Python3爬取起猫眼电影实时票房信息,解决文字反爬~~~附源代码
上文解决了起点中文网部分数字反爬的信息,详细链接https://www.cnblogs.com/aby321/p/10214123.html
本文研究另一种文字反爬的机制——猫眼电影实时票房反爬
虽然都是仅仅在“数字”上设置了反爬,相同点与不同点如下:
相同点:
在“数字”上设置了文字反爬
通过浏览器的“检查”显示的是“□”,但是可以在网页源代码中找到映射后的数字
正则爬的是网页源代码,xpath是默认utf-8解析网页数据,用xpath爬出来的也是方框,因此只能使用正则匹配爬取关键数字信息
不同点:
起点中文网:
每次刷新网页,通过正则爬取的数字不发生变化
使用了自定义的文字文件ttf,可爬虫提取ttf的下载地址,通过分析字体文件可以找到映射关系,并且这个映射关系是固定的 猫眼电影:
每次刷新网页(中间间隔几秒时间),通过正则爬取的数字发生变化
无字体文件ttf
在源代码中搜索‘font-face’可查询到一堆字符串,预测应该是base64的编码方式,但是每次刷新网页这段字符串均会发生变化
也就是说即使通过FontTools包将这段字符串转换成ttf文件,但是每次一刷新生成的ttf文件均会发生变化,因此ttf文件中的key和value也都发生了变化

映射关系怎么找呢?
通过研究发现,虽然每次ttf不一样,但是通过ttf生成的xml文件中TTGlyph中的坐标轴所表示的“数”是固定的,这也是我们要寻找的潜在对应关系
举个栗子:
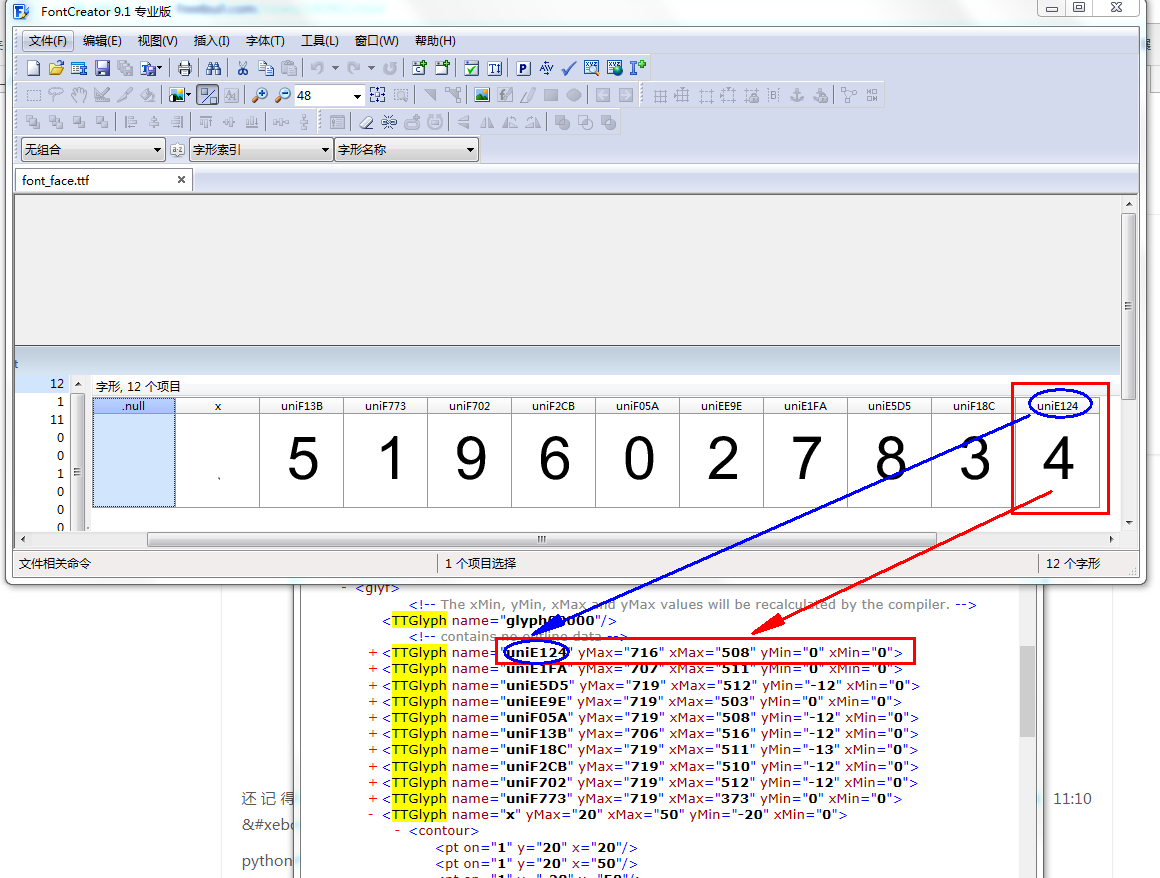
生成的这个ttf通过FontCreator软件查看,例如‘uniE124’对应的是数字‘4’
这个ttf生成的xml文件通过浏览器打开查看‘uniE124’对应的坐标是红色框内的内容;
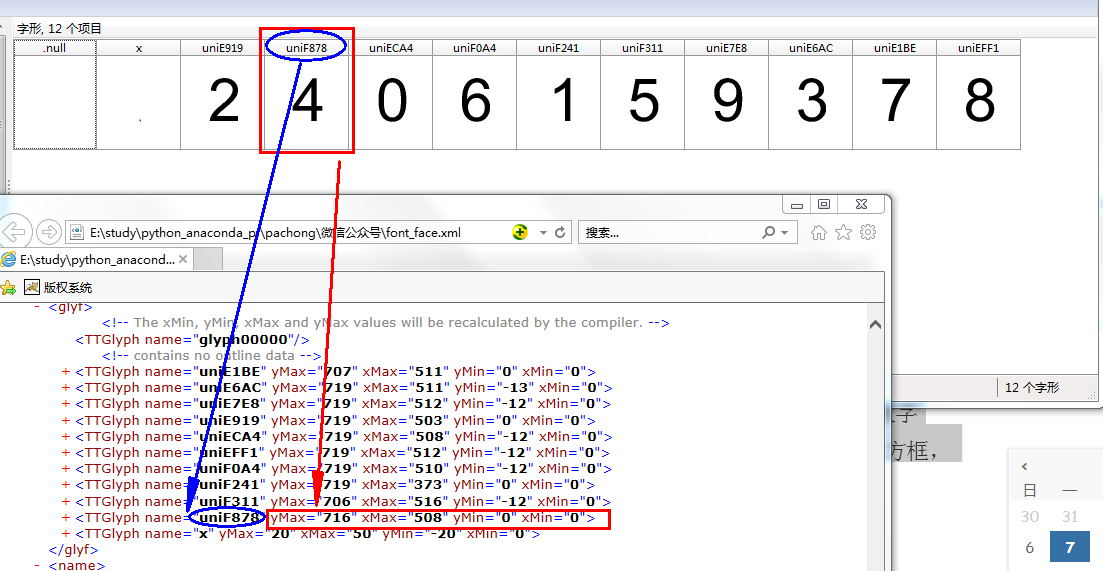
再次刷新网页,生成了新的ttf文件,重复上两个步骤,可以看到‘uniF878’对应的数字是‘4’,生成的xml文件中‘uniF878’对应的坐标与上个xml中的一样
因此可以断定映射关系为:
任意一次生成的xml中数字潜在对应的坐标是固定的
爬取思路
1. 某次提取网页源代码中的font-face中base64后面一段字符串,生成ttf文件和xml文件,并保存到本地
2. 通过这两个文件研究其坐标和数字的对应关系,这个关系是固定不变的,每次生成的ttt/xml不同但是其内部对应关系都是这个,手动写入字典
本例中的对应关系如下:
fontdict_local = {
'uniE346':7,
'uniE3DB':2,
'uniE4AC':4,
'uniE6BF':5,
'uniEA17':0,
'uniEBBC':1,
'uniEF7E':9,
'uniF227':3,
'uniF4C0':8,
'uniF551':6
}
3. 通过正则匹配爬取网页源代码中设置了反爬机制的数字,并进行数据前期处理

本例中需要进行以“;”分片,去掉“&#x”,判断是否含有小数点“.”,英文字母大小写转换等
4. 最重要的一步,进行比对
因为每次刷新页面或者重新运行程序都相当于会生成一个新的ttf/xml文件,因此需要将新的文件与第1步生成的文件(已保存到本地)进行坐标比对
比如新文件中若有个数字对应的坐标与本地文件中的坐标是一样的,那么就根据第2步的字典判断这个数字,在程序中坐标可以用编码对象替换
local代表是本地的文件
font_local = TTFont('font_face_local.ttf')
