Group by 优化
一个标准的 Group by 语句包含排序、分组、聚合函数,比如 select a,count(*) from t group by a ; 这个语句默认使用 a 进行排序。如果 a 列没有索引,那么就会创建临时表来统计 a和 count(*),然后再通过 sort_buffer 按 a 进行排序。
标准的执行流程
结构:
create table t1(id int primary key, a int, b int, index(a));
delimiter ;;
create procedure idata()
begin
declare i int; set i=1;
while(i<=1000)do
insert into t1 values(i, i, i);
set i=i+1;
end while;
end;;
delimiter ;
call idata();
函数就是向 t1 中插入1000条语句,从(1,1,1) 到(1000,1000,1000)。
执行 select id%10 as m, count(*) as c from t1 group by m;
解析:

Using index,表示这个语句使用了覆盖索引,选择了索引 a,不需要回表;
Using temporary,表示使用了临时表;
Using filesort,表示需要排序。
过程:
1、创建内存临时表,表里有两个字段 m 和 c,主键是 m;
2、扫描表 t1 的索引 a,依次取出叶子节点上的 id 值,计算 id%10 的结果,记为 x;
1)如果临时表中没有主键为 x 的行,就插入一个记录 (x,1);
2)如果表中有主键为 x 的行,就将 x 这一行的 c 值加 1;
第2 步如果发现内存临时表存储的总字段长度到达参数 tmp_table_size 设置的大小,那么就会将内存临时表升级为磁盘临时表,然后重新开始遍历计算。
3、遍历完成后,再根据字段 m 做排序,得到结果集返回给客户端。
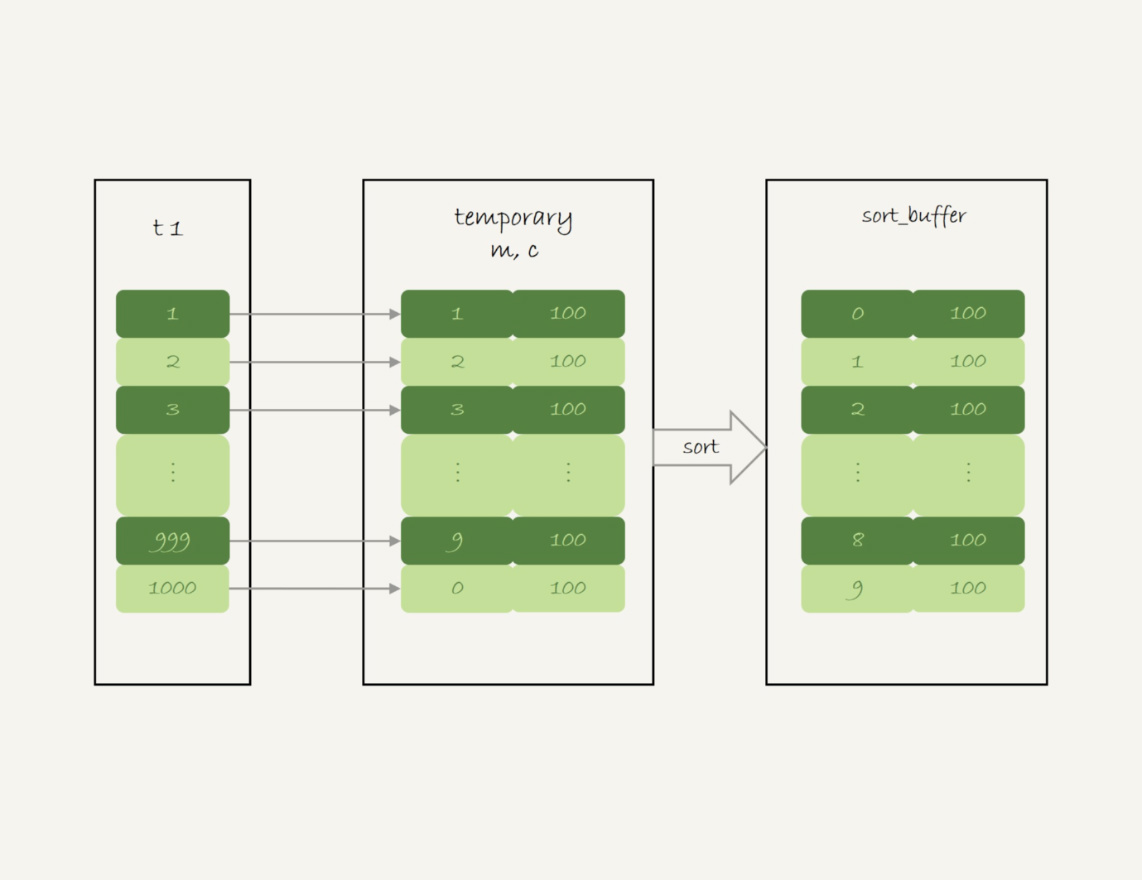
最后的排序就是下图虚线框中的操作,如果 sort_buffer 设置的大小不够大,那么就会使用临时表来辅助排序。
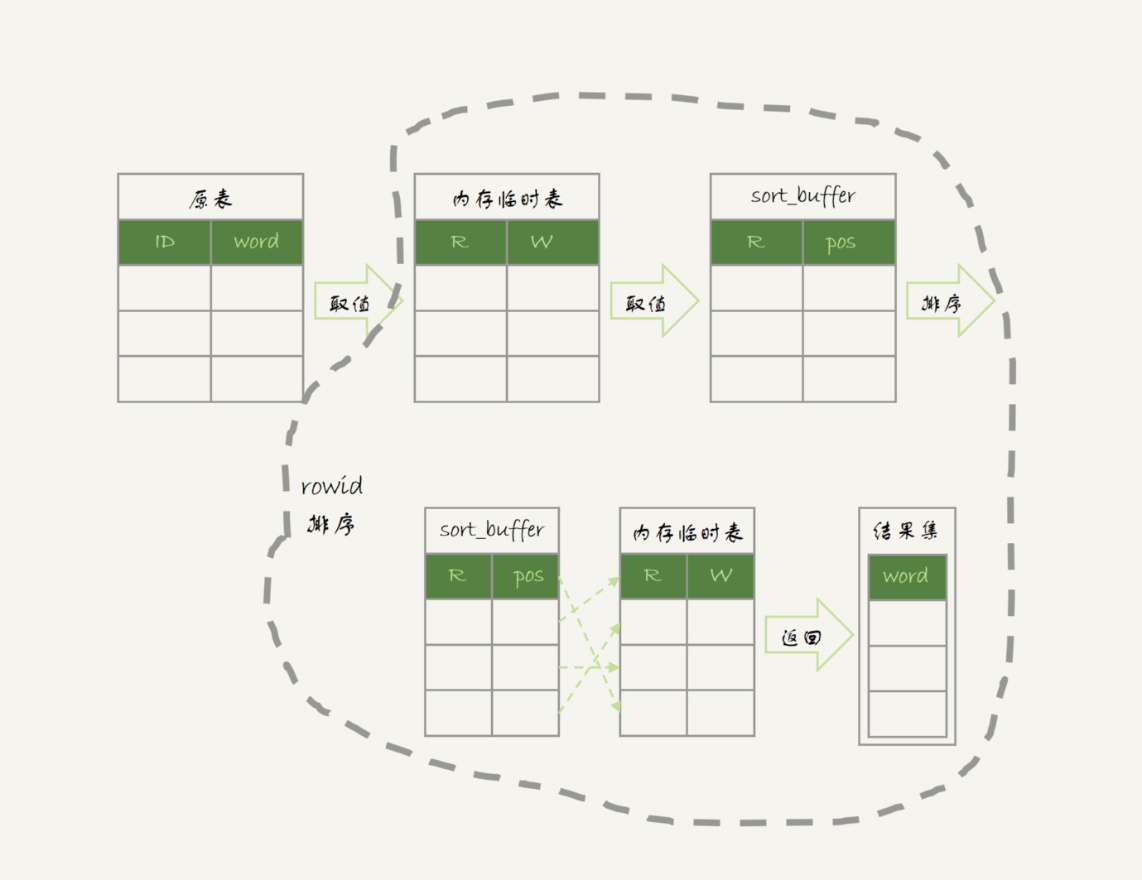
