【Spark】通过SparkStreaming实现从socket接受数据,并进行简单的单词计数
步骤
一、创建maven工程并导入jar包
<properties>
<scala.version>2.11.8</scala.version>
<spark.version>2.2.0</spark.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
<!-- <verbal>true</verbal>-->
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass></mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
二、安装并启动生产者
在node01安装nc工具
yum -y install nc
使用nc工具向指定端口发送数据
nc -lk 9999
三、开发SparkStreaming代码
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object WordCountTest {
def main(args: Array[String]): Unit = {
//获取SparkConf
val sparkConf: SparkConf = new SparkConf().setAppName("Streaming_WordCountTest").setMaster("local[4]").set("spark.driver.host", "localhost")
//获取SparkContext
val sparkContext: SparkContext = new SparkContext(sparkConf)
//设置日志级别
sparkContext.setLogLevel("WARN")
//获取StreamingContext 需要两个参数 SparkContext和duration,后者就是间隔时间
val streamContext: StreamingContext = new StreamingContext(sparkContext, Seconds(5))
//从socket获取数据
val stream: ReceiverInputDStream[String] = streamContext.socketTextStream("node01", 9999)
//对数据进行计数操作
val result: DStream[(String, Int)] = stream.flatMap(x => x.split(" ")).map((_, 1)).reduceByKey(_ + _)
//输出数据
result.print()
//启动程序
streamContext.start()
streamContext.awaitTermination()
}
}
四、查看结果
nc工具发送的数据
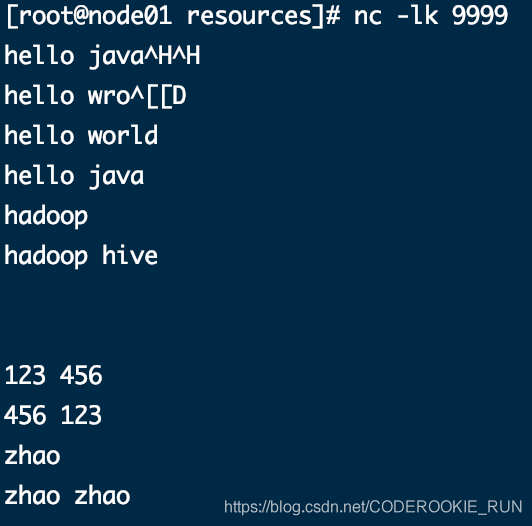
控制台结果
-----------------------------------------
Time: 1586852050000 ms
-------------------------------------------
(hive,1)
(wro,1)
(hadoop,2)
(hello,4)
(java,1)
(ja,1)
(world,1)
-------------------------------------------
Time: 1586852055000 ms
-------------------------------------------
-------------------------------------------
Time: 1586852060000 ms
-------------------------------------------
20/04/14 16:14:23 WARN RandomBlockReplicationPolicy: Expecting 1 replicas with only 0 peer/s.
20/04/14 16:14:23 WARN BlockManager: Block input-0-1586852063400 replicated to only 0 peer(s) instead of 1 peers
20/04/14 16:14:24 WARN RandomBlockReplicationPolicy: Expecting 1 replicas with only 0 peer/s.
20/04/14 16:14:24 WARN BlockManager: Block input-0-1586852064000 replicated to only 0 peer(s) instead of 1 peers
-------------------------------------------
Time: 1586852065000 ms
-------------------------------------------
(,2)
20/04/14 16:14:29 WARN RandomBlockReplicationPolicy: Expecting 1 replicas with only 0 peer/s.
20/04/14 16:14:29 WARN BlockManager: Block input-0-1586852069600 replicated to only 0 peer(s) instead of 1 peers
-------------------------------------------
Time: 1586852070000 ms
-------------------------------------------
(456,1)
(123,1)
20/04/14 16:14:31 WARN RandomBlockReplicationPolicy: Expecting 1 replicas with only 0 peer/s.
20/04/14 16:14:31 WARN BlockManager: Block input-0-1586852071200 replicated to only 0 peer(s) instead of 1 peers
20/04/14 16:14:34 WARN RandomBlockReplicationPolicy: Expecting 1 replicas with only 0 peer/s.
20/04/14 16:14:34 WARN BlockManager: Block input-0-1586852073800 replicated to only 0 peer(s) instead of 1 peers
-------------------------------------------
Time: 1586852075000 ms
-------------------------------------------
(zhao,1)
(456,1)
(123,1)
20/04/14 16:14:36 WARN RandomBlockReplicationPolicy: Expecting 1 replicas with only 0 peer/s.
