hadoop大作业
1.数据准备
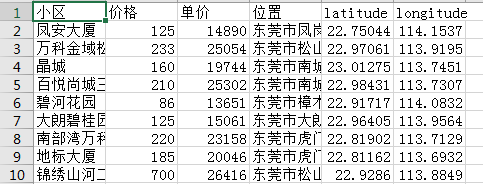
2.把CSV添加到/bigdatacase/dataset中

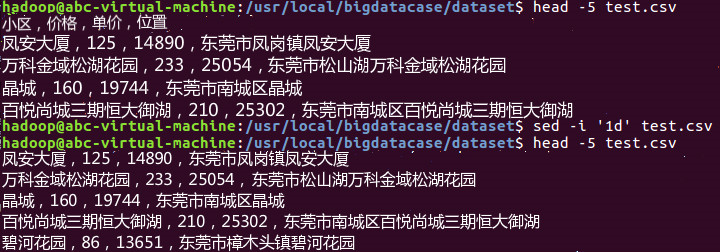
3.检查前5行并删除第一行
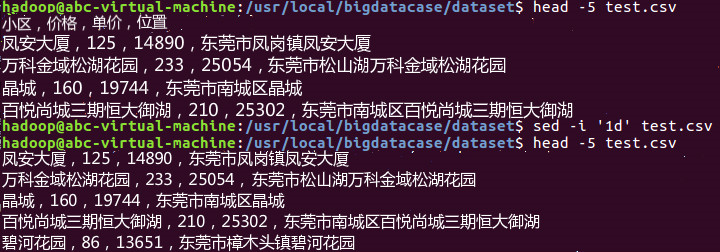
4.将csv文件导入hadoop并检查前10行数据情况
5.数据文件导入hive

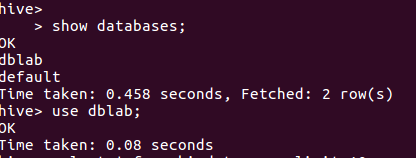
6.在Hive中查看并分析数据

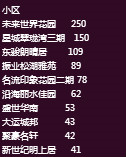
统计出用户所找小区数量最多的10个小区
可见未来世界花园小区深受人们居住的首选
7.:出现的问题解决:
在HIVE中进行查询时,会出现“无法分配内存”,后来内存调了解决问题
8.使用jieba根据字典分词,字典中存放了东莞所有镇区名字,
wordcloud生成词云图。

9.XGeocoding获取坐标
将爬取生成的csv文件导入XGeocoding中批量获取经纬度

Tableau可视化处理
将XGeocoding获取的坐标整合到csv中,作为数据源导入Tableau,设置维度经纬度为列行,地图使用高德的tms离线包,即可在地图中显示坐标点,再加入价格等参数进行数据可视化处理。
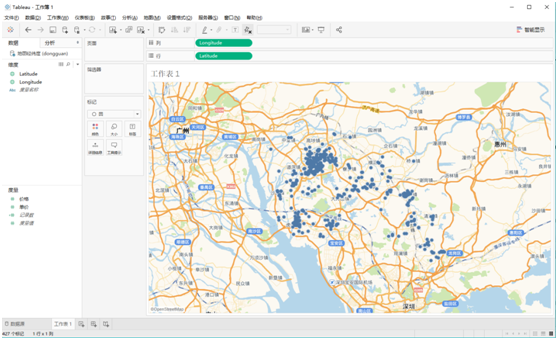
9.可视化分析结果:
房源热力图
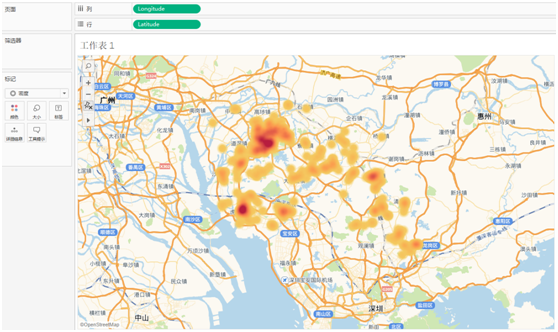
热力图更直观的看出来东莞城区和虎门镇房源更加密集
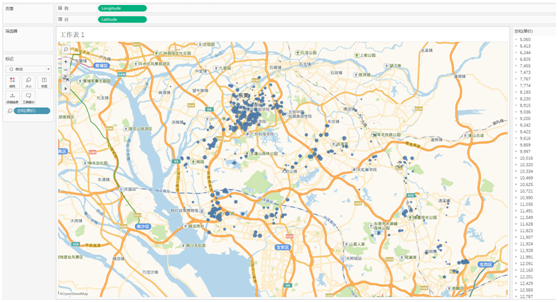
均价图