优化
未优化(也就是分组列没有索引)的 group by 的总过程可以概括为:因为数据是无序的,所以需要创建临时表,然后一个一个判断属于哪个分组,最后再根据分组列进行排序。所以,优化可以有两个思路:
去掉排序
在明确返回的数据不需要排序的情况下,可以禁止排序,也就是将上面的语句改成 select a,count(*) from t group by a order by null。
顺序排列
如果记录都按照排序字段排序,那么数据就变成了下面的结构:

这样在实际获取要返回的字段或计算聚合函数时,只需要按顺序依次访问,等到列值变成下一个就知道当前组访问结束,将之前统计的数据直接返回。这样就避免了创建临时表,同时排序也不需要使用 sort_buffer 进行额外排序。这样就极大地提高了执行的效率。
实现
1、如果分组字段适合创建索引就直接为分组字段创建索引。
MySQL 5.7 版本支持了 generated column 机制,用来实现列数据的关联更新。你可以用下面的方法创建一个列 z,然后在 z 列上创建一个索引(如果是 MySQL 5.6 及之前的版本,你也可以创建普通列和索引,来解决这个问题)
alter table t1 add column z int generated always as(id % 100), add index(z);
然后解析:

这时没有用到临时表和额外排序,所以性能提升。
2、如果分组字段不适合(使用率很低),那么可以使用 SQL_BIG_RESULT 来尝试优化。
在 group by 语句中加入 SQL_BIG_RESULT 这个提示(hint),就可以告诉优化器:这个语句涉及的数据量很大,请直接用磁盘临时表。MySQL 的优化器一看,磁盘临时表是 B+ 树存储,存储效率不如数组来得高。所以,既然使用SQL_BIG_RESULT来说明数据量很大,那从磁盘空间考虑,还是直接用数组来存吧。所以在使用 SQL_BIG_RESULT 后优化器会使用数组结构的磁盘临时表。
但是如果在未达到磁盘临时表的使用条件是不会使用磁盘临时表的,也就是在 sort_buffer 空间能够存储要返回和排序的总字段长度时,就使用数组结构的 sort_buffer ,如果总字段超过 sort_buffer 大小,那么就再加上数组结构的磁盘临时表来帮助排序。
