Spark的基本原理
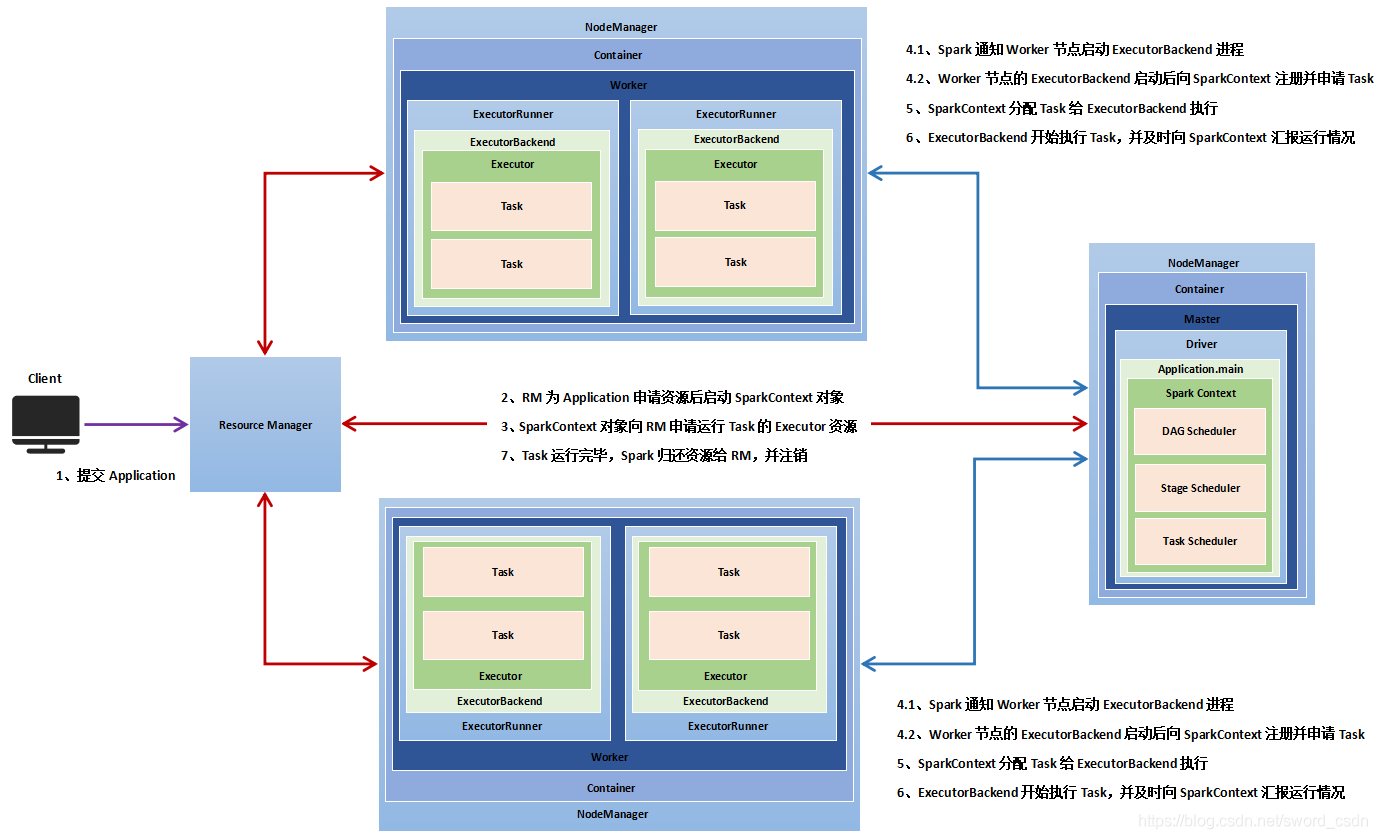
Application
Application是在使用spark-submit 提交的打包程序,也就是需要写的代码。
完整的Application一般包含以下步骤:
(1)获取数据
(2)计算逻辑
(3)输出结果(可以是存入HDFS,或者是其他存储介质)
Executor
Executor是一个Application运行在Worker节点上的一种进程,一个worker可以有多个Executor,一个Executor进程有且仅有一个executor对象。executor对象负责将Task包装成taskRunner,并从线程池抽取出一个空闲线程运行Task。每个进程能并行运行Task的个数就取决于分配给它的CPU core的数量。
Worker
Spark集群中可以用来运行Application的节点,在standalone模式下指的是slaves文件配置的worker节点,在spark on yarn模式下是NodeManager节点。
Task
在Excutor进程中执行任务的单元,执行相同代码段的多个Task组成一个Stage。
Job
由一个Action算子触发的一个调度。
Stage
Spark根据提交的作业代码划分出多个Stages,每个Stage有多个Tasks,这些Tasks负责并行处理他们所属的stage里面的代码。
DAGScheduler
根据Stage划分原则构建的DAG(有向无环图,理解为执行流程还行),并将Stage提交给Taskscheduler。
TaskScheduler
TaskScheduler将TaskSet提交给Worker运行。
RDD
弹性分布式数据集。
Resilient Distributed Dataset,是Spark中最基本的数据抽象,它代表一个不可变、可分区、元素可并行计算的集合。简单点说,从数据文件中获取到的数据会被放到RDD中。
它具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。它允许在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
RDD的属性
(1)一组分片(Partition),即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。
(2)一个计算每个分区的函数。Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。
(3)RDD之间的依赖关系。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
(4)一个Partitioner,即RDD的分片函数。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
(5)一个列表,存储存取每个Partition的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
————————————————
原文链接:https://blog.csdn.net/sword_csdn/article/details/103101878
Spark的基本原理的更多相关文章
- Spark SQL概念学习系列之Spark SQL基本原理
Spark SQL基本原理 1.Spark SQL模块划分 2.Spark SQL架构--catalyst设计图 3.Spark SQL运行架构 4.Hive兼容性 1.Spark SQL模块划分 S ...
