python网络爬虫(1)——安装scrapy框架的常见问题及其解决方法
Scrapy是为了爬取网站数据而编写的一款应用框架,出名,强大。所谓的框架其实就是一个集成了相应的功能且具有很强通用性的项目模板。
其实在Linux和 Mac安装,就简单的pip命令即可:
pip install wheel
但是在Windows上安装却有很多坑,所以下面小编讲一下自己在windows10安装及配置Scrapy中遇到的一些坑及其解决的方法,现在总结如下,希望对大家有所帮助。
包的下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/
常见问题一:pip版本需要升级
如果你的pip版本比较老,可能在安装的过程中需要更新对应的pip版本,所以最好通过指令升级一下pip
升级指令如下(这是在cmd中操作):
python -m pip install --upgrade pip
升级完成后,这一类问题就解决了。
常见问题二:安装wheel
pip install wheel
如果未安装wheel,使用该命令可以直接安装wheel,如果已经安装了,使用该命令则会显示如下图所出信息,不会重复进行安装
Requirement already satisfied: wheel in d:\python3\lib\site-packages
常见问题三:缺少lxml
顺利安装完成wheel,到这里对应的.whl文件,注意别改文件名,然后下载如下的xlml文件,我们可以在LFD中下载对应版本的lxml,如下(我的是windows 64位操作系统,python版本是3.6)
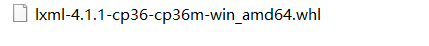
下载之后,进入cmd命令行安装好对应的whl文件:
pip install lxml-4.1.1-cp36-cp36m-win_amd64.whl
未安装的,可以直接安装,已经安装的会出现如下代码表示成功
Requirement already satisfied: lxml==4.1.1 from file:///D:/lxml-4.1.1-cp36-cp36m-win_amd64.whl in d:\python3\lib\site-packages
常见问题四:路径冲突
Error in sitecustomize; set PYTHONVERBOSE for traceback:
AttributeError: module 'sys' has no attribute 'setdefaultencoding'
因为sys.path 中多了python27的site-package冲突
到“…/local/lib/python3.6/site-packages/“目录下(目录因人而已),删除里面的路径即可
python -v homebrew.pth
常见问题五:缺少Twisted
安装Twisted,然后根据自己的电脑安装(我的是python 3.6,操作系统是64位,名称中间的cp36是python3.6的意思,amd64是python的位数)
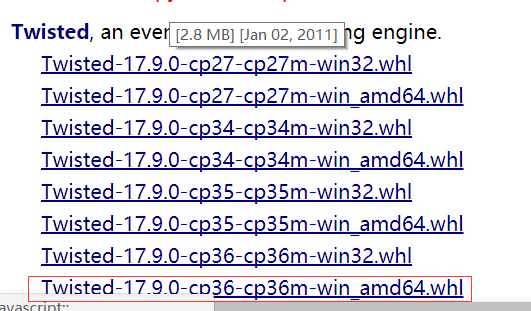
下载好后,安装命令如下:
pip install Twisted-17.9.0-cp36-cp36m-win_amd64.whl
未安装的,可以直接安装,安装的则显示成功,如下:
Successfully installed Twisted-17.9.0
常见问题六:出现UnicodeDecodeError
(由于小编已经踩过坑了,所以这些代码都是网上找到的相似代码,大体内容相似,问题一致)
Exception:
Traceback (most recent call last):
File "c:\program files\python36\lib\site-packages\pip\compat\__init__.py", line 73, in console_to_str
return s.decode(sys.__stdout__.encoding)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb6 in position 34: invalid start byte During handling of the above exception, another exception occurred: Traceback (most recent call last):
File "c:\program files\python36\lib\site-packages\pip\basecommand.py", line 215, in main
status = self.run(options, args)
File "c:\program files\python36\lib\site-packages\pip\commands\install.py", line 342, in run
prefix=options.prefix_path,
File "c:\program files\python36\lib\site-packages\pip\req\req_set.py", line 784, in install
**kwargs
File "c:\program files\python36\lib\site-packages\pip\req\req_install.py", line 878, in install
spinner=spinner,
File "c:\program files\python36\lib\site-packages\pip\utils\__init__.py", line 676, in call_subprocess
line = console_to_str(proc.stdout.readline())
File "c:\program files\python36\lib\site-packages\pip\compat\__init__.py", line 75, in console_to_str
return s.decode('utf_8')
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb6 in position 34: invalid start byte
或者下面error:
Exception:
Traceback (most recent call last):
File "c:\users\59740\appdata\local\programs\python\python36\lib\site-packages\pip\compat\__init__.py", line 73, in console_to_str
return s.decode(sys.__stdout__.encoding)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb6 in position 34: invalid start byte During handling of the above exception, another exception occurred: Traceback (most recent call last):
File "c:\users\59740\appdata\local\programs\python\python36\lib\site-packages\pip\commands\install.py", line 342, in run
prefix=options.prefix_path,
File "c:\users\59740\appdata\local\programs\python\python36\lib\site-packages\pip\req\req_set.py", line 784, in install
