2024盘古石取证比赛(IPA+人工智能)
前言
题目列表
IPA部分
1. 分析毛雪柳的手机检材,记账 APP 存储记账信息的数据库文件名称是: [ 答案格式:tmp.db ,区分大小写 ][ ★★★★☆ ]
通过icost软件可以定位raealm数据库
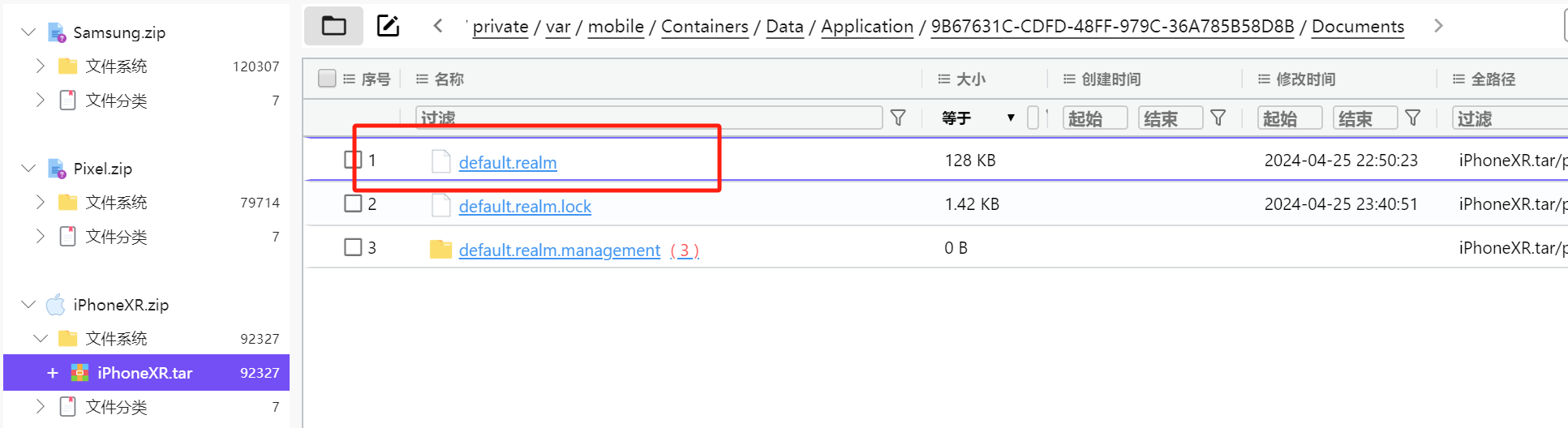
default.realm
2. 分析毛雪柳的手机检材,记账APP中,2月份总收入金额是多少:[答案格式:1234][★★★★★]
下载realm studio打开数据库
https://github.com/realm/realm-studio?tab=readme-ov-file
使用Realm Studio查看,过滤器:type=1 and timestamp >= 1706716800000 and timestamp <= 1709222400000(含义:类型为收入+2~3月)
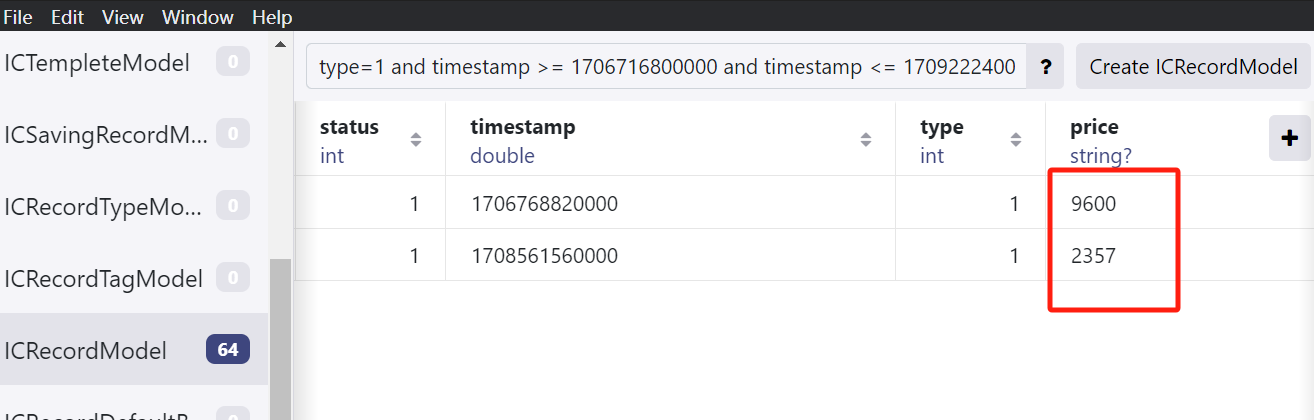
11957
3. 分析毛雪柳的手机检材,手机中团队内部使用的即时通讯软件中,团队老板的邮箱账号是:[答案格式:abc@abc.com][★★★☆☆]
服务器顺下来就知道,也不用看数据库
gxyt@163.com
4. 接上题,该内部即时通讯软件中,毛雪柳和老板的私聊频道中,老板加入私聊频道的时间是:[答案格式:2024-01-01-04-05-06][★★★☆☆]
知道通讯软件是mattermost,之前有导出过数据库
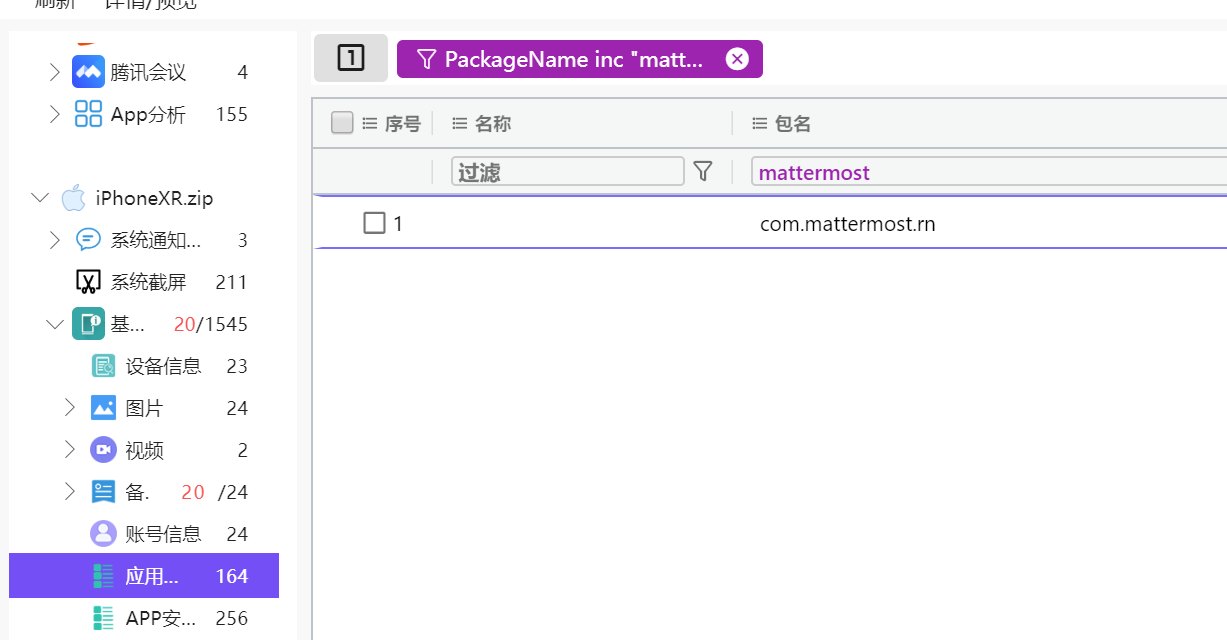
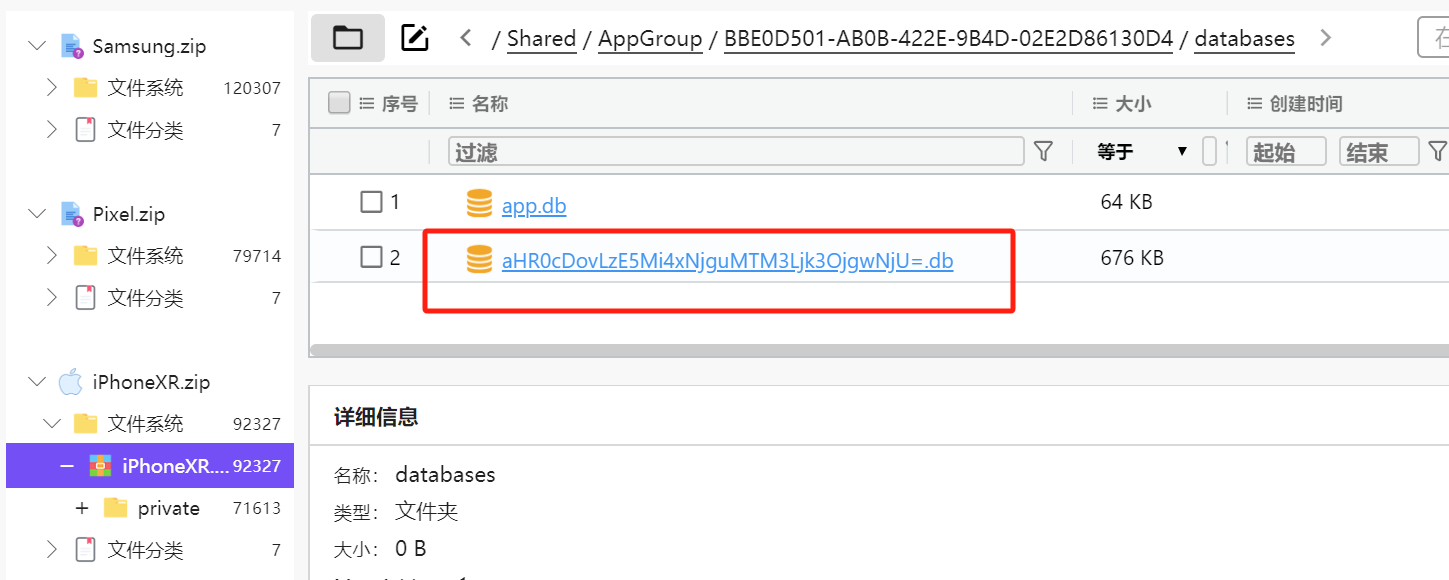

ctool转换
https://ctool.dev/tool.html#/tool/time/timestamp
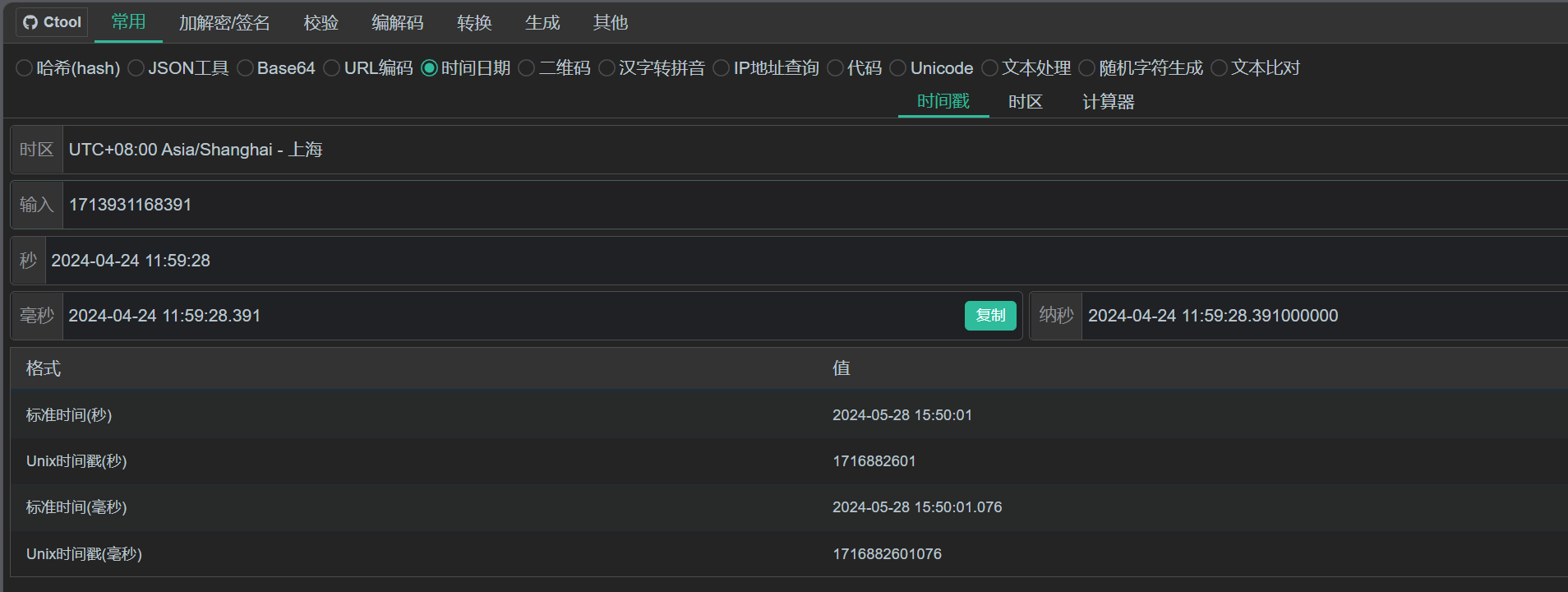
2024-04-24-11-59-28
5. 接上题,该私聊频道中,老板最后一次发送聊天内容的时间是:[答案格式:2024-01-01-04-05-06][★★★☆☆]

2024-04-25-10-24-50