那么在 sort_buffer 空间足够的情况下, sort_buffer 内部就会对数据进行排序,这样也就起到了索引的作用,
还是以上面的例子来看,使用 SQL_BIG_RESULT
alter table t1 add column z int generated always as(id % 100), add index(z);
具体过程如下:
1、初始化 sort_buffer,确定放入一个整型字段,记为 m;
2、扫描表 t1 的索引 a,依次取出里面的 id 值, 将 id%10 的值存入 sort_buffer 中;
3、扫描完成后,对 sort_buffer 的字段 m 做排序(如果 sort_buffer 内存不够用,就会利用磁盘临时文件辅助排序);
4、排序完成后,就得到了一个有序数组。
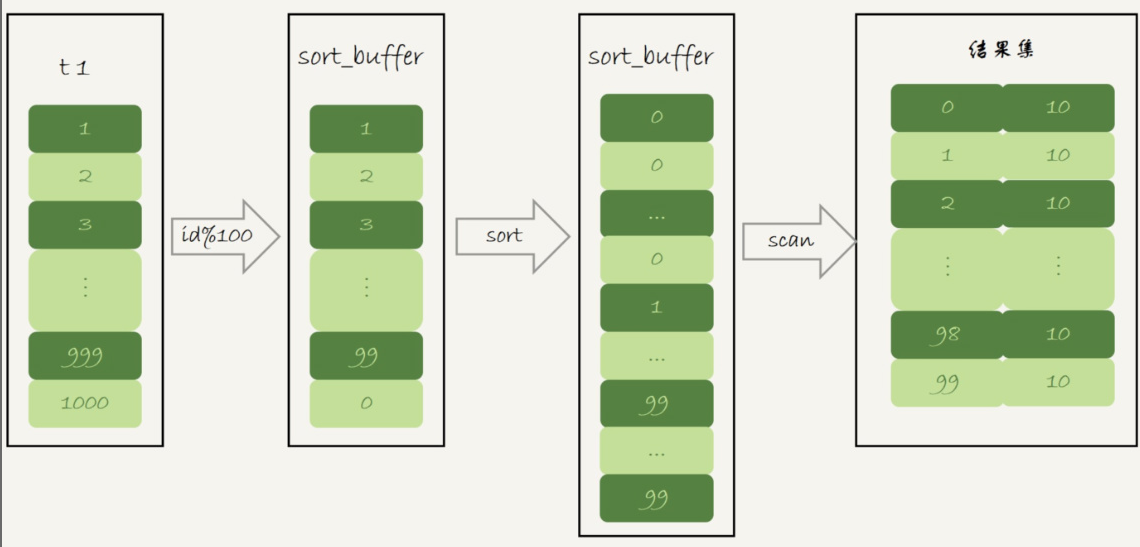
解析:

可以看到此时就没有使用临时表了,而是直接使用 sort_buffer 进行排序,这样就省去了使用临时表带来的性能消耗。
总结
1、如果对 group by 语句的结果没有排序要求,要在语句后面加 order by null;那么一般情况就不需要使用临时表了(上面两个优化都是在要求排序的前提下提出的优化方式)
2、尽量让 group by 过程用上表的索引,确认方法是 explain 结果里没有 Using temporary 和 Using filesort;
3、如果 group by 需要统计的数据量不大,尽量只使用内存临时表;也可以通过适当调大 tmp_table_size 参数,来避免用到磁盘临时表;
4、如果数据量实在太大,使用 SQL_BIG_RESULT 这个提示,来告诉优化器直接使用排序算法得到 group by 的结果。
Group by 优化的更多相关文章
- Mysql查询优化汇总 order by优化例子,group by优化例子,limit优化例子,优化建议
Mysql查询优化汇总 order by优化例子,group by优化例子,limit优化例子,优化建议 索引 索引是一种存储引擎快速查询记录的一种数据结构. 注意 MYSQL一次查询只能使用一个索引 ...
