Hadoop2.8 安装
一、下载Hadoop与java
jdk-8u221-linux-x64.tar.gz Oracle官网下载
hadoop-2.8.5.tar.gz Hadoop官网下载
二、配置服务期间ssh免密互通
使用如下互信安装脚本
https://www.cnblogs.com/xibuhaohao/p/11772047.html
三、配置服务期间时钟同步服务
略
四、解压安装Hadoop文件与Java
1、解压缩(每个结点都要做)
1)安装Java
2)安装Hadoop
新建Hadoop用户
2、配置结点环境变量
cat .bash_profile
添加如下:
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/jre/bin:$PATH
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
五、修改配置文件
cd /home/hadoop/hadoop-2.8.5/etc/hadoop
1、core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://data0:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!-- 配置临时数据存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-2.8.5/tmp</value>
</property>
2、hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--hdfs的元数据存储位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/hadoop-2.8.5/hdfs/name</value>
</property>
<!--hdfs的数据存储位置-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/hadoop-2.8.5/hdfs/data</value>
</property>
<!--hdfs的namenode的web ui 地址-->
<property>
<name>dfs.http.address</name>
<value>data0:50070</value>
</property>
<!--hdfs的snn的web ui 地址-->
<!-- <property>
<name>dfs.secondary.http.address</name>
<value>data0:50090</value>
</property>
<!--是否开启web操作hdfs-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!--是否启用hdfs权限(acl)-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
3、mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value> </property>