人工智能部分
1. 分析义言的计算机检材,一共训练了多少个声音模型:[答案格式:123][★★☆☆☆]
火眼分析yiyan计算机发现有4个GPT声音模型
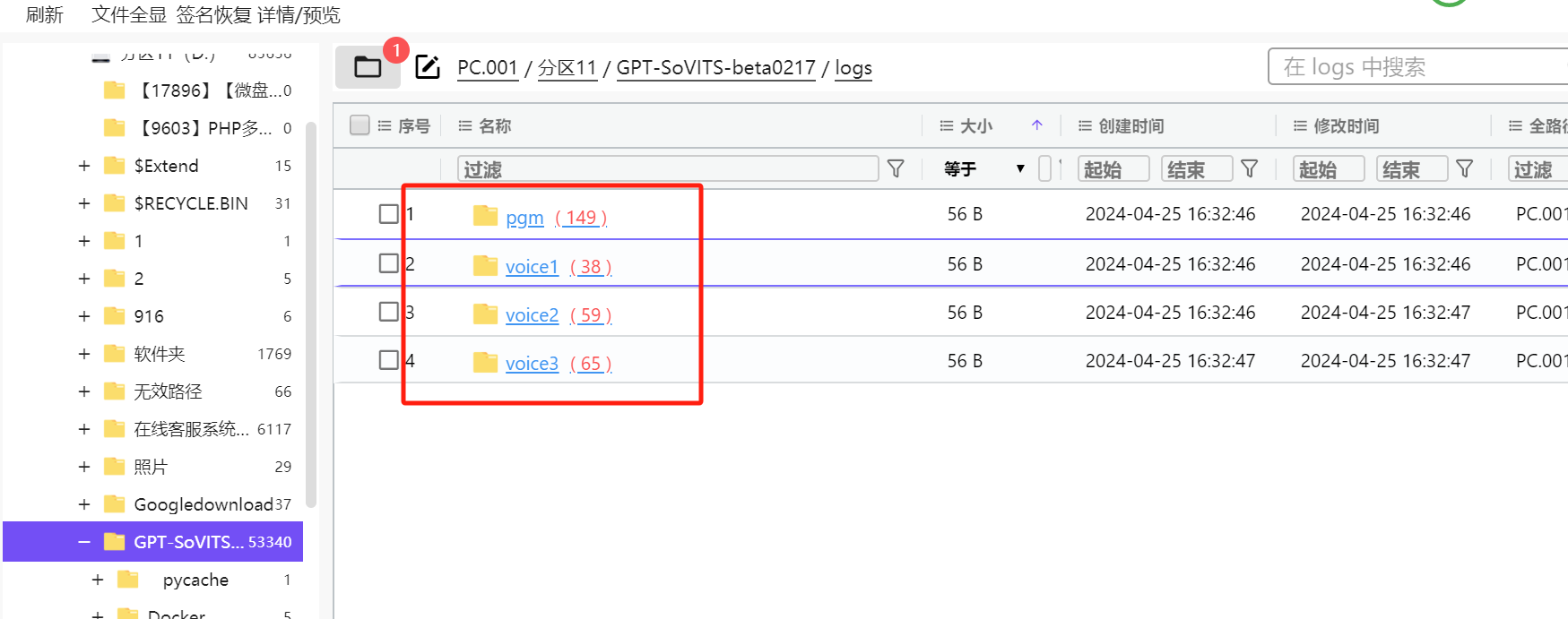
每一个模型都有一个train.log
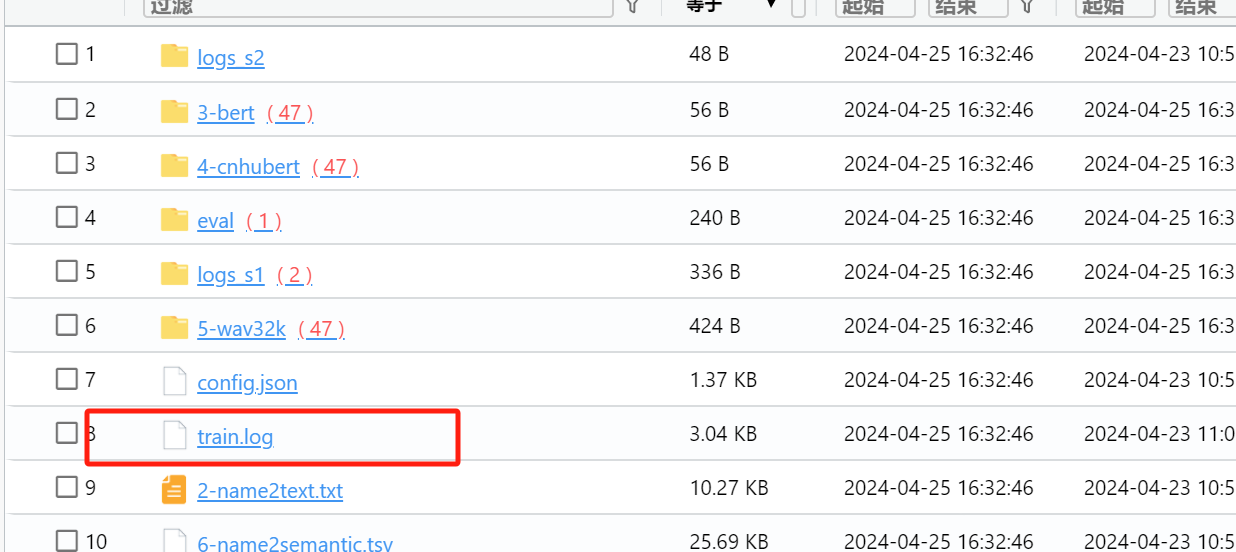
进入虚拟机也可以看到对应文件
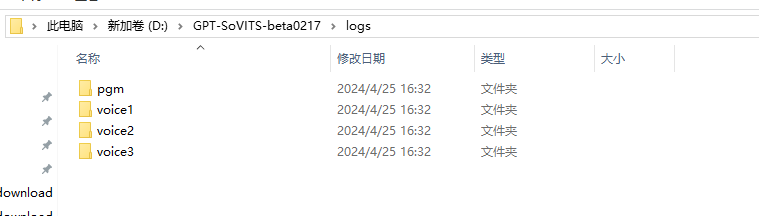
4
2. 分析义言的计算机检材,声音模型voice2,一共训练了多少条声音素材:[答案格式:123][★★☆☆☆]
文件路径:PC.001/分区11/GPT-SoVITS-beta0217/logs/voice2/3-bert
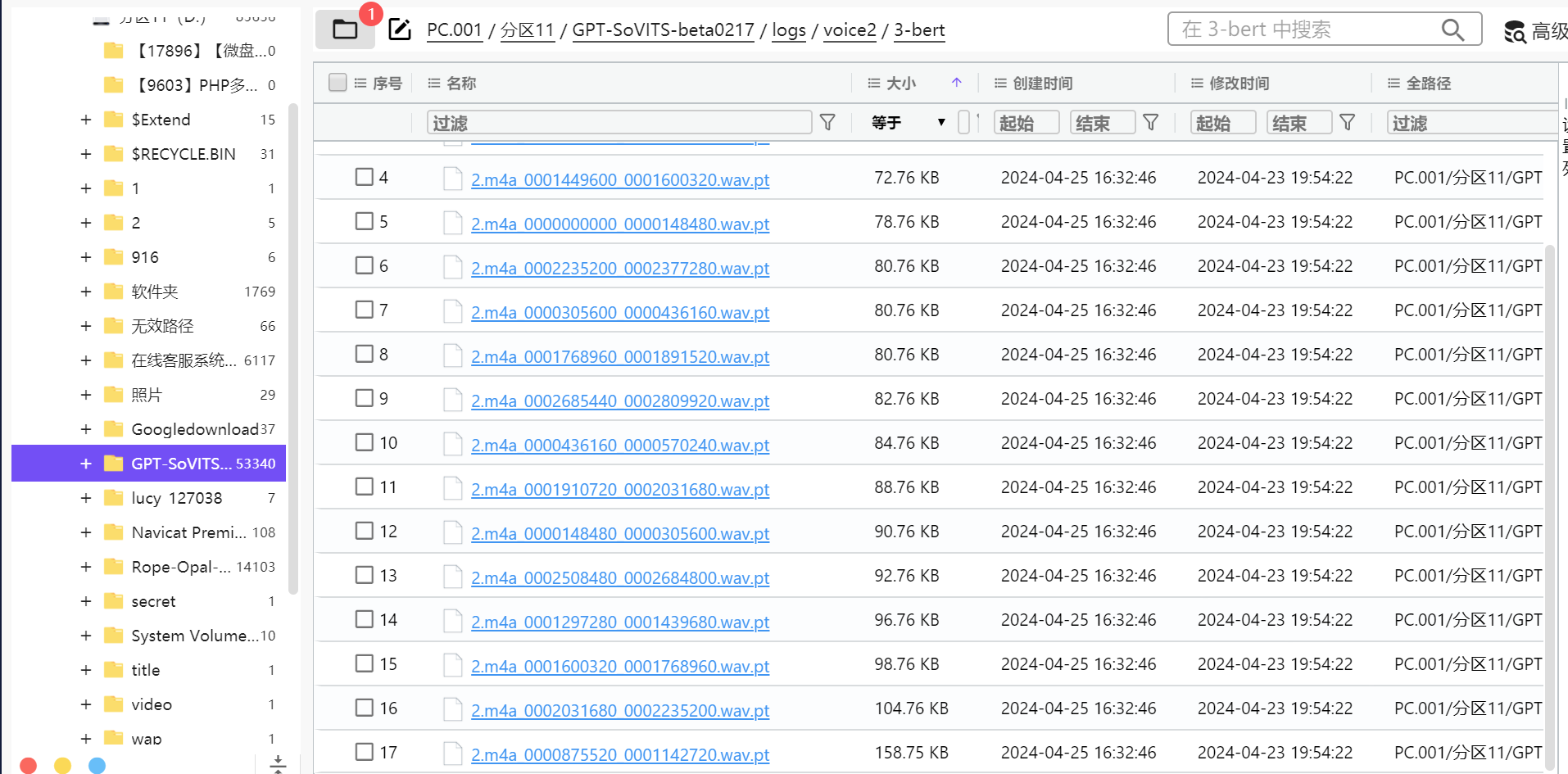
17
3. 分析义言的计算机检材,声音模型voice3,一共训练了多少轮:[答案格式:123][★★★☆☆]
查看train.log
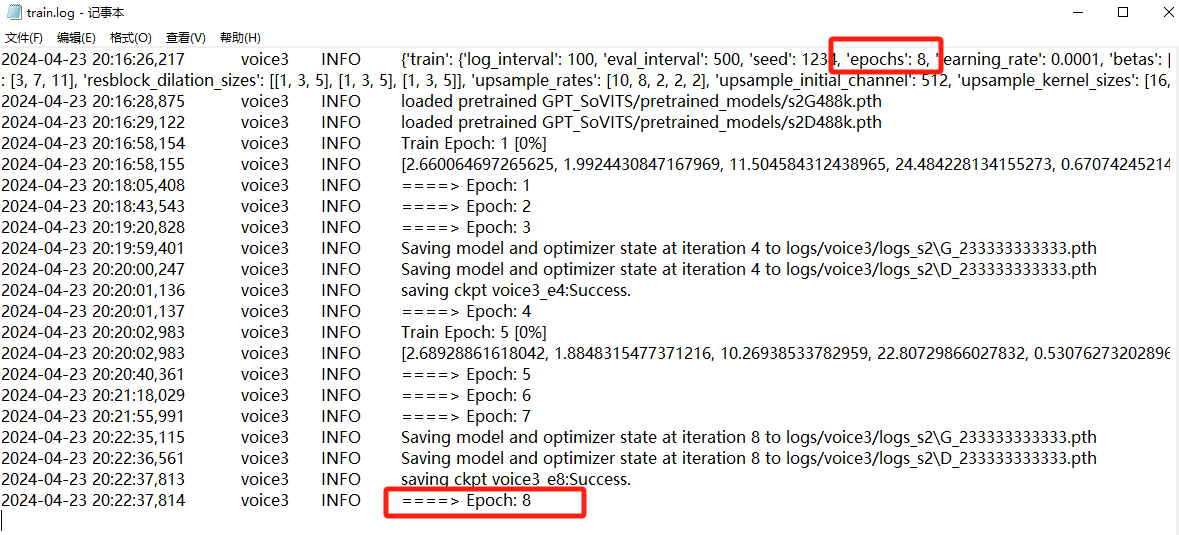
8
4. 分析义言的计算机检材,声音克隆工具推理生成语音界面的监听端口是:[答案格式:1234][★★★★☆]
查找GPT-SoVITS-beta0217的配置文件
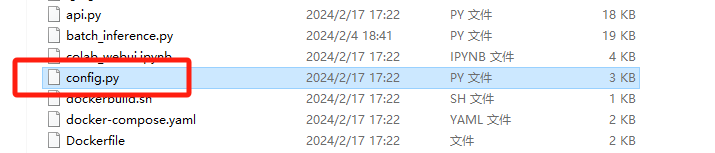

9874
5. 分析义言的计算机检材,电脑中视频文件有几个被换过脸:[答案格式:10][★★★★★]
非常有意思,这题又遇到逆向了(上次是bitlocker)
1.在输出文件里只能看到一个视频被换过脸
2.另外的视频通过wncrypt.exe加密过,要对该软件进行反编译和反混淆,了解具体加密算法后,自行编写脚本对加密文件解密
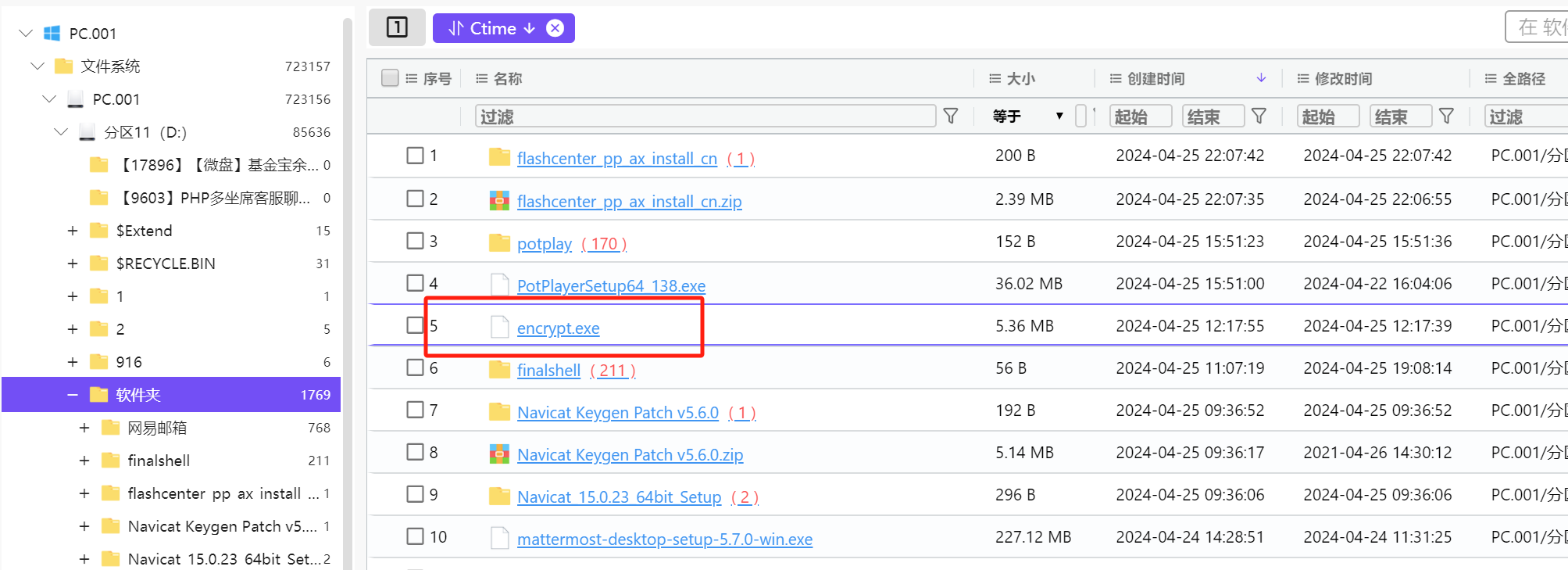
导出文件,用pyinstxtractor进行反编译,获得encrypt.exe_extracted文件夹
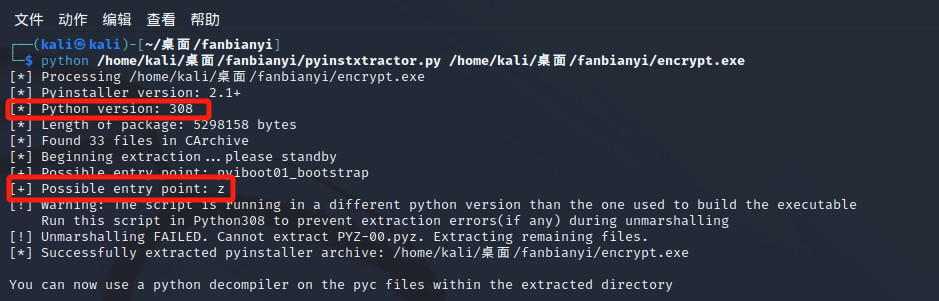
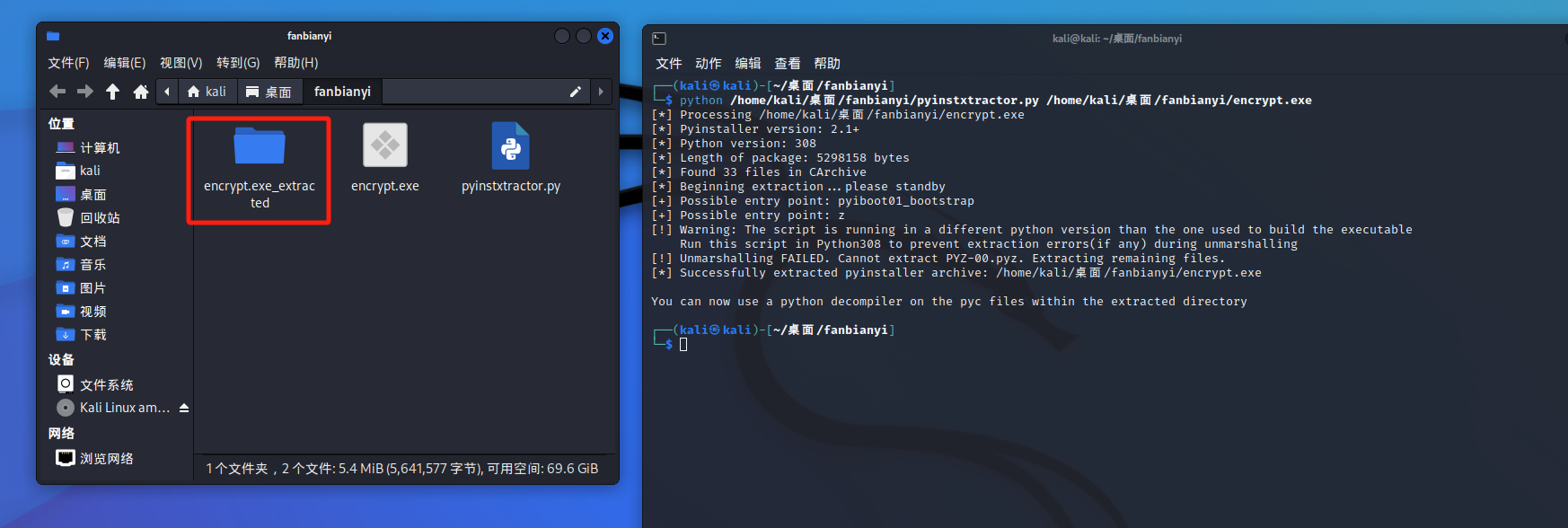
