Hadoop基础入门
一、hadoop是什么?
(1)Hadoop是一个开源的框架,可编写和运行分布式应用处理大规模数据,是专为离线和大规模数据分析而设计的,并不适合那种对几个记录随机读写的在线事务处理模式。Hadoop=HDFS(文件系统,数据存储技术相关)+ Mapreduce(数据处理),Hadoop的数据来源可以是任何形式,在处理半结构化和非结构化数据上与关系型数据库相比有更好的性能,具有更灵活的处理能力,不管任何数据形式最终会转化为key/value,key/value是基本数据单元。用函数式变成Mapreduce代替SQL,SQL是查询语句,而Mapreduce则是使用脚本和代码,而对于适用于关系型数据库,习惯SQL的Hadoop有开源工具hive代替。
(2)Hadoop就是一个分布式计算的解决方案。
二、hadoop的应用场景有哪些?
- 大数据量存储:分布式存储
- 日志处理: Hadoop擅长这个
- 海量计算: 并行计算
- ETL:数据抽取到oracle、mysql、DB2、mongdb及主流数据库
- 使用HBase做数据分析: 用扩展性应对大量的写操作—Facebook构建了基于HBase的实时数据分析系统
- 机器学习: 比如Apache Mahout项目
- 搜索引擎:hadoop + lucene实现
- 数据挖掘:目前比较流行的广告推荐
- 大量地从文件中顺序读。HDFS对顺序读进行了优化,代价是对于随机的访问负载较高。
- 数据支持并且最适用于一次写入,多次读取的场景。对于已经形成的数据的更新不支持。
- 数据不进行本地缓存(文件很大,且顺序读没有局部性)
- 任何一台服务器都有可能失效,需要通过大量的数据副本使得性能不会受到大的影响。
- 用户细分特征建模
- 个性化广告推荐
- 智能仪器推荐
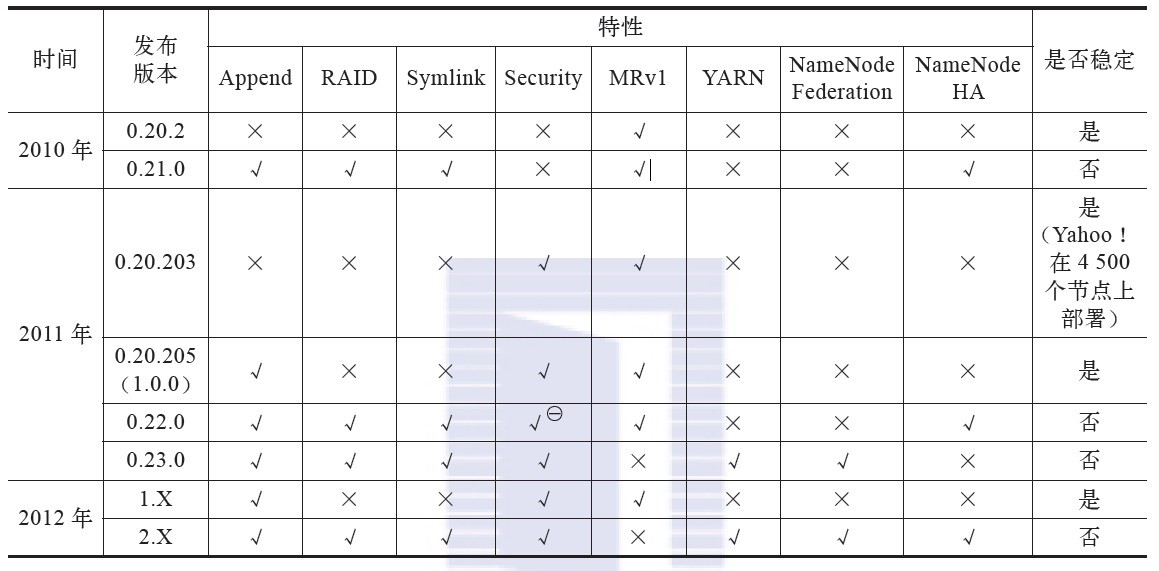
三、Hadoop各版本特性
四、Hadoop存储模型
Hadoop采用hbase做数据库,但由于hbase没有类sql查询方式,所以操作和计算数据非常不方便,于是整合hive,让hive支撑在hbase数据库层面 的 hql查询.hive也即 做数据仓库。
五、Hadoop的优缺点
Hadoop 在处理非结构数据和半结构数据上具备优势,尤其适合海量数据批处理等应用需求。
Hadoop基础入门的更多相关文章
- hadoop 基础入门
启动: 格式化节点:bin/hdfs namenode -format 全部启动:sbin/start-dfs:datanode.namenode sbi ...