- Hive:表1inner join表2结果group by优化
问题背景 最近遇到一个比较棘手的事情:hive sql优化: lib表(id,h,soj,noj,sp,np) --一个字典表 mitem表(md,mt,soj,noj,sp,np)- ...
- 6.4 group by 优化
1.小总结 group by 实质是先排序后进行分组,遵照索引建的最佳左前缀. 当无法使用索引列,增大max_length_for_sort_data参数的设置 + 增大sort_buffer_siz ...
- MySQL高级 之 order by、group by 优化
参考: https://blog.csdn.net/wuseyukui/article/details/72627667 order by示例 示例数据: Case 1 Case 2 Case 3 ...
- mysql group by优化
mysql> explain select actor.first_name,actor.last_name,count(*) from sakila.film_actor inner join ...
- distinct用group by优化
当数据量非常大,在同一个query中计算多个不相关列的distinct时,往往很容易出现数据倾斜现象,导致运行半天都不能得到结果. 比如以下的SQL语句(a, b, c没有相关性): select d ...
- Mysql group by,order by,dinstict优化
1.order by优化 2.group by优化 3.Dinstinct 优化 1.order by优化 实现方式: 1. 根据索引字段排序,利用索引取出的数据已经是排好序的,直接返回给客户端: 2 ...
- ORDER BY,GROUP BY 和DI STI NCT 优化
读<MySQL性能调优与架构设计>笔记之ORDER BY,GROUP BY 和DI STI NCT 优化 2015年01月18日 18:51:31 lihuayong 阅读数:2593 标 ...
- [MySQL Reference Manual] 8 优化
8.优化 8.优化 8.1 优化概述 8.2 优化SQL语句 8.2.1 优化SELECT语句 8.2.1.1 SELECT语句的速度 8.2.1.2 WHERE子句优化 8.2.1.3 Range优 ...
随机推荐
- [论文分享] DHP: Differentiable Meta Pruning via HyperNetworks
[论文分享] DHP: Differentiable Meta Pruning via HyperNetworks authors: Yawei Li1, Shuhang Gu, etc. comme ...
- 什么是可变参数?如何创建不可变集合?Steam三类方法是什么?获取流方法特点?流中间方法特点?终结流方法特点?
==知识梳理== ==重难点梳理== ==今日目标== 1.能够了解什么是可变参数 2.能够了解如何去创建不可变集合 3.能够掌握Stream流的使用 ==知识点== 1.可变参数 2.Stream流 ...
- [永恒之黑]CVE-2020-0796(漏洞复现)
实验环境: 靶机:windows10 1903 专业版 攻击机:kali 2020.3 VMware:vmware14 实验工具: Python 3.8.5 msfconsole 实验PROC: ...
- 用anaconda的pip安装第三方python包
启动anaconda命令窗口: 开始> 所有程序> anaconda> anaconda prompt会得到两行提示: Deactivating environment " ...
- Windows Terminal 新手入门
翻译自 Kayla Cinnamon 2020年12月17日的文章<Getting Started with Windows Terminal> [1] 安装 Windows Termin ...
- 线程方法wait()和notify()的使用
实现需求: 开启2个线程,1个线程对某个int类型成员变量加1,另外1个减1,但是要次序执行,即如果int型的成员变量是0,则输出01010101这样的结果 代码如下 1 package test; ...
- 微信小程序--仿微信小程序朋友圈Pro(内容发布、点赞、评论、回复评论)
微信小程序--仿微信小程序朋友圈Pro(内容发布.点赞.评论.回复评论) 项目开源地址M朋友圈Pro 求个Star 项目背景 基于原来的开源项目 微信小程序仿朋友圈功能开发(发布.点赞.评论等功能 ...
- Elastisearch在kibana下常用命令总结
1.获取所有数据 GET /_search 2.创建一个Document PUT /ecommerce/product/1 { "name" : "gaolujie ya ...
- 初识sa-token,一行代码搞定登录授权!
前言 在java的世界里,有很多优秀的权限认证框架,如Apache Shiro.Spring Security 等等.这些框架背景强大,历史悠久,其生态也比较齐全. 但同时这些框架也并非十分完美,在前 ...
- Flutter 基础组件:Widget简介
概念 在Flutter中几乎所有的对象都是一个Widget.与原生开发中"控件"不同的是,Flutter中的Widget的概念更广泛,它不仅可以表示UI元素,也可以表示一些功能性的 ...