入门大数据---Anaconda安装
1. 什么是Anaconda?
Anaconda是一个开源的Python发行版本,python是一个编译器,如果不使用Anaconda那么安装起来会比较痛苦,各个库之间的依赖性就很难连接的很好。Anaconda可以看做Python的一个集成安装,里面集成了很多关于python科学计算的第三方库,安装它后就默认安装了python、IPython、集成开发环境Spyder和众多的包和模块,包含了conda(conda 是开源包(packages)和虚拟环境(environment)的管理系统。)、Python等180多个科学包及其依赖项。因为包含了大量的科学包,Anaconda 的下载文件比较大(约 515 MB),如果只需要某些包,或者需要节省带宽或存储空间,也可以使用Miniconda这个较小的发行版(仅包含conda和 Python)。
2. 下载Anaconda
Anaconda官网,下载Anaconda:
下载Anaconda也可以在清华镜像下载:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
3. windows 安装Anaconda
- 官网下载安装Anaconda,安装路径中不要有中文和空格
安装过程中会有下图所示,直接将Anaconda加入到系统环境变量中:
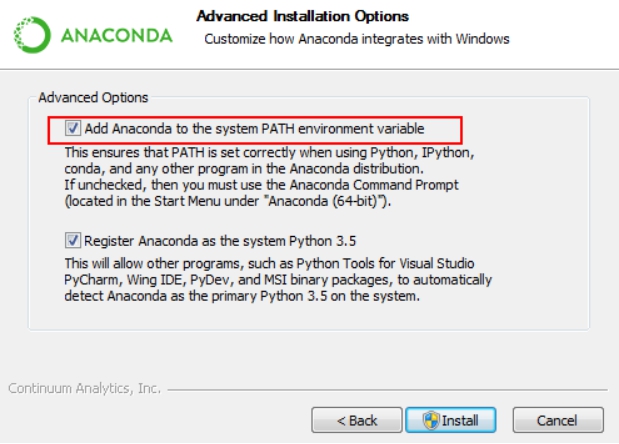
如果不选中也可以安装完成后自己配置环境变量:
a) 我的电脑->右键属性->高级系统设置->高级->环境变量->系统变量
找到Path,加入(以自己的路径为准):
C:\Anaconda C:\Anaconda\Scripts C:\Anaconda\Library\bin
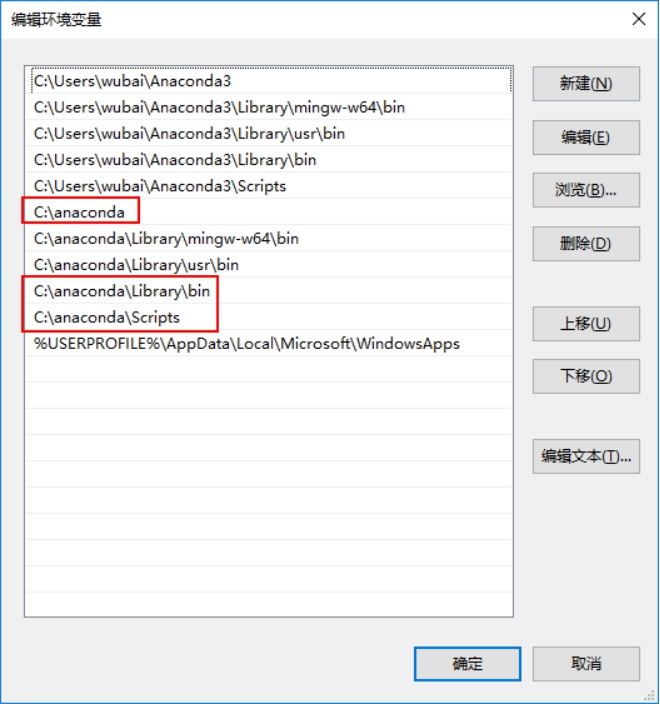
b) 加入完成之后重启cmd命令即可。
- 安装完成后,进入cmd,检验安装是否成功
conda --version

- 通过python –version 命令查看发行版默认的Python版本
python --version

4. Anaconda应用介绍及使用
Anaconda Navigator :用于管理工具包和环境的图形用户界面,后续涉及的众多管理命令也可以在 Navigator 中手工实现。
Jupyter notebook :基于web的交互式计算环境,可以编辑易于人们阅读的文档,用于展示数据分析的过程。
QTconsole :一个可执行 IPython 的仿终端图形界面程序,相比 Python Shell 界面,qtconsole 可以直接显示代码生成的图形,实现多行代码输入执行,以及内置许多有用的功能和函数。
spyder :一个使用Python语言、跨平台的、科学运算集成开发环境。
#创建一个名为python34的环境,指定Python版本是3.5(不用管是3.5.x,conda会#为我们自动寻找3.5.x中的最新版本)
conda create --name python35 python=3.5
#安装好后,使用activate激活某个环境
activate python35 # for Windows
source activate python35 # for Linux & Mac
#激活后,会发现terminal输入的地方多了python35 的字样,实际上,此时系统做的#事情就是把默认2.7环境从PATH中去除,再把3.5对应的命令加入PATH
#此时,再次输入
python --version
#可以得到`Python 3.5.5 :: Anaconda 4.1.1 (64-bit)`,即系统已经切换到了3.5
#的环境
#如果想返回默认的python 2.7环境,运行
deactivate python35 # for Windows
source deactivate python35 # for Linux & Mac
#删除一个已有的环境
conda remove --name python35 --all
入门大数据---Anaconda安装的更多相关文章
- 大数据软件安装之Hadoop(Apache)(数据存储及计算)
大数据软件安装之Hadoop(Apache)(数据存储及计算) 一.生产环境准备 1.修改主机名 vim /etc/sysconfig/network 2.修改静态ip vim /etc/udev/r ...