codelist_local = font_local.getGlyphNames()[1:-1]#第一个和最后一元素不是0-9的编码
输出(codelist_local其实就是字典的keys,只不过通过读取ttf文件自动获取,但是注意要判断下这个列表,总共有12个元素,有两个元素不是0-9的key):codelist: ['uniE346', 'uniE3DB', 'uniE4AC', 'uniE6BF', 'uniEA17', 'uniEBBC', 'uniEF7E', 'uniF227', 'uniF4C0', 'uniF551']
for i in codelist_local:
obj_local = font_local['glyf'][i]#获取本地字体文件数字0-9的编码对象
输出:
obj_local: <fontTools.ttLib.tables._g_l_y_f.Glyph object at 0x03465950>
obj_local: <fontTools.ttLib.tables._g_l_y_f.Glyph object at 0x03465930>
obj_local: <fontTools.ttLib.tables._g_l_y_f.Glyph object at 0x03465A30>
obj_local: <fontTools.ttLib.tables._g_l_y_f.Glyph object at 0x03465970>
obj_local: <fontTools.ttLib.tables._g_l_y_f.Glyph object at 0x03465A50>
obj_local: <fontTools.ttLib.tables._g_l_y_f.Glyph object at 0x034659B0>
obj_local: <fontTools.ttLib.tables._g_l_y_f.Glyph object at 0x034659D0>
obj_local: <fontTools.ttLib.tables._g_l_y_f.Glyph object at 0x03465990>
obj_local: <fontTools.ttLib.tables._g_l_y_f.Glyph object at 0x03465A10>
obj_local: <fontTools.ttLib.tables._g_l_y_f.Glyph object at 0x034659F0>
也就是说本地的编码对象obj_local和codelist_local是一一对应的,并且每次生成的文件获取的编码对象是固定不变的
每次运行生成的文件用同样的方法获取编码对象obj,与obj_local进行比对获取codelist_local值,在通过字典获取可展示的数值,还是通过图说明一下吧

源代码
"""
猫眼电影的票房等数据(数字)设置了文字反爬机制
不同于起点中文网能直接看见ttf文件,猫眼的数字反爬更复杂些,主要表现在:
进行了web上的base64编码,并且每次刷新都会变化
通过FontTools可生成ttf和xml文件,但是每次运行生成的文件都不一样
需要找寻其内部固定的映射关系
"""
import requests, time, re, pprint,base64
from fontTools.ttLib import TTFont
from io import BytesIO
from lxml import etree def get_relation(url):