- Spark SQL 基本原理
Spark SQL 模块划分 Spark SQL架构--catalyst设计图 Spark SQL 运行架构 Hive的兼容性
- Spark学习资料共享
链接相关 课件代码:http://pan.baidu.com/s/1nvbkRSt 教学视频:http://pan.baidu.com/s/1c12XsIG 这是最近买的付费教程,对资料感兴趣的可以在 ...
- 大数据开发实战:Spark Streaming流计算开发
1.背景介绍 Storm以及离线数据平台的MapReduce和Hive构成了Hadoop生态对实时和离线数据处理的一套完整处理解决方案.除了此套解决方案之外,还有一种非常流行的而且完整的离线和 实时数 ...
- 小白学习Spark系列三:RDD常用方法总结
上一节简单介绍了Spark的基本原理以及如何调用spark进行打包一个独立应用,那么这节我们来学习下在spark中如何编程,同样先抛出以下几个问题. Spark支持的数据集,如何理解? Spark编程 ...
- Spark SQL概念学习系列之Spark SQL概述
很多人一个误区,Spark SQL重点不是在SQL啊,而是在结构化数据处理! Spark SQL结构化数据处理 概要: 01 Spark SQL概述 02 Spark SQL基本原理 03 Spark ...
- 成功入职ByteDance,分享我的八面面经心得!
今天正式入职了字节跳动.办公环境也很好,这边一栋楼都是办公区域.公司内部配备各种小零食.饮料,还有免费的咖啡.15楼还有健身房.而且公司包三餐来着.下午三点半左右还会有阿姨推着小车给大家送下午茶.听说 ...
- spark第一篇--简介,应用场景和基本原理
摘要: spark的优势:(1)图计算,迭代计算(2)交互式查询计算 spark特点:(1)分布式并行计算框架(2)内存计算,不仅数据加载到内存,中间结果也存储内存 为了满足挖掘分析与交互式实时查询的 ...
- spark第二篇--基本原理
==是什么 == 目标Scope(解决什么问题) 在大规模的特定数据集上的迭代运算或重复查询检索 官方定义 aMapReduce-like cluster computing framework de ...
- Spark 准备篇-基本原理
本章内容: 待整理 参考文献: <深入理解SPARK:核心思想与源码分析>(第2章) Spark的作业提交及运行流程的异同
随机推荐
- java: -source 1.5 中不支持 diamond 运算符
1.问题说明 平常在用idea编译spring boot多模块项目时,老是无端提示: Error:(107, 55) java: -source 1.5 中不支持 diamond 运算符 (请使用 - ...
- OpenAI 的视频生成大模型Sora的核心技术详解(一):Diffusion模型原理和代码详解
标题党一下,顺便蹭一下 OpenAI Sora大模型的热点,主要也是回顾一下扩散模型的原理. 1. 简单理解扩散模型 简单理解,扩散模型如下图所示可以分成两部分,一个是 forward,另一个是 re ...
- win32 - 监视网络流量
可以从Windows Sockets 2开始, 虽然微软提供了官方工具, Microsoft Network Monitor 3.4, 不过我们如果能够通过相关的代码和api的调用来深入研究的话,那就 ...
- Python 潮流周刊第 39 期(摘要)
本周刊由 Python猫 出品,精心筛选国内外的 250+ 信息源,为你挑选最值得分享的文章.教程.开源项目.软件工具.播客和视频.热门话题等内容.愿景:帮助所有读者精进 Python 技术,并增长职 ...
- beego中数据库表创建
package main import ( "fmt" "github.com/astaxie/beego/orm" _ "github.com/go ...
- 终端SSH远程连接CentOS报错:-bash: warning: setlocale: LC_CTYPE: cannot change locale (UTF-8): No such file or directory
终端SSH远程连接CentOS时,报以下错误提示: -bash: warning: setlocale: LC_CTYPE: cannot change locale (UTF-8): No such ...
- C++11新特性的一些用法举例②
/** C++11 * 默认成员函数 原来C++类中,有6个默认成员函数: 构造函数 析构函数 拷贝构造函数 拷贝赋值重载 取地址重载 const 取地址重载 最后重要的是前4个,后两个用处不大.默认 ...
- IDA sp-analysis failed
目录 概述 问题描述 排查过程 概述 学习任何一个技术,都是会遇到各种问题的,那么现在就有 sp-analysis failed 问题描述 IDA在载入文件之后,出现如下注释 但是可以正常F5,不过只 ...
- C++ //类模板成员函数类外实现
1 #include <iostream> 2 #include <string> 3 #include<fstream> 4 using namespace st ...
- jQuery 框架
jQuery 框架 目录 jQuery 框架 一. 概述 二. jQuery 安装引用 2.1 安装 2.2 本地导入使用 2.3 jQuery CDN引入 三. jQuery基本语法 四. 查找标签 ...