梯度下降(Gradient Descent)相关概念
梯度,直观理解:
梯度: 运算的对像是纯量,运算出来的结果会是向量在一个标量场中,
梯度的计算结果会是"在每个位置都算出一个向量,而这个向量的方向会是在任何一点上从其周围(极接近的周围,学过微积分该知道甚么叫极限吧?)标量值最小处指向周围标量值最大处.而这个向量的大小会是上面所说的那个最小与最大的差距程度"
举例子来讲会比较简单,如果现在的纯量场用一座山来表示,纯量值越大的地方越高,反之则越低.经过梯度这个运操作数的运算以后,会在这座山的每一个点上都算出一个向量,这个向量会指向每个点最陡的那个方向,而向量的大小则代表了这个最陡的方向到底有多陡.
梯度下降的直观理解:简而言之,就是下山不知道路怎么走,就走一步算一步
重要概念:
梯度下降(Gradient Descent)小结
如下图,梯度下降不一定能够找到全局的最优解,有可能是一个局部最优解。当然,如果损失函数是凸函数,梯度下降法得到的解就一定是全局最优解。
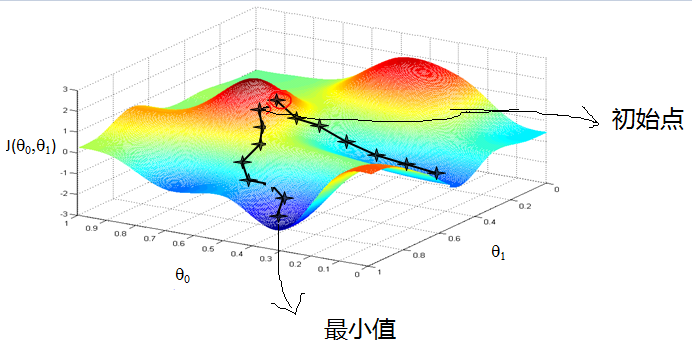
在详细了解梯度下降的算法之前,我们先看看相关的一些概念。
1. 步长(Learning rate):步长决定了在梯度下降迭代的过程中,每一步沿梯度负方向前进的长度。用上面下山的例子,步长就是在当前这一步所在位置沿着最陡峭最易下山的位置走的那一步的长度。
2.特征(feature):指的是样本中输入部分,比如样本(x0,y0),(x1,y1),则样本特征为x,样本输出为y。
3. 假设函数(hypothesis function):在监督学习中,为了拟合输入样本,而使用的假设函数,记为hθ(x)。比如对于样本(xi,yi)(i=1,2,...n),可以采用拟合函数如下: hθ(x) = θ0+θ1x。
4. 损失函数(loss function):为了评估模型拟合的好坏,通常用损失函数来度量拟合的程度。损失函数极小化,意味着拟合程度最好,对应的模型参数即为最优参数。在线性回归中,损失函数通常为样本输出和假设函数的差取平方。比如对于样本(xi,yi)(i=1,2,...n),采用线性回归,损失函数为:
\(J(\theta_0, \theta_1) = \sum\limits_{i=1}^{m}(h_\theta(x_i) - y_i)^2\)
其中\(x_i\)表示样本特征x的第i个元素,\(y_i\)表示样本输出y的第i个元素,\(h_\theta(x_i)\)为假设函数。


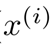 表示向量x中的第i个元素;
表示向量x中的第i个元素;
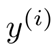 表示向量y中的第i个元素;
表示向量y中的第i个元素; 表示已知的假设函数;
表示已知的假设函数;|
比如给定数据集(1,1)、(2,2)、(3,3) |
梯度下降(Gradient Descent)相关概念的更多相关文章
- 机器学习(1)之梯度下降(gradient descent)
机器学习(1)之梯度下降(gradient descent) 题记:最近零碎的时间都在学习Andrew Ng的machine learning,因此就有了这些笔记. 梯度下降是线性回归的一种(Line ...
- 梯度下降(Gradient Descent)小结 -2017.7.20
在求解算法的模型函数时,常用到梯度下降(Gradient Descent)和最小二乘法,下面讨论梯度下降的线性模型(linear model). 1.问题引入 给定一组训练集合(training se ...
- 梯度下降(gradient descent)算法简介
梯度下降法是一个最优化算法,通常也称为最速下降法.最速下降法是求解无约束优化问题最简单和最古老的方法之一,虽然现在已经不具有实用性,但是许多有效算法都是以它为基础进行改进和修正而得到的.最速下降法是用 ...