"""
获取网页源代码中的font—face中的内容,并保存成.ttf格式的文件
:param url: <str> 需要解析的网页地址
:return:<dict> 网页字体(动态变化的)编码与阿拉伯数字的映射关系
"""
#获取网页源代码中的font—face中的内容
font_face = re.findall('base64,(.*?)\) format',html_data.text,re.S)[0]
#print(font_face)
#保存成.ttf格式的文件
b = base64.b64decode(font_face)
with open('font_face.ttf','wb') as f:
f.write(b)
font = TTFont('font_face.ttf')
font.saveXML('font_face.xml')#将ttf文件生成xml文件并保存到本地
codelist = font.getGlyphNames()[1:-1] # 第一个和最后一元素不是0-9的编码
font_local = TTFont('font_face_local.ttf')
font_local.saveXML('font_face_local.xml')
codelist_local = font_local.getGlyphNames()[1:-1]#第一个和最后一元素不是0-9的编码
print('codelist:',codelist_local)
fontdict_local = {
'uniE346':7,
'uniE3DB':2,
'uniE4AC':4,
'uniE6BF':5,
'uniEA17':0,
'uniEBBC':1,
'uniEF7E':9,
'uniF227':3,
'uniF4C0':8,
'uniF551':6
}
key = []
value = []
for i in codelist_local:
obj_local = font_local['glyf'][i]#获取本地字体文件数字0-9的编码对象
print('obj_local:',obj_local)
for k in codelist:
obj = font['glyf'][k]
#print('obj:',obj)
if obj == obj_local:
#print(k,fontdict_local[i])
key.append(k.strip('uni'))
value.append(fontdict_local[i])
dict_relation = dict(zip(key,value))#网页字体(动态变化的)编码与阿拉伯数字的映射关系 #print('网络文字映射关系:')
#pprint.pprint(dict_relation)
return dict_relation def get_decode_font(numberlist,relation):
"""
对反爬数字进行解码
:param numberlist: <list> 直接从网页源代码re获得的需要解码的数字
:param relation: <dict> 解码所需的映射关系
:return: <str> 解码后的数字
"""
data = ''
for i in numberlist:
numbers = i.replace('&#x','').upper()
#print(numbers)
#小数点没有单独成为里列表的元素,与后面的数字写在了一起,需要判断下