- 大数据Hadoop基础入门到精通
1.hadoop前世今生: 1) 搜索引擎:网络爬虫+索引服务器(生成索引+检索) 2) Doung Cutting 3) Nutch a.分布式存储 b.分布式计算 4)GFS论文 doung c ...
- Hadoop学习笔记—2.不怕故障的海量存储:HDFS基础入门
一.HDFS出现的背景 随着社会的进步,需要处理数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是却不方便管理和维护—>因此,迫切需要一种系统来管理多 ...
- Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码
Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本文主要是记录一写我在学习MapReduce时的一些 ...
- 【原创 Hadoop&Spark 动手实践 5】Spark 基础入门,集群搭建以及Spark Shell
Spark 基础入门,集群搭建以及Spark Shell 主要借助Spark基础的PPT,再加上实际的动手操作来加强概念的理解和实践. Spark 安装部署 理论已经了解的差不多了,接下来是实际动手实 ...
- Cloudera Manager、CDH零基础入门、线路指导 http://www.aboutyun.com/thread-9219-1-1.html (出处: about云开发)
Cloudera Manager.CDH零基础入门.线路指导http://www.aboutyun.com/thread-9219-1-1.html(出处: about云开发) 问题导读:1.什么是c ...
- Hadoop基础-MapReduce的工作原理第一弹
Hadoop基础-MapReduce的工作原理第一弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在本篇博客中,我们将深入学习Hadoop中的MapReduce工作机制,这些知识 ...
- hadoop基础----hadoop理论(四)-----hadoop分布式并行计算模型MapReduce具体解释
我们在前一章已经学习了HDFS: hadoop基础----hadoop理论(三)-----hadoop分布式文件系统HDFS详细解释 我们已经知道Hadoop=HDFS(文件系统,数据存储技术相关)+ ...
- 1.2 Hadoop快速入门
1.2 Hadoop快速入门 1.Hadoop简介 Hadoop是一个开源的分布式计算平台. 提供功能:利用服务器集群,根据用户定义的业务逻辑,对海量数据的存储(HDFS)和分析计算(MapReduc ...
随机推荐
- 关于for循环的一个小问题
有如下程序: package com.lk.B; public class Test5 { public static void main(String[] args) { // TODO Auto- ...
- 基于PCL绘制模型并渲染
博客转载自:https://blog.csdn.net/wokaowokaowokao12345/article/details/51321988 前言 抛开算法层面不谈,要利用PCL库中PCLVis ...
- 2.Books
Books示例说明了Qt中SQL类如何被Model/View框架使用,使用数据库中存储的信息,创建丰富的用户界面. 首先介绍使用SQL我们需要了解的类: 1.QSqlDatabase: QSqlDat ...
- C# 操作Excel基础篇(读取Excel、写入Excel)
注意事项:Excel的数据表中最多只能储存65535行数据,超出后,需要将数据分割开来进行储存.同时对于Excel中的乱码象限,是由于编码的错误方式导致引起的! 一.读取Excel数据表,获得Data ...
- UIView 和 CALayer区别 为啥有UIView还要CALayer?
今天,被坑了,面试的时候没回答出来,特此记录一下 一.继承结构 1: UIView的继承结构为: UIResponder : NSObject UIResponder是用来响应事件的,也就是UIVie ...
- 关于jeecms修改首页进行测试
由于要学习,jeecms的标签使用,那么必须要有一个测试页.关于首页如何使之用之当测试页. 修改的步骤,找到web.xml文件修改 <welcome-file-list> <welc ...
- delphi 数组的使用
delphi中数组就跟string使用类似,数组分为:动态数组和静态数组 还可根据数据的功能分为:数组(一维数组).二维数组.三维数组...静态数组: 固定长度,内容需要定义时添加.动态数组: 故名思 ...
- 国外物联网平台(4):Ayla Networks
国外物联网平台(4)——Ayla Networks 马智 定位 Ayla企业软件解决方案为全球部署互联产品提供强大的工具 功能 Ayla的IoT平台包含3个主要组成部分: (1) Ayla嵌入式代理A ...
- go的Type switch是一个switch语句么?
相信这样的语句在go中大家见的很多 switch t := arg.(type) { default: fmt.Printf("unexpected type %T\n", t) ...
- 新建项目下的web文件夹下的dynamic web project和static web project和web fragment project的区别
dynamic web project是Eclipse的项目,与其对应的有static web project,前者指动态web项目,包含一些动态代码,如java:而static web projec ...