**kwargs
File "c:\users\59740\appdata\local\programs\python\python36\lib\site-packages\pip\req\req_install.py", line 878, in install
spinner=spinner,
File "c:\users\59740\appdata\local\programs\python\python36\lib\site-packages\pip\utils\__init__.py", line 676, in call_subprocess
line = console_to_str(proc.stdout.readline())
File "c:\users\59740\appdata\local\programs\python\python36\lib\site-packages\pip\compat\__init__.py", line 75, in console_to_str
return s.decode('utf_8')
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb6 in position 34: invalid start byte During handling of the above exception, another exception occurred: Traceback (most recent call last):
File "c:\users\59740\appdata\local\programs\python\python36\lib\site-packages\pip\commands\install.py", line 385, in run
requirement_set.cleanup_files()
File "c:\users\59740\appdata\local\programs\python\python36\lib\site-packages\pip\req\req_set.py", line 729, in cleanup_files
req.remove_temporary_source()
File "c:\users\59740\appdata\local\programs\python\python36\lib\site-packages\pip\req\req_install.py", line 977, in remove_temporary_sou
rmtree(self.source_dir)
File "c:\users\59740\appdata\local\programs\python\python36\lib\site-packages\pip\_vendor\retrying.py", line 49, in wrapped_f
return Retrying(*dargs, **dkw).call(f, *args, **kw)
File "c:\users\59740\appdata\local\programs\python\python36\lib\site-packages\pip\_vendor\retrying.py", line 212, in call
raise attempt.get()
File "c:\users\59740\appdata\local\programs\python\python36\lib\site-packages\pip\_vendor\retrying.py", line 247, in get
six.reraise(self.value[0], self.value[1], self.value[2])
File "c:\users\59740\appdata\local\programs\python\python36\lib\site-packages\pip\_vendor\six.py", line 686, in reraise
raise value
File "c:\users\59740\appdata\local\programs\python\python36\lib\site-packages\pip\_vendor\retrying.py", line 200, in call
attempt = Attempt(fn(*args, **kwargs), attempt_number, False)
File "c:\users\59740\appdata\local\programs\python\python36\lib\site-packages\pip\utils\__init__.py", line 102, in rmtree
onerror=rmtree_errorhandler)
File "c:\users\59740\appdata\local\programs\python\python36\lib\shutil.py", line 488, in rmtree
return _rmtree_unsafe(path, onerror)
File "c:\users\59740\appdata\local\programs\python\python36\lib\shutil.py", line 387, in _rmtree_unsafe
onerror(os.rmdir, path, sys.exc_info())
File "c:\users\59740\appdata\local\programs\python\python36\lib\site-packages\pip\utils\__init__.py", line 114, in rmtree_errorhandler
func(path)
PermissionError: [WinError 32] 另一个程序正在使用此文件,进程无法访问。: 'C:\\Users\\59740\\AppData\\Local\\Temp\\pip-build-1djzmudb\\scrapy' During handling of the above exception, another exception occurred: Traceback (most recent call last):
File "c:\users\59740\appdata\local\programs\python\python36\lib\site-packages\pip\basecommand.py", line 215, in main
status = self.run(options, args)
File "c:\users\59740\appdata\local\programs\python\python36\lib\site-packages\pip\commands\install.py", line 385, in run
requirement_set.cleanup_files()
File "c:\users\59740\appdata\local\programs\python\python36\lib\site-packages\pip\utils\build.py", line 38, in __exit__
self.cleanup()
File "c:\users\59740\appdata\local\programs\python\python36\lib\site-packages\pip\utils\build.py", line 42, in cleanup
rmtree(self.name)
File "c:\users\59740\appdata\local\programs\python\python36\lib\site-packages\pip\_vendor\retrying.py", line 49, in wrapped_f