if len(numbers)==5:
data += '.'
numbers = numbers.strip('.')
#print('numbers:',numbers)
fanpa_data = str(relation[numbers])
data += fanpa_data
print('实时票房(万元):',data+'\n')
#return data
def get_movie_info(url):
"""
爬取网页的影片名称和实时票房(网页源代码中未解码的数字)
:param url:
:return:
"""
selector = etree.HTML(html_data.text)
infos = selector.xpath('//*[@id="ticket_tbody"]/ul')
boxes = re.findall('<b><i class="cs">(.*?)</i>',html_data.text,re.S)
for info,i in zip(infos,boxes):
movie_name = info.xpath('li[1]/b/text()')[0]
movie_box = i.split(';')[0:-1]
print('影片名称:',movie_name)
#print('网页直接获取的影片实时票房:',movie_box)#一维列表形式
relation = get_relation(url)
get_decode_font(movie_box,relation) url = 'https://piaofang.maoyan.com/?ver=normal'
headers = {
'User-Agent': 'User-Agent:Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
html_data = requests.get(url, headers=headers)
get_movie_info(url)
运行结果:


还有一种更加简洁的方法:
找到obj_local和数字的关系写入字典,去掉中间的codelist_local
Python3爬取起猫眼电影实时票房信息,解决文字反爬~~~附源代码的更多相关文章
- Python3爬取起点中文网阅读量信息,解决文字反爬~~~附源代码
起点中文网,在“数字”上设置了文字反爬,使用了自定义的文字文件ttf通过浏览器的“检查”显示的是“□”,但是可以在网页源代码中找到映射后的数字正则爬的是网页源代码,xpath是默认utf-8解析网页数 ...
- 一起学爬虫——使用xpath库爬取猫眼电影国内票房榜
之前分享了一篇使用requests库爬取豆瓣电影250的文章,今天继续分享使用xpath爬取猫眼电影热播口碑榜 XPATH语法 XPATH(XML Path Language)是一门用于从XML文件中 ...
- 基础爬虫,谁学谁会,用requests、正则表达式爬取豆瓣Top250电影数据!
爬取豆瓣Top250电影的评分.海报.影评等数据! 本项目是爬虫中最基础的,最简单的一例: 后面会有利用爬虫框架来完成更高级.自动化的爬虫程序. 此项目过程是运用requests请求库来获取h ...
- requests爬取豆瓣top250电影信息
''' 1.爬取豆瓣top250电影信息 - 第一页: https://movie.douban.com/top250?start=0&filter= - 第二页: https://movie ...
