HDFS入门
HDFS入门
欢迎关注我的个人博客:http://www.cnblogs.com/yjd_hycf_space 更多大数据以及编程相关的精彩文章
为什么我们需要HDFS
文件系统由三部分组成:与文件管理有关软件、被管理文件以及实施文件管理所需数据结构。

既然读取一块磁盘的所有数据需要很长时间,写入更是需要更长时间(写入时间一般是读取时间的3倍)。我们需要一个巨大文件难道得换传输速度10GB/S的磁盘(现在没有这样的磁盘),而且即使有文件为1ZB,或者小点10EB时,这样的磁盘也无法做到随读随取。

当数据集的大小超过一台独立物理计算机的存储能力时,就有必要对它进行分区并存储到若干台单独的计算机上。
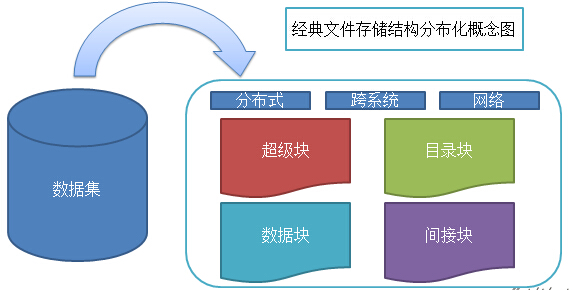
从概念图上看,分布化的文件系统会因为分布后的结构不完整,导致系统复杂度加大,并且引入的网络编程,同样导致分布式文件系统更加复杂。
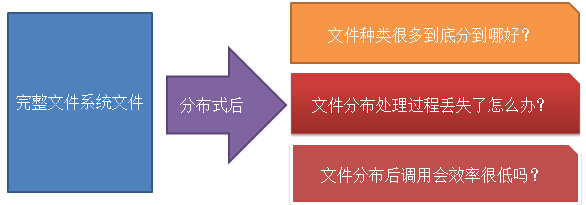
对于以上的问题我们来HDFS是如何迎刃而解的?

HDFS以流处理访问模式来存储文件的。
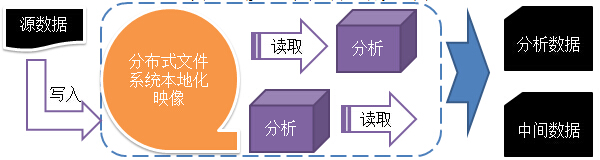
一次写入,多次读取。数据源通常由源生成或从数据源直接复制而来,接着长时间在此数据集上进行各类分析,大数据不需要搬来搬去。
DFS是用流处理方式处理文件,每个文件在系统里都能找到它的本地化映像,所以对于用户来说,别管文件是什么格式的,也不用在意被分到哪里,只管从DFS里取出就可以了。

一般来说,文件处理过程中无法保证文件安全顺利到达,传统文件系统是使用本地校验方式保证数据完整,文件被散后,难道需要特意安排每个分片文件的校验码?
分片数量和大小是不确定的,海量的数据本来就需要海量的校验过程,分片后加入每个分片的跟踪校验完全是在数满天恒星的同时数了他们的行星。×
HDFS的解决方案是分片冗余,本地校验。
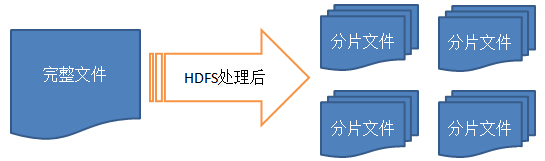
数据冗余式存储,直接将多份的分片文件交给分片后的存储服务器去校验