- (二)深入梯度下降(Gradient Descent)算法
一直以来都以为自己对一些算法已经理解了,直到最近才发现,梯度下降都理解的不好. 1 问题的引出 对于上篇中讲到的线性回归,先化一个为一个特征θ1,θ0为偏置项,最后列出的误差函数如下图所示: 手动求解 ...
- CS229 2.深入梯度下降(Gradient Descent)算法
1 问题的引出 对于上篇中讲到的线性回归,先化一个为一个特征θ1,θ0为偏置项,最后列出的误差函数如下图所示: 手动求解 目标是优化J(θ1),得到其最小化,下图中的×为y(i),下面给出TrainS ...
- 梯度下降(Gradient descent)
首先,我们继续上一篇文章中的例子,在这里我们增加一个特征,也即卧室数量,如下表格所示: 因为在上一篇中引入了一些符号,所以这里再次补充说明一下: x‘s:在这里是一个二维的向量,例如:x1(i)第i间 ...
- 机器学习中的数学(1)-回归(regression)、梯度下降(gradient descent)
版权声明: 本文由LeftNotEasy所有,发布于http://leftnoteasy.cnblogs.com.如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任. 前言: ...
- 回归(regression)、梯度下降(gradient descent)
本文由LeftNotEasy所有,发布于http://leftnoteasy.cnblogs.com.如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任. 前言: 上次写过一篇 ...
- 吴恩达深度学习:2.3梯度下降Gradient Descent
1.用梯度下降算法来训练或者学习训练集上的参数w和b,如下所示,第一行是logistic回归算法,第二行是成本函数J,它被定义为1/m的损失函数之和,损失函数可以衡量你的算法的效果,每一个训练样例都输 ...
- (3)梯度下降法Gradient Descent
梯度下降法 不是一个机器学习算法 是一种基于搜索的最优化方法 作用:最小化一个损失函数 梯度上升法:最大化一个效用函数 举个栗子 直线方程:导数代表斜率 曲线方程:导数代表切线斜率 导数可以代表方向, ...
随机推荐
- 手动制作openstack CentOS 镜像
https://docs.openstack.org/image-guide/centos-image.html This example shows you how to install a Cen ...
- Python random模块sample、randint、shuffle、choice随机函数
一.random模块简介 Python标准库中的random函数,可以生成随机浮点数.整数.字符串,甚至帮助你随机选择列表序列中的一个元素,打乱一组数据等. 二.random模块重要函数 1 ).ra ...
- 在pypi上发布python包详细教程
使用Python编程中Python的包安装非常方便,一般都是可以pip来安装搞定:pip install <package name>,我们自己写的python也可以发布在pypi上,很简 ...
- LOJ 2553 「CTSC2018」暴力写挂——边分治+虚树
题目:https://loj.ac/problem/2553 第一棵树上的贡献就是链并,转化成 ( dep[ x ] + dep[ y ] + dis( x, y ) ) / 2 ,就可以在第一棵树上 ...
- golang查看channel缓冲区的长度
golang提供内建函数cap用于查看channel缓冲区长度. cap的定义如下: func cap(v Type) int The cap built-in function returns th ...
- java -jar 执行jar包出现 java.lang.NoClassDefFoundError
我用idea工具将自己开发java程序打成一个可执行的jar包,当然用eclipse或者直接用jar命令行都无所谓,本质都是将程序归档到一个压缩包,并附带一个说明清单文件. 打jar的操作其实很简单, ...
- sql日期操作
日期格式化函数 ), ): :57AM ), ): ), ): ), ): ), ): ), ): ), ): ), ): , ), ): :: ), ): :::827AM ), ): ), ): ...
- ML: 聚类算法R包-对比
测试验证环境 数据: 7w+ 条,数据结构如下图: > head(car.train) DV DC RV RC SOC HV LV HT LT Type TypeName 1 379 85.09 ...
- 【java】构造函数
什么时候自定义构造函数:当分析事物时,事物一存在就具备一些特征或者行为,那么就把这么内容定义在构造函数中 作用:对对象进行初始化,对象一建立,就会自动调用与之对应的构造函数 特点: 1.函数名和类名相 ...
- Winfrom控件使用
1.Lablelable添加图片,解决图片和字体重叠? Text属性添加足够空格即可,显示效果如下所示: 2.根据窗体名称获取窗体并显示到指定panel? Label item = sender as ...