:GXJP1cl ...
- CGI 环境变量
CGI 环境变量 环境变量 意义 SERVER_NAME CGI脚本运行时的主机名和IP地址. SERVER_SOFTWARE 你的服务器的类型如: CERN/3.0 或 NCSA/1.3. GATE ...
- Spring MVC-学习笔记(3)参数绑定注解、HttpMessageConverter<T>信息转换、jackson、fastjson、XML
1.参数绑定注解 1>@RequestParam: 用于将指定的请求参数赋值给方法中的指定参数.支持的属性: 2>@PathVariable:可以方便的获得URL中的动态参数,只支持一个属 ...
- MySQL-第十篇多表连接查询
1.SQL92规范.SQL99规范 2.广义笛卡尔积,多表之间没有任何连接条件,得到的结果将是N x M条记录. 3.SQL92中的左外连接.右外连接,连接符有(+或*),放在连接条件那一边就叫做左或 ...