冗余后的分片文件还有个额外功能,只要冗余的分片文件中有一份是完整的,经过多次协同调整后,其他分片文件也将完整。

经过协调校验,无论是传输错误,I/O错误,还是个别服务器宕机,整个系统里的文件是完整的
分布后的文件系统有个无法回避的问题,因为文件不在一个磁盘导致读取访问操作的延时,这个是HDFS现在遇到的主要问题。
现阶段,HDFS的配置是按照高数据吞吐量优化的,可能会以高时间延时为代价。但万幸的是,HDFS是具有很高弹性,可以针对具体应用再优化。
HDFS的概念
HDFS可以用下面这个抽象图的具体实现
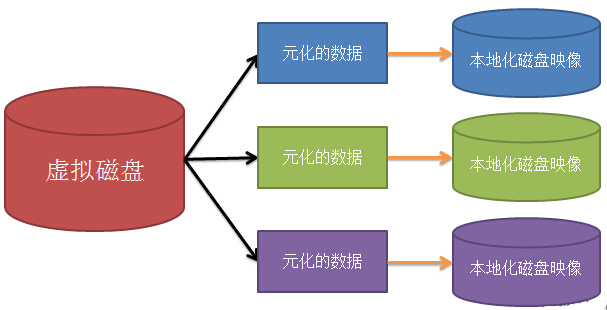
何为元数据?
元数据是用于描述要素、数据集或数据集系列的内容、覆盖范围、质量、管理方式、数据的所有者、数据的提供方式等有关的信息。更简单的说,是关于数据的数据。
HDFS就是将巨大的数据变成大量数据的数据。
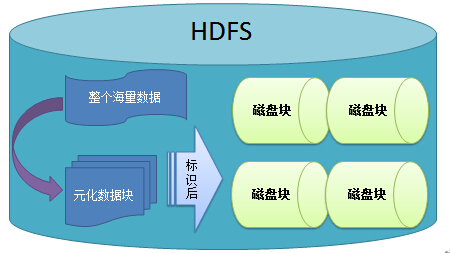
PS: 磁盘存储文件时,是按照数据块来存储的,也就是说,数据块是磁盘的读/写最小单位。数据块也称磁盘块。构建于单个磁盘上的文件系统是通过磁盘块来管理文件系统,一般来说,文件系统块的大小是磁盘块的整数倍。特别的,单个磁盘文件系统,小于磁盘块的文件会占用整个磁盘块。磁盘块的大小一般是512字节。
在HDFS中,也有块(block)这个概念,默认为64MB,每个块作为独立的存储单元。
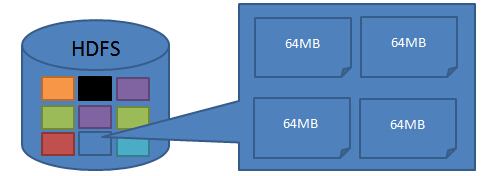
与其他文件系统不一样,HDFS中每个小于块大小的文件不会占据整个块的空间。具体原因在后面的介绍。下面介绍为什么是64MB一个文件块
在文件系统中,系统存储文件时,需要定位该数据在磁盘中的位置,再进行传输处理。
定位在磁盘的位置是需要时间的,同样文件传输也是需要时间。
T(存储时间)=T(定位时间)+T(传输时间)
如果每个要传输的块设置得足够大,那么从磁盘传输数据的时间可以明显大于定位这个块开始位置的时间
T(存储时间)=T(定位时间) )[-∞]+T(传输时间)[∞]
近似等于:T(存储时间)=T(传输时间)
举个例子:我们来传输一个10000MB的文件
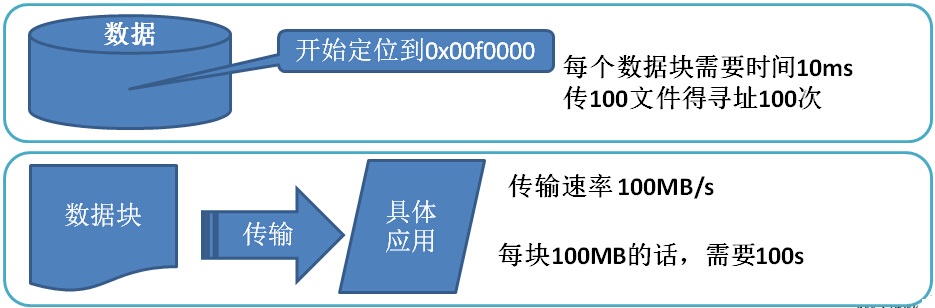
单个磁盘下:
存储1个10000MB的文件我们需要时间是
10msX100+1000msX100=101s


10台数据节点: 传输10000MB的文件所花的时间:10msX10+10ms+10s=10.11s
此例子是理论数据,实际比这个稍长。
总结:
这样的设定使存储一个文件主要时间就花在传输过程中,块大小决定传输由多个快组成文件的存储速率,这也是HSDF的核心技术。
当然不是设置每个块越大越好。
HDFS提供给MapReduce数据服务,而一般来说MapReduce的Map任务通常一次处理一个块中的数据,如果任务数太少(少于集群中节点的数量),就没有发挥多节点的优势,甚至作业的运行速度就会和单节点一样。
分布式的文件抽象能够带来的优势是:
1、一个文件可以大于每个磁盘
2、文件不用全在一个磁盘上。
3、简化了存储子系统的设计。
不仅如此,基于元数据块的存储方式非常适合用于备份,利用备份可提供数据容错能力和可用性。
HDFS的关键运作机制
HDFS是基于主从结构(master/slaver)构件。