对应加密方式在z.pyc文件里,要转化为py文件。但是文件改名为z.pyc后有点问题,不能直接转换,要用WinHex修改文件头后,再放入在线网站(https://www.lddgo.net/string/pyc-compile-decompile) 或者工具(uncompyle6/pycdc)反编译
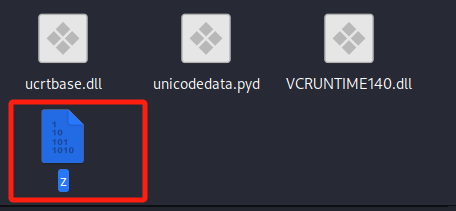
可以看到文件头有缺失,进行python版本补全
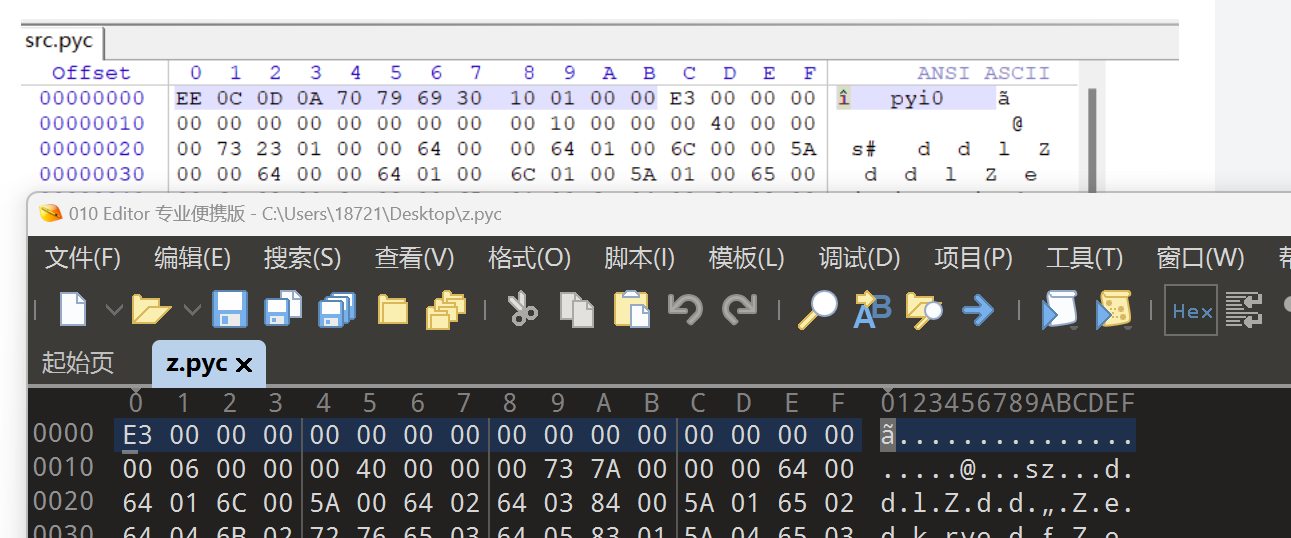
找到对应版本后转字节,再放入文件头中
转文件头代码
MAGIC_NUMBER = (3413).to_bytes(2, 'little') + b'\r\n'
_RAW_MAGIC_NUMBER = int.from_bytes(MAGIC_NUMBER, 'little') # For import.c
反编译结果
反编译后的代码
# -*- coding: utf8 -*-
#! /usr/bin/env 3.8.0 (3413)
#coding=utf-8
#source path: z.py
#Compiled at: 1970-01-01 00:00:00
#Powered by BugScaner
#http://tools.bugscaner.com/
#如果觉得不错,请分享给你朋友使用吧!
import os
def xor_process(O0OOO0O0000O000O0, O0OOOOO0OOOO00000):
try:
with open(O0OOO0O0000O000O0, 'rb') as (O0000O0O0000O000O):
O0O0OOO0OOO00OOOO = O0000O0O0000O000O.read()
O00000O00OOOO0O00 = os.path.splitext(os.path.basename(O0OOO0O0000O000O0))[0]
O0000O0OOO00OO000 = bytearray()
for OOO0O0000OOOO0O0O in range(len(O0O0OOO0OOO00OOOO)):
