【Python爬虫】手刃豆瓣近十多年电影排行数据!
源码见我github仓库:https://github.com/xzajyjs/Python_FilmInfo_reptile
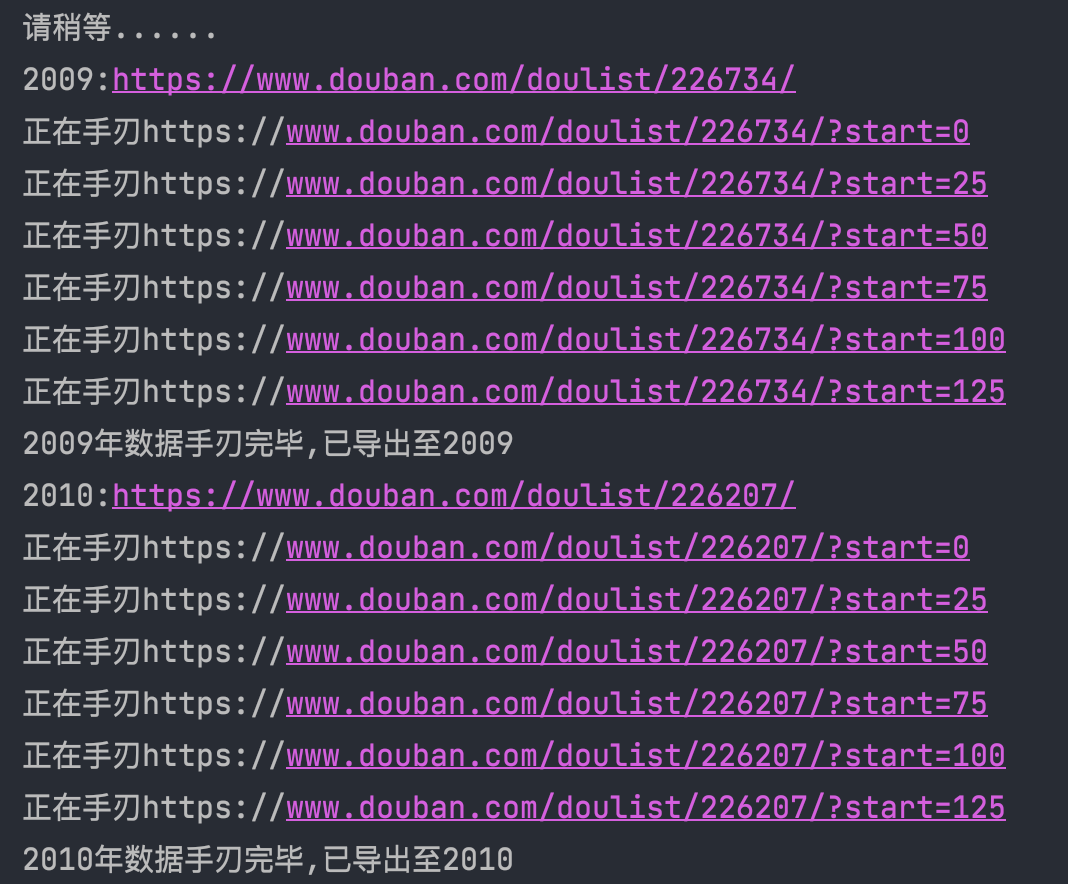
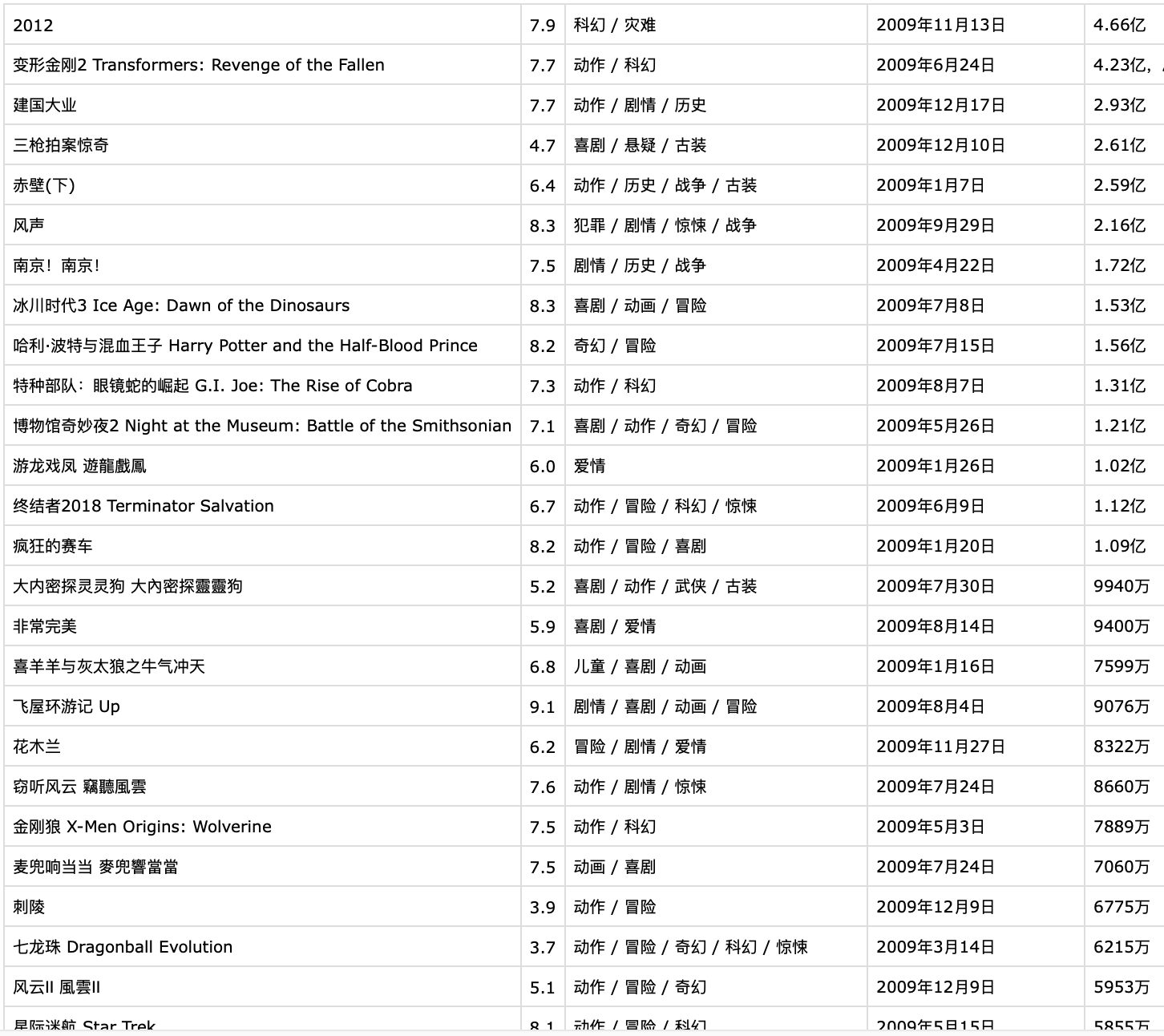
爬取豆瓣上2009-2021年共13年的年度电影排行榜数据,可全自动爬取,爬取内容如下:
- 电影名称
- 电影分类
- 电影上映日期
- 电影票房
已知问题:部分年份的个别电影的票房信息会有少许错误
源码中默认是爬取2009-2021所有年份的信息,如只需要部分年份,只需注释掉
line 42-47,将line 50-62中需要的年份取消注释即可。
【Python爬虫】手刃豆瓣近十多年电影排行数据!的更多相关文章
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
- Python爬虫-爬取豆瓣图书Top250
豆瓣网站很人性化,对于新手爬虫比较友好,没有如果调低爬取频率,不用担心会被封 IP.但也不要太频繁爬取. 涉及知识点:requests.html.xpath.csv 一.准备工作 需要安装reques ...
- 2019-02-01 Python爬虫爬取豆瓣Top250
这几天学了一点爬虫后写了个爬取电影top250的代码,分别用requests库和urllib库,想看看自己能不能搞出个啥东西,虽然很简单但还是小开心. import requests import r ...
- 如何利用python爬虫爬取爱奇艺VIP电影?
环境:windows python3.7 思路: 1.先选取你要爬取的电影 2.用vip解析工具解析,获取地址 3.写好脚本,下载片断 4.将片断利用电脑合成 需要的python模块: ##第一 ...
- Python爬虫:为什么你爬取不到网页数据
前言: 之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:Python爬虫经常爬不到数据,或许你可以看一下小编的这篇文章), 但是当时小编也是胡乱编写的,其实里面有很多问题的,现在小编重新发 ...