如何使用HDFS

常用HDFS shell命令:http://www.cnblogs.com/yjd_hycf_space/p/6735371.html
HDFS入门的更多相关文章
- 【Hadoop离线基础总结】HDFS入门介绍
HDFS入门介绍 概述 HDFS全称为Hadoop Distribute File System,也就是Hadoop分布式文件系统,是Hadoop的核心组件之一. 分布式文件系统是横跨在多台计算机上的 ...
- 《OD大数据实战》HDFS入门实例
一.环境搭建 1. 下载安装配置 <OD大数据实战>Hadoop伪分布式环境搭建 2. Hadoop配置信息 1)${HADOOP_HOME}/libexec:存储hadoop的默认环境 ...
- HDFS入门详解
一. 前提和设计目标 1. 硬件错误是常态,因此需要冗余,这是深入到HDFS骨头里面去了 HDFS可能由成百上千的服务器所构成,每个服务器上存储着文件系统的部分数据.我们面对的现实是构成系统的组件数目 ...
- HDFS入门(1)
2015.07.12笔记 1.HDFS Distributed File System(操作系统实现人机交互,最重要的功能是文件管理,使用文件管理系统,windows.Linux文件管理系统有共性:用 ...
- HDFS 入门介绍
HDFS简介 HDFS(Hadoop Distributed File System,Hadoop分布式文件系统),它是一个高度容错性的系统,适合部署在廉价的机器上.HDFS能提供高吞吐量的数据访问, ...
- Hadoop之HDFS(一)HDFS入门及基本Shell命令操作
1 . HDFS 基本概念 1.1 HDFS 介绍 HDFS 是 Hadoop Distribute File System 的简称,意为:Hadoop 分布式文件系统.是 Hadoop 核心组件之 ...
- 大数据学习(02)——HDFS入门
Hadoop模块 提到大数据,Hadoop是一个绕不开的话题,我们来看看Hadoop本身包含哪些模块. Common是基础模块,这个是必须用的.剩下常用的就是HDFS和YARN. MapReduce现 ...
- HDFS基础1
一.HDFS入门 二.HDFS基本操作 1.shell命令行客户端 Hadoop提供了文件系统的shell命令行客户端,使用方法如下: Hadoop fs <args>(参数哪一个文件系统 ...
- Hadoop_HDFS_02
1. HDFS入门 1.1 HDFS基本概念 HDFS是Hadoop Distribute File System的简称, 意为: Hadoop分布式文件系统. 是Hadoop三大核心组件之一, 作为 ...
随机推荐
- HDUOJ-----1541 Stars
Stars Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total Subm ...
- HDUOJ--------(1198)Farm Irrigation
Farm Irrigation Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) ...
- iOS开发之多媒体播放
iOS开发之多媒体播放 iOS sdk中提供了很多方便的方法来播放多媒体.本文将利用这些SDK做一个demo,来讲述一下如何使用它们来播放音频文件. AudioToolbox framework 使用 ...
- if语句的数据驱动优化(Java版)
举个栗子,如果我要输出数字对应的中文描述,我可以用这种方法来写: int num=2; if (num==1){ System.out.println("一"); } else i ...
- Python3 列表 copy() 方法
描述 Python3 列表 copy() 方法用于复制(浅拷贝)列表(父不变,子变),类似于 a[:]. 语法 copy() 方法语法: L.copy() 参数 无. 返回值 返回复制(浅拷贝)后的新 ...
- BZOJ 2466 中山市选2009 树 高斯消元+暴力
题目大意:树上拉灯游戏 高斯消元解异或方程组,对于全部的自由元暴力2^n枚举状态,代入计算 这做法真是一点也不优雅... #include <cstdio> #include <cs ...
- java日志-纯Java配置使用slf4j配置log4j(转)
工程目录如下 代码里面用的是slf4j,但是想要用log4j来管理日志,就得添加slf4j本来的jar,然后添加log4j和slf4j箱关联的jar即可. 如果是maven项目的话添加下面的依赖即可 ...
- selenium grid2 使用远程机器的浏览器
下载 selenium-server-standalone-3.4.0.jar包 在selenium-server-standalone-3.4.0.jar包目录下面执行cmd 命令 java -ja ...
- html中一些常用标签及属性
html中标签分为块级标签和行级标签 块级标签常用的有 <div> <p> <h1><hr><pre><table><ul ...
- django中templates阅读笔记
一.基本知识 1.模版是独立于django的,可以独立运行. 模版变量是用两个大括号括起来的字符串,表示变量.例如{{ person_name }} 模版标签,是用一对大括号和一对百分号括起来的,例如 ...