O0000O0OOO00OO000.append(O0O0OOO0OOO00OOOO[OOO0O0000OOOO0O0O] ^ ord(O00000O00OOOO0O00[OOO0O0000OOOO0O0O % len(O00000O00OOOO0O00)]))
else:
O00000O00OO0OOO0O = os.path.join(O0OOOOO0OOOO00000, f"{O00000O00OOOO0O00}-cn{os.path.splitext(O0OOO0O0000O000O0)[1]}")
with open(O00000O00OO0OOO0O, 'wb') as (OO00000O000O00OO0):
OO00000O000O00OO0.write(O0000O0OOO00OO000)
print(f"文件 {O0OOO0O0000O000O0} 处理成功!")
except Exception as OOO0000OOO0O0O0O0:
try:
print(f"处理文件 {O0OOO0O0000O000O0} 出错:{OOO0000OOO0O0O0O0}")
finally:
OOO0000OOO0O0O0O0 = None
del OOO0000OOO0O0O0O0
if __name__ == '__main__':
folder_path = input('请输入要处理的文件夹路径:')
output_folder = input('请输入要保存处理结果的文件夹路径:')
if not os.path.exists(output_folder):
os.makedirs(output_folder)
for root, _, files in os.walk(folder_path):
for file in files:
file_path = os.path.join(root, file)
xor_process(file_path, output_folder)
把混淆的代码简单处理一下,xor加密
反混淆代码
def xor_process(file_path, output_folder):
try:
with open(file_path, 'rb') as (fr):
file_data = fr.read()
file_name = os.path.splitext(os.path.basename(file_path))[0]
#file_name = file_name.replace('-cn','')
xor_data = bytearray()
for i in range(len(file_data)):
xor_data.append(file_data[i] ^ ord(file_name[i % len(file_name)]))
else:
output_file = os.path.join(output_folder, f"{file_name}-cn{os.path.splitext(file_path)[1]}")
with open(output_file, 'wb') as (fw):
fw.write(xor_data)
print(f"文件 {file_path} 处理成功!")
except Exception as e:
try:
print(f"处理文件 {file_path} 出错:{e}")
finally:
e = None
del e
然后解密之后就有对应的解密版本了仿真进去 把里面的解密一下
对应解密代码
import os
def xor_decrypt(file_path, output_folder):
try:
# 读取加密文件内容
with open(file_path, 'rb') as file:
encrypted_data = file.read()
# 从文件名中移除 '-cn' 并作为解密密钥
filename = os.path.splitext(os.path.basename(file_path))[0].replace('-cn', '')
# 初始化解密数据缓存
decrypted_data = bytearray()
# 对数据进行逐字节解密
for index in range(len(encrypted_data)):
decrypted_data.append(encrypted_data[index] ^ ord(filename[index % len(filename)]))
# 构建解密后文件的输出路径
output_file_path = os.path.join(output_folder, f"{filename}{os.path.splitext(file_path)[1]}")
# 写入解密数据到新文件
with open(output_file_path, 'wb') as output_file:
output_file.write(decrypted_data)
print(f"文件 {file_path} 解密成功!")
except Exception as e:
print(f"处理文件 {file_path} 出错:{e}")
if __name__ == '__main__':
# 获取用户输入
folder_path = input('请输入要解密的文件夹路径:')
output_folder = input('请输入要保存解密结果的文件夹路径:')
# 确保输出文件夹存在
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 遍历文件夹并解密文件
for root, _, files in os.walk(folder_path):
for file in files:
file_path = os.path.join(root, file)
xor_decrypt(file_path, output_folder)
参考文章
https://blog.csdn.net/m0_73393932/article/details/130161331
https://blog.csdn.net/Zheng__Huang/article/details/112380221
https://blog.csdn.net/qq_63585949/article/details/126706526
pyinstxtractor下载
https://sourceforge.net/projects/pyinstallerextractor/
最后发现一共 1 + 41 个换脸后的视频.