20/04/14 16:14:36 WARN BlockManager: Block input-0-1586852076200 replicated to only 0 peer(s) instead of 1 peers
-------------------------------------------
Time: 1586852080000 ms
-------------------------------------------
(zhao,2)
-------------------------------------------
Time: 1586852085000 ms
-------------------------------------------
-------------------------------------------
Time: 1586852090000 ms
-------------------------------------------
【Spark】通过SparkStreaming实现从socket接受数据,并进行简单的单词计数的更多相关文章
- C# Socket 接受数据不全的处理
由于Socket 一次传输数据有限,因此需要多次接受数据传输. 解决办法一: int numberOfBytesRead = 0; int totalNumberOfBytes = 0 ...
- spark-streaming集成Kafka处理实时数据
在这篇文章里,我们模拟了一个场景,实时分析订单数据,统计实时收益. 场景模拟 我试图覆盖工程上最为常用的一个场景: 1)首先,向Kafka里实时的写入订单数据,JSON格式,包含订单ID-订单类型-订 ...
- Spark Streaming源码解读之流数据不断接收和全生命周期彻底研究和思考
本节的主要内容: 一.数据接受架构和设计模式 二.接受数据的源码解读 Spark Streaming不断持续的接收数据,具有Receiver的Spark 应用程序的考虑. Receiver和Drive ...
- spark or sparkstreaming的内存泄露问题?
关于sparkstreaming的无法正常产生数据---->到崩溃---->到数据读写极为缓慢(或块丢失?)问题 前两阶段请看我的博客:https://www.cnblogs.com/wa ...
- 3 python3 编码解码问题 upd接受数据
1.python3下的中文乱码:send_data.encode("utf-8") from socket import * udp_socket = socket(AF_INET ...
- 【Spark】SparkStreaming与flume进行整合
文章目录 注意事项 SparkStreaming从flume中poll数据 步骤 一.开发flume配置文件 二.启动flume 三.开发sparkStreaming代码 1.创建maven工程,导入 ...
- C#上位机制作之串口接受数据(利用接受事件)
前面设计好了界面,现在就开始写代码了,首先定义一个串口对象.. SerialPort serialport = new SerialPort();//定义串口对象 添加串口扫描函数,扫描出来所有可用串 ...
- dsp28377控制DM9000收发数据——第三版程序,通过外部引脚触发来实现中断接受数据,优化掉帧现象
//-------------------------------------------------------------------------------------------- - //D ...
- PHP+socket游戏数据统计平台发包接包类库
<?php /** * @title: PHP+socket游戏数据统计平台发包接包类库 * @version: 1.0 * @author: perry <perry@1kyou.com ...
随机推荐
- delphi中DateTimePicker控件同时输入日期和时间
将DateTimePicker的Format属性中加入日期格式设成 'yyyy-MM-dd HH:mm',注意大小写 , 将kind设置为dtkTime即可,可以在每次Form onShow时将Dat ...
- ubuntu搭建vulhub漏洞环境
0x01 简介 Vulhub是一个面向大众的开源漏洞靶场,无需docker知识,简单执行两条命令即可编译.运行一个完整的漏洞靶场镜像.旨在让漏洞复现变得更加简单,让安全研究者更加专注于漏洞原理本身. ...
- java 一维数组的总结笔记
数组 1. 一位数组的声明方式 type[] array Name 或 type arrayName[];(推荐使用第二种) 错误的声明方式 //int[5] intErrorArray;错误的 // ...
- nodejs之https双向认证
说在前面 之前我们总结了https的相关知识,如果不懂可以看我另一篇文章:白话理解https 有关证书生成可以参考:自签证书生成 正题 今天使用nodejs来实现https双向认证 话不多说,直接进入 ...
- PHP 新特性:如何善用接口与Trait
首先! 接口也可以继承,通过使用 extends 操作符. 案例: <?php interface a { public function foo(); } interface b extend ...
- Metasploit渗透测试环境搭建
渗透测试实验环境搭建 下载虚拟机镜像 5个虚拟机镜像,其中Linux攻击机我选择用最新的kali Linux镜像,其余的均使用本书配套的镜像. 网络环境配置 VMware虚拟网络编辑器配置: 将VMn ...
- 存储-raid
- 牛客网练习赛61 A+B
A.打怪 思路:先判定当小怪的攻击力为0时,你能杀无数只怪,因为小怪A不动你,然后再计算每个小怪最多能给你造成多少伤害(用小怪的血量除以你的攻击力,也就是你砍它几下它会死,你先手,所以小怪肯定比你少砍 ...
- USACO Training Section 1.3混合牛奶 Mixing Milk
题目描述 由于乳制品产业利润很低,所以降低原材料(牛奶)价格就变得十分重要.帮助Marry乳业找到最优的牛奶采购方案. Marry乳业从一些奶农手中采购牛奶,并且每一位奶农为乳制品加工企业提供的价格是 ...
- ACM学习总结 6月11日
经过这几天没有队友的协助,又是算法题比较多,有点碰触到自己的短板,因为搜索的题目就做了1个,一遇到搜索就跳过,DP也有点忘得差不多了,四边形优化,斜率优化还不会,这是下一阶段努力方向,把之前做过的题, ...