return Retrying(*dargs, **dkw).call(f, *args, **kw)
File "c:\users\59740\appdata\local\programs\python\python36\lib\site-packages\pip\_vendor\retrying.py", line 212, in call
raise attempt.get()
File "c:\users\59740\appdata\local\programs\python\python36\lib\site-packages\pip\_vendor\retrying.py", line 247, in get
six.reraise(self.value[0], self.value[1], self.value[2])
File "c:\users\59740\appdata\local\programs\python\python36\lib\site-packages\pip\_vendor\six.py", line 686, in reraise
raise value
File "c:\users\59740\appdata\local\programs\python\python36\lib\site-packages\pip\_vendor\retrying.py", line 200, in call
attempt = Attempt(fn(*args, **kwargs), attempt_number, False)
File "c:\users\59740\appdata\local\programs\python\python36\lib\site-packages\pip\utils\__init__.py", line 102, in rmtree
onerror=rmtree_errorhandler)
File "c:\users\59740\appdata\local\programs\python\python36\lib\shutil.py", line 488, in rmtree
return _rmtree_unsafe(path, onerror)
File "c:\users\59740\appdata\local\programs\python\python36\lib\shutil.py", line 378, in _rmtree_unsafe
_rmtree_unsafe(fullname, onerror)
File "c:\users\59740\appdata\local\programs\python\python36\lib\shutil.py", line 387, in _rmtree_unsafe
onerror(os.rmdir, path, sys.exc_info())
File "c:\users\59740\appdata\local\programs\python\python36\lib\site-packages\pip\utils\__init__.py", line 114, in rmtree_errorhandler
func(path)
PermissionError: [WinError 32] 另一个程序正在使用此文件,进程无法访问。: 'C:\\Users\\59740\\AppData\\Local\\Temp\\pip-build-1djzmudb\\scrapy
解决方法:
打开
c:\program files\python36\lib\site-packages\pip\compat\__init__.py
找到
return s.decode('utf_8')
并将其改为
return s.decode('cp936')
这个是编码问题,虽然py3统一用utf-8了。但windows下的终端显示用的还是gbk编码。
常见问题七:缺少win32
缺少模块,会显示如下错误:
ModuleNotFoundError: No module named 'win32api'
安装win32,然后根据自己的电脑安装(我的是python 3.6,操作系统是64位,名称中间的cp36是python3.6的意思,amd64是python的位数)

安装指令如下:
pip install pywin32-221-cp36-cp36m-win_amd64.whl
最后安装scrapy
在cmd中输入如下代码
pip install scrapy
ok,终于经过折腾完成这个scrapy框架的安装,真的是经历九九八十一难。
现在总结一下安装scrapy的大致顺序:
基本一个好的anaconda环境,我们安装以下面顺序即可: 1,pip install wheel 2,下载对应版本的twisted,然后 pip install 下载好的框架.whl 3,pip install pywin32 4,pip install scrapy
复杂问题:找不到指定模组
报错如下:
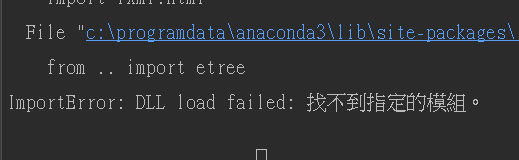
网上找了很多方法,都没有解决,很烦。
于是我将安装的东西全部卸载,依次卸载lxml,twisted,pywin32。如果运气好的话,再次安装就OK了。
如果运气不好的话,我们需要更新一个东西,那就是openssl的版本。
conda install openssl=1.0.2p
这样就OK了。
参考: https://www.cnblogs.com/little-orangeaaa/p/10259973.html
scrapy框架常见命令
查看所有命令
scrapy -h
查看帮助信息
scapy --help
查看版本信息
(venv)ql@ql:~$ scrapy version
Scrapy 1.1.2
(venv)ql@ql:~$
(venv)ql@ql:~$ scrapy version -v
Scrapy : 1.1.2
lxml : 3.6.4.0
libxml2 : 2.9.4
Twisted : 16.4.0
Python : 2.7.12 (default, Jul 1 2016, 15:12:24) - [GCC 5.4.0 20160609]
pyOpenSSL : 16.1.0 (OpenSSL 1.0.2g-fips 1 Mar 2016)
Platform : Linux-4.4.0-36-generic-x86_64-with-Ubuntu-16.04-xenial
(venv)ql@ql:~$
新建一个工程
scrapy startproject spider_name
构建爬虫genspider(generator spider)(一个工程中可以存在多个spider, 但是名字必须唯一)
scrapy genspider name domain
#如:
#scrapy genspider sohu sohu.org
查看当前项目内有多少爬虫
scrapy list
view使用浏览器打开网页
scrapy view http://www.baidu.com
shell命令, 进入scrpay交互环境
#进入该url的交互环境
scrapy shell http://www.dmoz.org/Computers/Programming/Languages/Python/Books/
之后便进入交互环境,我们主要使用这里面的response命令, 例如可以使用
response.xpath() #括号里直接加xpath路径
runspider命令用于直接运行创建的爬虫, 并不会运行整个项目
scrapy runspider 爬虫名称
python网络爬虫(1)——安装scrapy框架的常见问题及其解决方法的更多相关文章
- 安装scrapy框架的常见问题及其解决方法
下面小编讲一下自己在windows10安装及配置Scrapy中遇到的一些坑及其解决的方法,现在总结如下,希望对大家有所帮助. 常见问题一:pip版本需要升级 如果你的pip版本比较老,可能在安装的过程 ...