- Python进阶练习与爬取豆瓣T250的影片相关信息
(一)Python进阶练习 正所谓要将知识进行实践,才会真正的掌握 于是就练习了几道题:求素数,求奇数,求九九乘法表,字符串练习 import re #求素数 i=1; flag=0 while(i& ...
- python requests库网页爬取小实例:亚马逊商品页面的爬取
由于直接通过requests.get()方法去爬取网页,它的头部信息的user-agent显示的是python-requests/2.21.0,所以亚马逊网站可能会拒绝访问.所以我们要更改访问的头部信 ...
- Python 002- 爬虫爬取淘宝上耳机的信息
参照:https://mp.weixin.qq.com/s/gwzym3Za-qQAiEnVP2eYjQ 一般看源码就可以解决问题啦 #-*- coding:utf-8 -*- import re i ...
- 爬取豆瓣网图书TOP250的信息
爬取豆瓣网图书TOP250的信息,需要爬取的信息包括:书名.书本的链接.作者.出版社和出版时间.书本的价格.评分和评价,并把爬取到的数据存储到本地文件中. 参考网址:https://book.doub ...
- 使用Xpath爬取酷狗TOP500的歌曲信息
使用xpath爬取酷狗TOP500的歌曲信息, 将排名.歌手名.歌曲名.歌曲时长,提取的结果以文件形式保存下来.参考网址:http://www.kugou.com/yy/rank/home/1-888 ...
随机推荐
- 机器学习框架ML.NET学习笔记【2】入门之二元分类
一.准备样本 接上一篇文章提到的问题:根据一个人的身高.体重来判断一个人的身材是否很好.但我手上没有样本数据,只能伪造一批数据了,伪造的数据比较标准,用来学习还是蛮合适的. 下面是我用来伪造数据的代码 ...
- H5移动端原生长按事件
// 函数名longpress// 参数为: 需长按元素的id.长按之后处理函数func function longPress(id, func,timeout=500) { var timeOutE ...
- 属性(property)与成员变量(ivar)
类内使用成员变量{}, 类外使用属性@property /*********** --- Person.h */ @interface Person : NSObject { NSString *_n ...
- python.h没有那个文件或目录解决方法
我用的是Deepin Linux,这应该是linux平台的问题,别的linux os也是执行安装,命令不同而已,windows和Mac不太清楚. 如果你使用的是python2.x,那么使用下面的语句: ...
- Matlab之数据处理
写在前面的,软件不太强大,每次保存都需要生成rec和dark的文件,在处理是只需要一个就行了,所有网上查看了下运用批处理的命令去掉多余的文件: 解决办法:windows命令模式下CMD进入文件的目录, ...
- [Java]在xp系统下java调用wmic命令获取窗口返回信息无反应(阻塞)的解决方案
背景:本人写了一段java代码,调用cmd命令“wmic ...”来获取系统cpu.mem.handle等资源信息.在win7操作系统下运行没有问题,在xp系统下却发现读取窗口反馈信息时无反应(阻塞) ...
- pysnmp使用
install yum install python-pysnmp yum install python-pyasn1 or pip install pysnmp pip install pyasn1 ...
- 微信jssdk实现分享到微信
本来用的是这个插件http://overtrue.me/share.js/和百度分享 相同之处:在微信分享的时候,分享的链接都不能获取到缩略图... 不同之处:百度分享在微信低版本是可以看到缩略图的( ...
- SAP成都研究院的体育故事
"平生不识陈近南,纵称英雄也枉然". 这是清朝反government武装圈子里流传的一句话,给予了天地会CEO陈近南极高的评价. 同样,如果您是SAP体育运动界的一份子,而您还不认 ...
- 【51nod1443】路径和树(堆优化dijkstra乱搞)
点此看题面 大致题意:给你一个无向联通图,要求你求出这张图中从u开始的权值和最小的最短路径树的权值之和. 什么是最短路径树? 从\(u\)开始到任意点的最短路径与在原图中相比不变. 题解 既然要求最短 ...