- 大数据软件安装之HBase(NoSQL数据库)
一.安装部署 1.Zookeeper正常部署 (见前篇博文大数据软件安装之ZooKeeper监控 ) [test@hadoop102 zookeeper-3.4.10]$ bin/zkServer.s ...
- 入门大数据---安装ClouderaManager,CDH和Impala,Hue,oozie等服务
1.要求和支持的版本 (PS:我使用的环境,都用加粗标识了.) 1.1 支持的操作系统版本 操作系统 版本 RHEL/CentOS/OL with RHCK kernel 7.6, 7.5, 7.4, ...
- 入门大数据---Flink学习总括
第一节 初识 Flink 在数据激增的时代,催生出了一批计算框架.最早期比较流行的有MapReduce,然后有Spark,直到现在越来越多的公司采用Flink处理.Flink相对前两个框架真正做到了高 ...
- 【大数据】安装关系型数据库MySQL安装大数据处理框架Hadoop
作业来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3161 1. 简述Hadoop平台的起源.发展历史与应用现状. 列举发展过 ...
- 【大数据】安装关系型数据库MySQL 安装大数据处理框架Hadoop
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3161 1.安装Mysql 使用命令 sudo apt-get ins ...
- 大数据hadoop安装
hadoop集群搭建--CentOS部署Hadoop服务 在了解了Hadoop的相关知识后,接下来就是Hadoop环境的搭建,搭建Hadoop环境是正式学习大数据的开始,接下来就开始搭建环境!我们用到 ...
- 入门大数据---Spark_Streaming整合Flume
一.简介 Apache Flume 是一个分布式,高可用的数据收集系统,可以从不同的数据源收集数据,经过聚合后发送到分布式计算框架或者存储系统中.Spark Straming 提供了以下两种方式用于 ...
- 入门大数据---SparkSQL外部数据源
一.简介 1.1 多数据源支持 Spark 支持以下六个核心数据源,同时 Spark 社区还提供了多达上百种数据源的读取方式,能够满足绝大部分使用场景. CSV JSON Parquet ORC JD ...
随机推荐
- 2018-ECCV-PNAS-Progressive Neural Architecture Search-论文阅读
PNAS 2018-ECCV-Progressive Neural Architecture Search Johns Hopkins University(霍普金斯大学) && Go ...
- 【SpringMVC】使用三层架构实现登录,注册。(下篇)
上篇写了构思与界面层,本篇写一下业务逻辑层.数据访问层 目录 业务逻辑层 包:pojo 用户类(JavaBean):User public class User { private String us ...
- break 与 continue 的作用 详解
1.break 用break语句可以使流程跳出switch语句体,也可以用break语句在循环结构终止本层循环体,从而提前结束本层循环. 使用说明: (1)只能在循环体内和switch语句体内使用br ...
- 重装ArchLinux后修改GRUB配置不生效问题的解决
重装ArchLinux后修改GRUB配置不生效问题的解决 mount指令看一下挂载,或者vim /etc/fstab看一下有没有/boot,看看fstab是不是没写进去.... 我特喵昨天重装完Arc ...
- Spring Boot笔记(三) springboot 集成 Quartz 定时任务
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 1. 在 pom.xml 中 添加 Quartz 所需要 的 依赖 <!--定时器 quartz- ...
- Java实现 蓝桥杯 算法训练 出现次数最多的整数
算法训练 出现次数最多的整数 时间限制:1.0s 内存限制:512.0MB 提交此题 问题描述 编写一个程序,读入一组整数,这组整数是按照从小到大的顺序排列的,它们的个数N也是由用户输入的,最多不会 ...
- Java实现蓝桥杯算法提高 陶陶摘苹果
试题 算法提高 陶陶摘苹果 资源限制 时间限制:1.0s 内存限制:256.0MB 问题描述 陶陶家的院子里有一棵苹果树,每到秋天树上就会结出n个苹果.苹果成熟的时候,陶陶就会跑去摘苹果.陶陶有个30 ...
- Java实现 LeetCode 453 最小移动次数使数组元素相等
453. 最小移动次数使数组元素相等 给定一个长度为 n 的非空整数数组,找到让数组所有元素相等的最小移动次数.每次移动可以使 n - 1 个元素增加 1. 示例: 输入: [1,2,3] 输出: 3 ...
- Java实现蓝桥杯模拟递增三元组
问题描述 在数列 a[1], a[2], -, a[n] 中,如果对于下标 i, j, k 满足 0<i<j<k<n+1 且 a[i]<a[j]<a[k],则称 a ...
- Java实现 LeetCode 321 拼接最大数
321. 拼接最大数 给定长度分别为 m 和 n 的两个数组,其元素由 0-9 构成,表示两个自然数各位上的数字.现在从这两个数组中选出 k (k <= m + n) 个数字拼接成一个新的数,要 ...