均价可以间接看出来哪里比较繁华,郊区的均价偏低
房价图
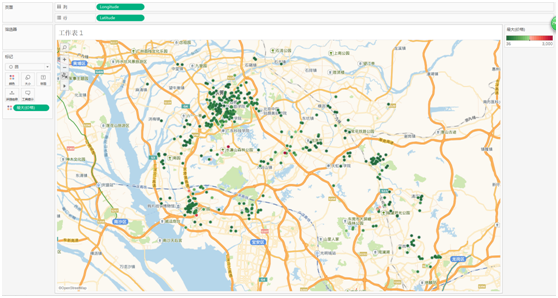
可以看出来,东莞的二手房价大部分都低于或等于平均值(绿色),部分房价高(红色)的一般都是依山傍水
hadoop大作业的更多相关文章
- 作业——12 hadoop大作业
作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 Hadoop综合大作业 1.以下是爬虫大作业产生的csv文件 ...
- Hadoop综合大作业
Hadoop综合大作业 要求: 用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)词频统计. 用Hive对爬虫大作业产生的csv文件进行数据分析 1. 用Hive对爬虫大作业产 ...
- 大数据应用期末总评——Hadoop综合大作业
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 Hadoop综合大作业 要求: 1.将爬虫大作业产生的csv文件 ...
- 【大数据应用期末总评】Hadoop综合大作业
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 一.Hadoop综合大作业 要求: 1.将爬虫大作业产生的csv ...
- 《Hadoop综合大作业》
作业要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 我主要的爬取内容是关于热门微博文章“996”与日剧<我要 ...
- 【大数据应用技术】作业十二|Hadoop综合大作业
本次作业的要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 前言 本次作业是在<爬虫大作业>的基础上进行的 ...
- 菜鸟学IT之Hadoop综合大作业
Hadoop综合大作业 作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363 1.将爬虫大作业产生的csv文件上传到HDF ...
- hadoop 综合大作业
作业要求来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 本次作业是在期中大作业的基础上利用hadoop和hive技术进行 ...
- 大数据应用期末总评Hadoop综合大作业
作业要求来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 1.将爬虫大作业产生的csv文件上传到HDFS 此次作业选取的 ...
随机推荐
- php学习笔记——学习路线图记录
PHP学习路线图 最全PHP自学指南 W3Cschool小编 2018-04-24 15:23:51 浏览数 (5381) 分享 收录专辑 对于广大零基础的PHP自学者,往往不知道如何系统的学习PHP ...
- CSS-锚点笔记
注意点: position属性 定义建议元素布局所用的定位机制 {position:static/absolute/relative/fixed;} static:默认值,没有定位 absolute: ...
- LCD 驱动 S3C2440A
LCD Control 1 Register 以16BPP为例 LCD Control 2 Register LCD Control 3 Register LCD Control 4 Register ...
- Linux Samba服务器的安装
Samba最大的功能就是可以用于Linux与windows系统直接的文件共享和打印共享,也可以用于Linux与Linux之间的资源共享 安装 # yum install samba samba-cli ...
- 深入理解JVM-java虚拟机栈
1.java虚拟机栈 1. Java虚拟机栈也是线程私有的,它的生命周期与线程相同(随线程而生,随线程而灭) 2. 如果线程请求的栈深度大于虚拟机所允许的深度,将抛出StackOverflowErro ...
- app开发-3
一.Audio 模块实现开启手机摄像头 基于html5 plus http://www.html5plus.org/doc/zh_cn/audio.html 栗子: 自定义: scanQR.HTM ...
- 编程小白入门分享一:git的最基本使用
git简介 引用了网上的一张图,这张图清晰表达git的架构.workspace是工作区,可以用编辑器直接编辑其中的文件:Index/Stage是暂存区,编辑后的文件可以添加到(add)暂存区:Repo ...
- shortcuts for contructor 创建对象捷径
- Hive UDF函数构建
1. 概述 UDF函数其实就是一个简单的函数,执行过程就是在Hive转换成MapReduce程序后,执行java方法,类似于像MapReduce执行过程中加入一个插件,方便扩展.UDF只能实现一进一出 ...
- test20190905 ChiTongZ
100+22+90=212.前两道题不错,但T3 没什么意义. 围观刘老爷超强 T1 解法. ChiTongZ的水题赛 [题目简介] 我本可以容忍黑暗,如果我不曾见过太阳. 考试内容略有超纲,不超纲的 ...