42
6. 分析义言的计算机检材,换脸AI程序默认换脸视频文件名是:[答案格式:test.mp4][★★☆☆☆]
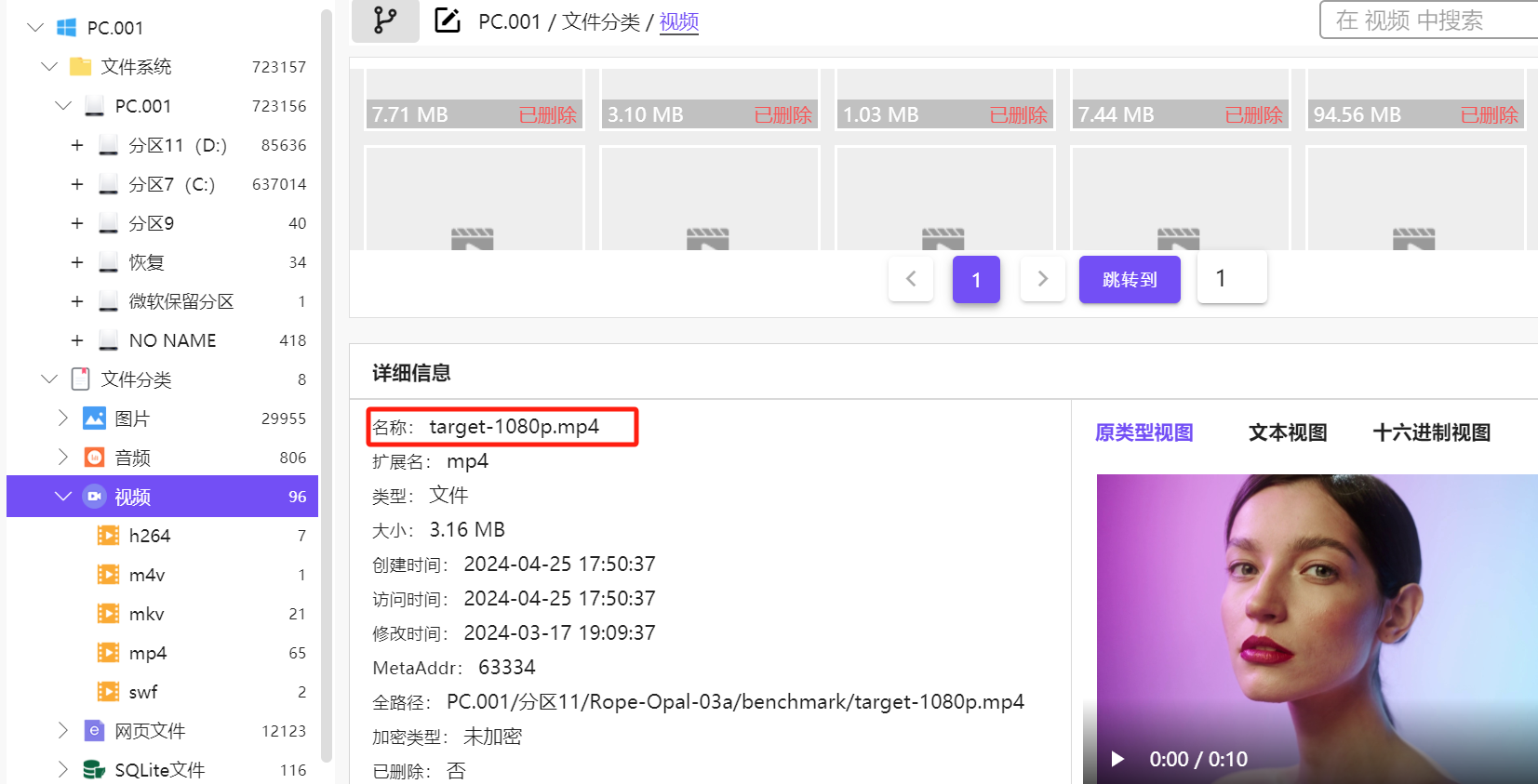
target-1080p.mp4
7. 分析义言的计算机检材,换脸AI程序默认换脸图片的文件名称:[答案格式:abc.abc][★★☆☆☆]
根据视频路径去虚拟机里找
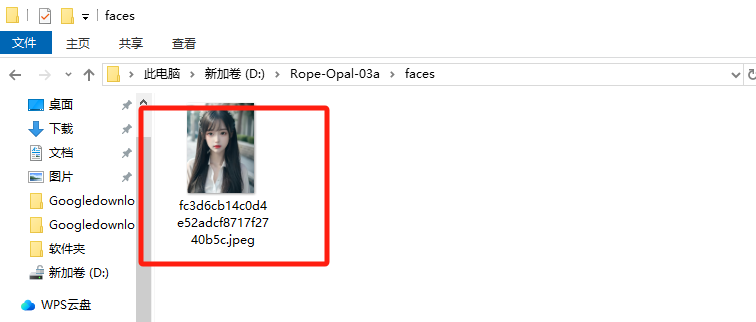
fc3d6cb14c0d4e52adcf8717f2740b5c.jpeg
8. 分析义言的计算机检材,换脸AI程序模型文件数量是多少个:[答案格式:10][★★☆☆☆]
同样在上述路径下
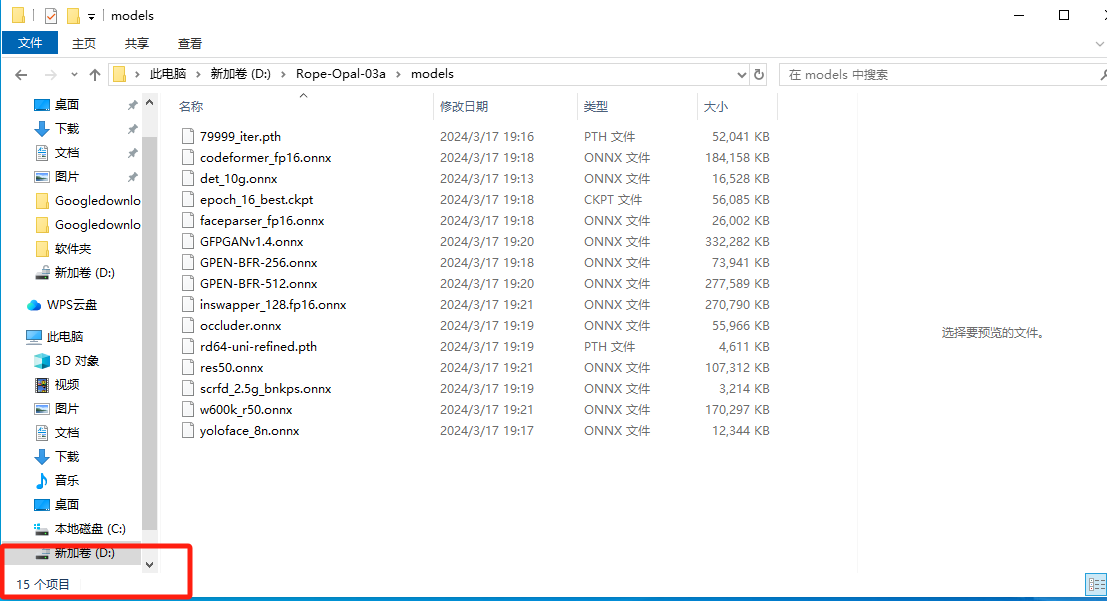
15
总结
人工智能部分
分为声音模型和AI换脸,在火眼中如果找到对应路径,在虚拟机中可以较容易找到答案,主要考察信息检索能力。难点在于第五题的逆向分析,要考虑如何还原换脸视频。这题感觉和ctf比赛的逆向题目流程一模一样——反编译,反混淆,修改文件头进行修复……
IPA部分
IPA这些题目和手机取证差不多,都是在数据库里找信息。第三题可以通过其他题目找到的信息回答。主要学习了realm数据库的查找,以及realm studio的安装和使用。
又是收获满满的一天!