- PYTHON网络爬虫与信息提取[scrapy框架应用](单元十、十一)
scrapy 常用命令 startproject 创建一个新的工程 scrapy startproject <name>[dir] genspider 创建一个爬虫 ...
- 【python 网络爬虫】之scrapy系列
网络爬虫之scripy系列 [scrapy网络爬虫]之0 爬虫与反扒 [scrapy网络爬虫]之一 scrapy框架简介和基础应用 [scrapy网络爬虫]之二 持久化操作 [scrapy网络爬虫]之 ...
- 学习推荐《精通Python网络爬虫:核心技术、框架与项目实战》中文PDF+源代码
随着大数据时代的到来,我们经常需要在海量数据的互联网环境中搜集一些特定的数据并对其进行分析,我们可以使用网络爬虫对这些特定的数据进行爬取,并对一些无关的数据进行过滤,将目标数据筛选出来.对特定的数据进 ...
- 网络爬虫:使用Scrapy框架编写一个抓取书籍信息的爬虫服务
上周学习了BeautifulSoup的基础知识并用它完成了一个网络爬虫( 使用Beautiful Soup编写一个爬虫 系列随笔汇总 ), BeautifulSoup是一个非常流行的Python网 ...
- python网络爬虫之使用scrapy自动爬取多个网页
前面介绍的scrapy爬虫只能爬取单个网页.如果我们想爬取多个网页.比如网上的小说该如何如何操作呢.比如下面的这样的结构.是小说的第一篇.可以点击返回目录还是下一页 对应的网页代码: 我们再看进入后面 ...
- python网络爬虫之使用scrapy自动登录网站
前面曾经介绍过requests实现自动登录的方法.这里介绍下使用scrapy如何实现自动登录.还是以csdn网站为例. Scrapy使用FormRequest来登录并递交数据给服务器.只是带有额外的f ...
- python网络爬虫之使用scrapy下载文件
前面介绍了ImagesPipeline用于下载图片,Scrapy还提供了FilesPipeline用与文件下载.和之前的ImagesPipeline一样,FilesPipeline使用时只需要通过it ...
- python网络爬虫之使用scrapy爬取图片
在前面的章节中都介绍了scrapy如何爬取网页数据,今天介绍下如何爬取图片. 下载图片需要用到ImagesPipeline这个类,首先介绍下工作流程: 1 首先需要在一个爬虫中,获取到图片的url并存 ...
随机推荐
- Class文件和JVM的恩怨情仇
类的加载时机 现在我们例子中生成的两个.class文件都会直接被加载到JVM中吗?? 虚拟机规范则是严格规定了有且只有5种情况必须立即对类进行“初始化”(class文件加载到JVM中): 创建类的实例 ...
- Vue-cli3脚手架工具快速创建一个项目
1.首先全局安装一下vue-cli3 npm install -g @vue/cli 或 yarn global add @vue/cli vue -V查看版本(这里注意V是大写哦) 2.vue cr ...
- EM算法-完整推导
前篇已经对EM过程,举了扔硬币和高斯分布等案例来直观认识了, 目标是参数估计, 分为 E-step 和 M-step, 不断循环, 直到收敛则求出了近似的估计参数, 不多说了, 本篇不说栗子, 直接来 ...
- Python元组与字符串操作(10)——冒泡法
冒泡法 属于交换排序,元素两两比较大小,交换位置,结果可升序或降序排列 nums = [2,5,1,6,7,9,8,3,4] for i in range(len(nums)): ##计数器0~8 f ...
- Placeholder_2:0 is both fed and fetched
Placeholder_2:0 is both fed and fetched TensorFlow出现这个错误是因为网络的输入被原样输出,也就是说同一个东西既被输入网络,又被输出网络.
- 使用spring aop 记录接口日志
spring配置文件中增加启用aop的配置 <!-- 增加aop 自动代理配置 --> <aop:aspectj-autoproxy /> 切面类配置 package com. ...
- LeetCode 112. Path Sum路径总和 (C++)
题目: Given a binary tree and a sum, determine if the tree has a root-to-leaf path such that adding up ...
- JS中的箭头函数与this
转载自:https://juejin.im/post/5aa1eb056fb9a028b77a66fd#heading-1 JavaScript在ES6语法中新增了箭头函数,相较于传统函数,箭头函数不 ...
- vmware centos 桥接模式 联网记录
参考这篇文章 https://www.cnblogs.com/jasmine-Jobs/p/5928218.html 记得要修改/etc/sysconfig/network文件的网关配置,因为ip变动 ...
- css样式添加错误导致烦扰
省厅和市州 两个ul 之间切换 分别能显示两者对应的内容 但是在做过程中,出现省厅界面有市州的内容… 找了半天,发现是css的问题 layui-show的多添加 算是把首页内容的任务解决了至于c ...