<!--历史服务的通信地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>data0:10020</value>
</property>
<!--历史服务的web ui地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>data0:19888</value>
</property>
4、yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>data0</value>
</property>
<!--指定mapreduce的shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定resourcemanager的内部通讯地址-->
<property>
<name>yarn.resourcemanager.address</name>
<value>data0:8032</value>
</property>
<!--指定scheduler的内部通讯地址-->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>data0:8030</value>
</property>
<!--指定resource-tracker的内部通讯地址-->
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>data0:8031</value>
</property>
<!--指定resourcemanager.admin的内部通讯地址-->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>data0:8033</value>
</property>
<!--指定resourcemanager.webapp的ui监控地址-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>data0:8088</value>
</property>
六、启动Hadoop
1、初始化Namenode
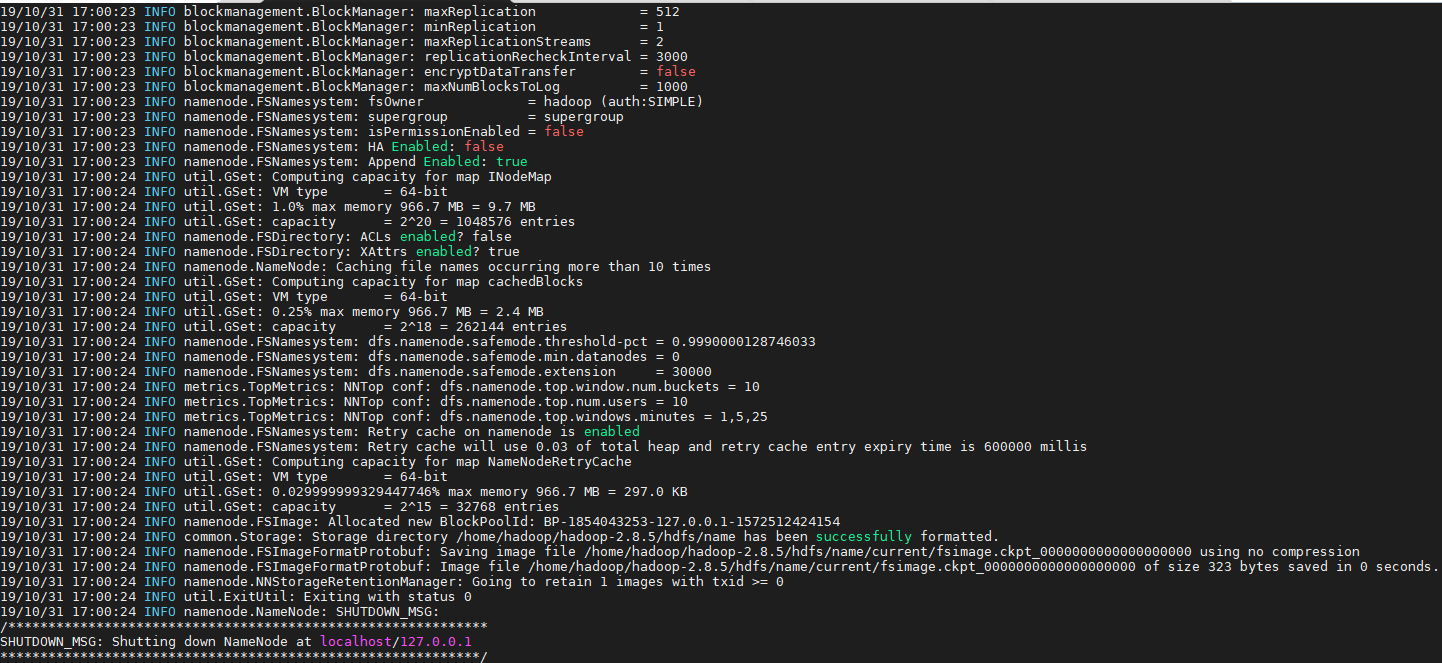
2、开启namenode

3、启动集群
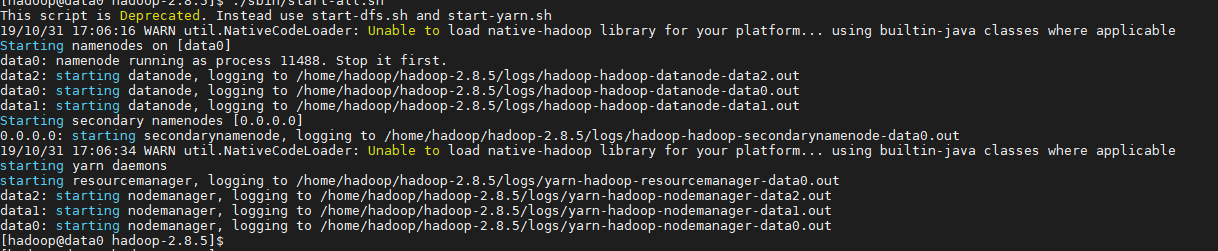
4、查看集群个资源是否启动
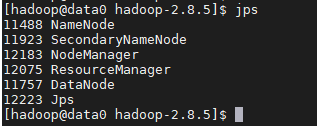
2)datanode1
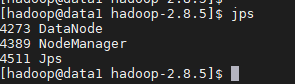
3)datanode2

七、网页登录
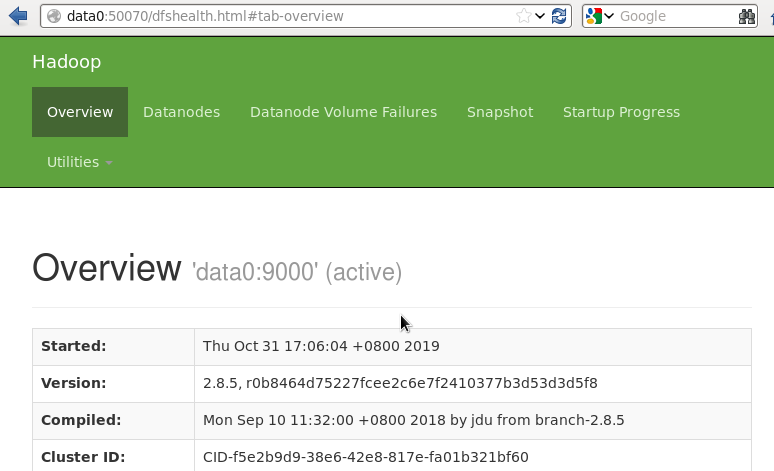
1、namenode
data0:50070
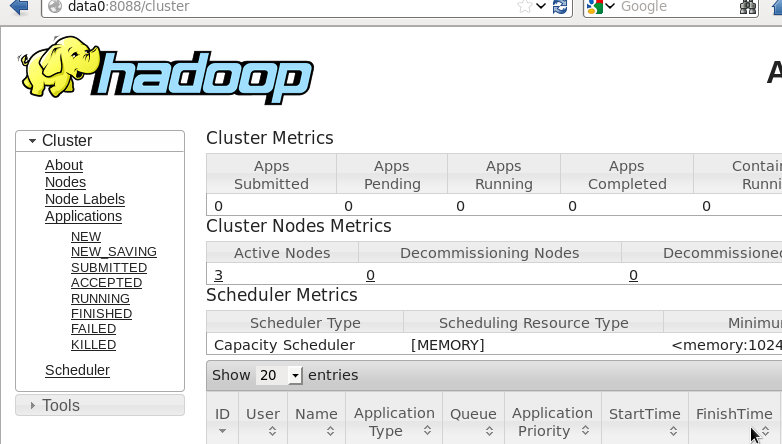
2、Hadoop
data0:8088
Hadoop2.8 安装的更多相关文章
- 跟我一起hadoop(1)-hadoop2.6安装与使用
伪分布式 hadoop的三种安装方式: Local (Standalone) Mode Pseudo-Distributed Mode Fully-Distributed Mode 安装之前需要 $ ...