- python爬虫实战 获取豆瓣排名前250的电影信息--基于正则表达式
一.项目目标 爬取豆瓣TOP250电影的评分.评价人数.短评等信息,并在其保存在txt文件中,html解析方式基于正则表达式 二.确定页面内容 爬虫地址:https://movie.douban.co ...
- python爬虫 Scrapy2-- 爬取豆瓣电影TOP250
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- Python爬虫爬取豆瓣电影名称和链接,分别存入txt,excel和数据库
前提条件是python操作excel和数据库的环境配置是完整的,这个需要在python中安装导入相关依赖包: 实现的具体代码如下: #!/usr/bin/python# -*- coding: utf ...
- Python爬虫学习笔记——豆瓣登陆(三)
之前是不会想到登陆一个豆瓣会需要写三次博客,修改三次代码的. 本来昨天上午之前的代码用的挺好的,下午时候,我重新注册了一个号,怕豆瓣大号被封,想用小号爬,然后就开始出问题了,发现无法模拟登陆豆瓣了,开 ...
- Python爬虫学习笔记——豆瓣登陆(一)
#-*- coding:utf-8 -*- import requests from bs4 import BeautifulSoup import html5lib import re import ...
随机推荐
- 日常测试进行beans比较的简单方法
日常测试进行beans比较的简单方法 摘要 想每天把有变化的bean抓取出来有新增的beans时能够及时进行分析和介入 保证beans 都是符合规范的. 方式和方法 开启actuator 打开bean ...
- SpringBoot 连接Oracle 12c 以上版本PDB的解决思路
1. 最近公司产品改用springboot开发, 要支持企业级大型数据库Oracle ,并且版本要求比较高,需要使用Oracle12c以上. 又因为Oracle 12c 以上有了一个PDB的可插拔数据 ...
- Opentelemetry Metrics API
Opentelemetry Metrics API 目录 Opentelemetry Metrics API 概览 在没有安装SDK情况下的API行为 Measurements Metric Inst ...
- 谈JVM xmx, xms等内存相关参数合理性设置
作者:京东零售 刘乐 说到JVM垃圾回收算法的两个优化标的:吞吐量和停顿时长,并提到这两个优化目标是有冲突的.那么有没有可能提高吞吐量而不影响停顿时长,甚至缩短停顿时长呢?答案是有可能的,提高内存占用 ...
- Golang Map底层实现简述
Go的map是一种高效的数据结构,用于存储键值对.其底层实现是一个哈希表(hash table),下面是有关map底层实现的详细介绍: 哈希表: map的底层实现是一个哈希表,也称为散列表.哈希表是一 ...
- P1962 斐波那契数列(矩阵快速幂)
#include<bits/stdc++.h> #define int long long using namespace std; int n,a[3],m=1e9+7,c[3][3], ...
- 从零开始配置 vim(17)——快捷键提示
之前我们定义了各种各样的快捷键,有为了增强功能自定义的,有针对插件的.数量一多有的时候就不那么容易记忆了.要是每次要去配置文件找我定义了哪些快捷键肯定会影响使用的. 本篇将要介绍一个插件,它是快捷键的 ...
- 深度学习应用篇-自然语言处理[10]:N-Gram、SimCSE介绍,更多技术:数据增强、智能标注、多分类算法、文本信息抽取、多模态信息抽取、模型压缩算法等
深度学习应用篇-自然语言处理[10]:N-Gram.SimCSE介绍,更多技术:数据增强.智能标注.多分类算法.文本信息抽取.多模态信息抽取.模型压缩算法等 1.N-Gram N-Gram是一种基于统 ...
- Python 基础知识点归纳
Python 是一种跨平台的计算机程序设计语言,是一种面向对象的动态类型语言,笔记内容包括编译安装python,python列表,字典,元组,文件操作等命令的基本使用技巧. 编译安装 Python P ...
- 《熬夜整理》保姆级系列教程-玩转Wireshark抓包神器教程(1)-初识Wireshark
1.简介 前边已经介绍过两款抓包工具,应该是够用了,也能够处理在日常工作中遇到的问题了,但是还是有人留言让宏哥要讲解讲解Wireshark这一款抓包工具,说实话宏哥之前也没有用过这款工具,只能边研究边 ...