2024盘古石取证比赛(IPA+人工智能)的更多相关文章
- 详解 Facebook 田渊栋 NIPS2017 论文:深度强化学习研究的 ELF 平台
这周,机器学习顶级会议 NIPS 2017 的论文评审结果已经通知到各位论文作者了,许多作者都马上发 Facebook/Twitter/Blog/ 朋友圈分享了论文被收录的喜讯.大家的熟人 Faceb ...
- 为什么edge AI是一个无需大脑的人
为什么edge AI是一个无需大脑的人 Why edge AI is a no-brainer 德勤预计,到2020年,将售出超过7.5亿个edge AI芯片,即在设备上而不是在远程数据中心执行或加速 ...
- 各类人工智能&大数据相关比赛
比赛技巧:https://zhuanlan.zhihu.com/p/28084438 文章来源: https://www.imooc.com/article/72863 随着近几年人工智能和大数据的快 ...
- 学习笔记TF045:人工智能、深度学习、TensorFlow、比赛、公司
人工智能,用计算机实现人类智能.机器通过大量训练数据训练,程序不断自我学习.修正训练模型.模型本质,一堆参数,描述业务特点.机器学习和深度学习(结合深度神经网络). 传统计算机器下棋,贪婪算法,Alp ...
- Livecoding.tv 现正举行iOS及Android App设计比赛
近日,Livecoding.tv, 一个为世界各地的程序员提供在线实时交流的平台,在其网站上发布了一篇通知, 宣布从4月15日至5月15日,会为iOS和Android的开发者举办一场本地移动app设计 ...
- 白话贝叶斯理论及在足球比赛结果预测中的应用和C#实现
离去年“马尔可夫链进行彩票预测”已经一年了,同时我也计划了一个彩票数据框架的搭建,分析和预测的框架,会在今年逐步发表,拟定了一个目录,大家有什么样的意见和和问题,可以看看,留言我会在后面的文章中逐步改 ...
- 记录参加“牛津计划.Docker在线黑客松”比赛的过程
var appInsights=window.appInsights||function(config){ function r(config){t[config]=function(){var i= ...
- 人工智能大数据,公开的海量数据集下载,ImageNet数据集下载,数据挖掘机器学习数据集下载
人工智能大数据,公开的海量数据集下载,ImageNet数据集下载,数据挖掘机器学习数据集下载 ImageNet挑战赛中超越人类的计算机视觉系统微软亚洲研究院视觉计算组基于深度卷积神经网络(CNN)的计 ...
- 如何开始你的CTF比赛之旅-网站安全-
在过去的两个星期里,我已经在DEFCON 22 CTF里检测出了两个不同的问题:“shitsco ”和“ nonameyet ”.感谢所有 的意见和评论,我遇到的最常见的问题是:“我怎么才能在CTFs ...
- 听说alphago又要挑战sc2了?——我眼中的人工智能
乱谈: 之前alphago进行的围棋比赛相当火爆. 一时间我的朋友圈都爆了,因为同学以及相关专业的同学都在发这个,毕竟逼格一下就起来了,我也大肆转发.各种角度,不同层次的不同深度的文章也都扫了几眼. ...
随机推荐
- Telnet qsnctfwp
Windows 安装 Telnet 在控制面板的程序和功能中选择打开或关闭Windows功能 启用 Telnet 客户端并单击确认退出 启动终端,输入命令 telnet 打开 Telnet 客户端 在 ...
- 【Python3.10.4】Centos7 ,centos8,centos9源码安装 python3.10.4 解释器
1.检查是否安装wget如果没有安装则: 终端执行: yum -y install wget 2.下载python3源码包 终端执行: wget https://www.python.org/ftp/ ...
- JavaSE--初识&&开发基础
JDK.JRE.JVM JDK:Java Development Kit java开发环境 JRE:Java Runtime Environment java运行时环境 JVM:JAVA Virtua ...
- redis+lua脚本实现接口限流
写在前面 在多线程的情况下对一个接口进行访问,如果访问次数过大,且没有缓存存在的情况下大量的请求打到数据库可能会存在数据库宕机,从而造成服务的不可用性.往往我们需要对其进行限流操作用来保证服务的高可用 ...
- Java面试题:请谈谈对ThreadLocal的理解?
ThreadLocal是一种特殊的变量存储机制,它提供了一种方式,可以在每个线程中保存数据,而不会受到其他线程的影响.这种机制在多线程编程中非常有用,因为它允许每个线程拥有自己的数据副本,从而避免了数 ...
- axiso封装
import axios from 'axios';import {Message } from 'element-ui'//element-ui提示框组件import config from './ ...
- 力扣1107(MySQL)-每日新用户统计(中等)
题目: Traffic 表: 该表没有主键,它可能有重复的行.activity 列是 ENUM 类型,可能取 ('login', 'logout', 'jobs', 'groups', 'homepa ...
- SaaS服务的私有化部署,这样做最高效|云效工程师指北
简介:为了能够有效且高效地同时管理SaaS版本和私有化版本的发布过程,云效团队也结合云原生的基础设施和标准化工具(比如helm)进行了一系列的探索和实践,并将其中一些通能的能力进行了产品化.本文从问 ...
- WPF 对接 Vortice 调用 WIC 加载图片
本文将告诉大家如何通过 Vortice 库从底层的方式使用 WIC 层加载本地图片文件,解码为 IWICBitmap 图片,然后将 IWICBitmap 图片交给 WPF 进行渲染 本文的前置博客:W ...
- Total Commander 使用 mklink 建立文件夹链接 将 C 盘文件迁移到其他盘
在安装完成了 100000000 个软件之后,我 1T 的 C 盘的空间终于不足了,由于安装了大量的特别挑的不专业的软件,强行放在其他的盘将水土不服.于是在老师傅的指导下,我采用了 mklink 神奇 ...