- 完全分布式Hadoop2.3安装与配置
一.Hadoop基本介绍 Hadoop优点 1.高可靠性:Hadoop按位存储和处理数据 2.高扩展性:Hadoop是在计算机集群中完成计算任务,这个集群可以方便的扩展到几千台 3.高效性:Hadoo ...
- hadoop-2.5安装与配置
安装之前准备4台机器:bluejoe0,bluejoe4,bluejoe5,bluejoe9 bluejoe0作为master,bluejoe4,5,9作为slave bluejoe0作为nameno ...
- hadoop2.x 安装配置
hadoop2.x在系统架构上与hadoop1.x有很大的变化 原文地址: http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-y ...
- CentOS7.4 + Hadoop2.9安装配置管理(分布式)
1. 规划 1.1. 机器列表 NameNode SecondaryNameNode DataNodes 192.168.1.121 192.168.1.122 192.168.1.101 192 ...
- Hadoop2.6 安装布置问题总结(单机、分布式)
在debian7虚拟机上安装hadoop2.6,期间遇到一些问题在此记录一下. 安装参考: Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04 Hadoop集群安 ...
- centos6.5系统hadoop2.7安装sqoop
一.sqoop简介 Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql.postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ...
- hadoop2.3安装过程及问题解决
三台serveryiprod01,02,03,当中01为namenode,02为secondarynamenode.3个均为datanode 3台server的这里提到的配置均需一样. 0.安装前提条 ...
- hadoop2.x安装配置
1.首先准备hadoop2.2.0的安装包,从官网获取,略. 2.加压安装包,进行配置.假设hadoop安装到/usr/hadoop-2.2.0目录,则进行如下配置: (1)/etc/profile配 ...
- Hadoop2.0安装之非HA版
主要步骤跟Hadoop1.0(1.0安装地址)一致,主要在配置这块有更改 安装 下载地址:http://archive.apache.org/dist/hadoop/core/hadoop-2.6.5 ...
随机推荐
- go语言学习---使用os.Args获取简单参数(命令行解析)
实例1: //main package main import ( "fmt" "os" ) func main() { fmt.Println(os.Args ...
- mybatis 多个中间表查询映射
最近项目用到中间表,则遇到如何联查映射的问题,之前一直都是一个表头,多个明细或者一对一这样的关系,没遇到这样的问题,所以趁机找了下资料解决了这个问题. 表结构设计如下: 主表: CREATE TABL ...
- ASP.NET Core & 双因素验证2FA 实战经验分享
必读 本文源码核心逻辑使用AspNetCore.Totp,为什么不使用AspNetCore.Totp而是使用源码封装后面将会说明. 为了防止不提供原网址的转载,特在这里加上原文链接: https:// ...
- Java NIO和IO的区别
下表总结了Java NIO和IO之间的主要差别,我会更详细地描述表中每部分的差异. 复制代码 代码如下: IO NIO面向流 面向缓冲阻塞IO 非阻塞IO无 选择器 面向流与面向缓冲 Java NIO ...
- kubernetes第二章--集群搭建
- 四 python中关于OOP的常用术语
抽象/实现 抽象指对现实世界问题和实体的本质表现,行为和特征建模,建立一个相关的子集,可以用于 绘程序结构,从而实现这种模型.抽象不仅包括这种模型的数据属性,还定义了这些数据的接口. 对某种抽象的实现 ...
- Oracle - 实现MySQL的limit功能
MySQL的limit功能是获取指定行数的数据,Oracle没有这个limit,但是有其它方法. oracle数据库不支持mysql中limit功能,但可以通过rownum来限制返回的结果集的行数,r ...
- 根据值获取枚举类对象工具类EnumUtils
枚举类 public enum Sex { man("M","男"),woman("W","女"); private S ...
- Redis配置文件详情
# Redis 配置文件 # 当配置中需要配置内存大小时,可以使用 1k, 5GB, 4M 等类似的格式,其转换方式如下(不区分大小写) # # 1k => bytes # 1kb => ...
- java--Annotation实现
Annotation实现 在java中一共提供了三个annotation:@Override,@Deprecated,@SupperessWarnings 代码范例:使用Annotation pack ...