Node.js实现简单的爬取
学习【node.js】也有几天时间了,所以打算写着练练手;索然我作为一个后端的选手,写起来还有那么一丝熟悉的感觉。emmm~~ ‘货’不多讲 ,开搞........
首先是依赖选择:

代码块如下:
//引入依赖
//https请求
const https = require('https');
//简称node版的jquery
const cheerio = require('cheerio');
//解决防止出现乱码
const iconv = require('iconv-lite')
//http请求
const request = require("request");
//负责读写文件
const fs = require('fs');
//处理文件路径
const path = require('path');
爬取路径:

代码块:(PS:这里单独拿出来是因为这个站的素材比较推荐,可以上去瞅瞅~~)
const url = 'https://unsplash.com/';
初步实现:
网站的基本构成
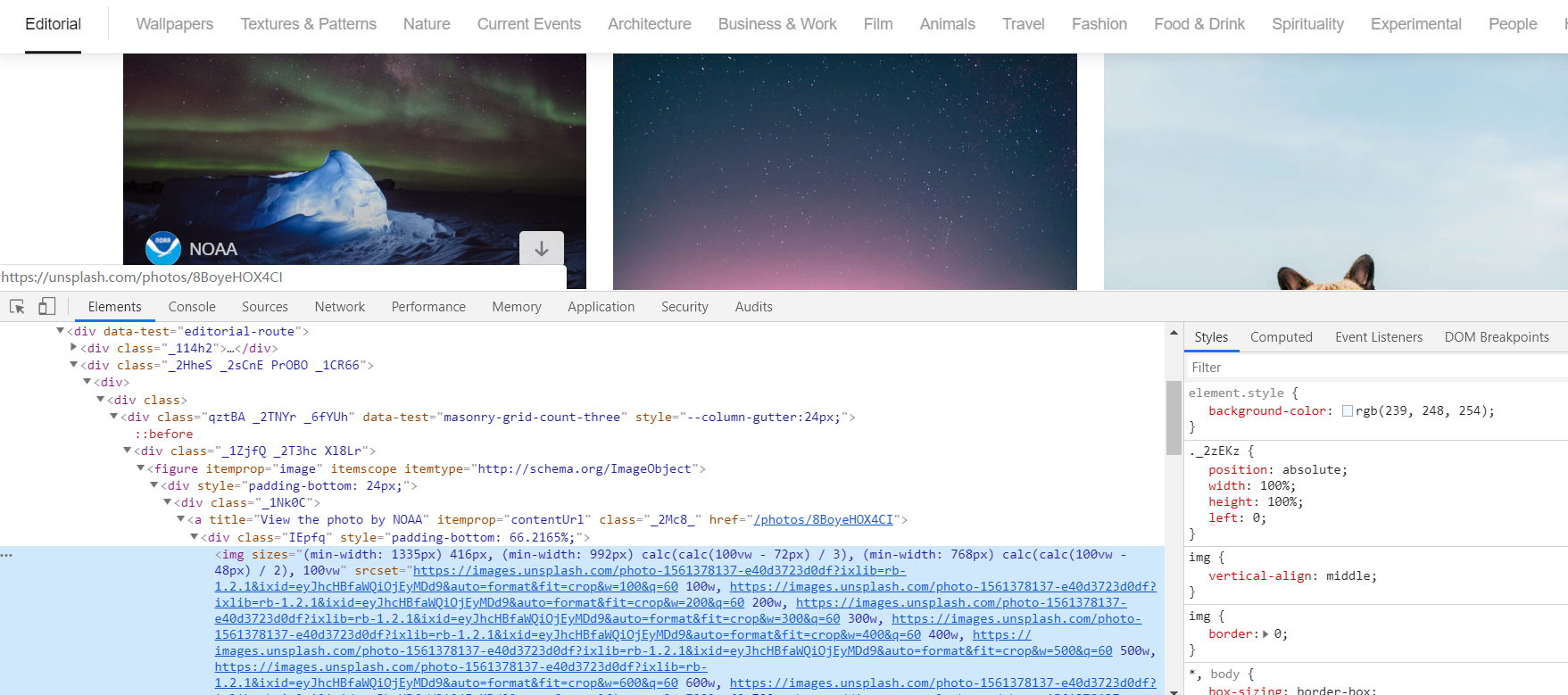
这里主要是我们直接确认一下需要的【img】标签,以及外面的【figure】,然后直接就可以开工了....
核心代码:
//方法对象
const util = { getsrc: function (url) {
https.get(url, res => {
const chunks = [];
res.on('data', chunk => {
// chunks里面存储着网页的html内容
chunks.push(chunk);
});
res.on('end', e => { let ALL = [];
//编码格式
let html = iconv.decode(Buffer.concat(chunks), 'utf8');
let $ = cheerio.load(html, { decodeEntities: false }); //标签遍历
$("figure img").each(function (idex, elent) {
let $elent = $(elent);
let $srcset = $elent.attr("srcset");
if ($srcset != undefined) {
let src = ($srcset.split(',').pop()).split('?')[0];
ALL.push({
src: src
})
}
});
//遍历数组 每个后面加.jpg
ALL.forEach(item => {
util.downloadimg(item.src, path.basename(item.src) + ".jpg", function () {
console.log(path.basename(item.src) + ".jpg");
});
})
}); res.on('error', e => {
console.log('Error: ' + e.message);
});
});
}, //运行主函数
main: function () {
console.log("------start--------");
util.getsrc(url);
},
//下载图片函数
downloadimg: function (src, srcname, callback) { //http请求
request.head(src, function (err, res, body) {
if (err) {
console.log('err:' + err);
return false;
}
console.log('res: ' + res);
//保存数据,这里是防止未来得及记录数据又开始读取数据而导致数据丢失
request(src).pipe(fs.createWriteStream('./img/' + srcname)).on('close', callback);
});
}
} //主函数
util.main();
然后就可以运行 node xxx.js 看运行结果。
Git源码地址:https://github.com/KelvinKey/node-reptile
END Initial entry into the front end, the inadequacies, please bear with me.
Node.js实现简单的爬取的更多相关文章
- node.js 89行爬虫爬取智联招聘信息
写在前面的话, .......写个P,直接上效果图.附上源码地址 github/lonhon ok,正文开始,先列出用到的和require的东西: node.js,这个是必须的 request,然发 ...
- 使用Node.js实现简单的网络爬取
由于最近要实现一个爬取H5游戏的代理服务器,隧看到这么一篇不错的文章(http://blog.miguelgrinberg.com/post/easy-web-scraping-with-nodejs ...
- 关于js渲染网页时爬取数据的思路和全过程(附源码)
于js渲染网页时爬取数据的思路 首先可以先去用requests库访问url来测试一下能不能拿到数据,如果能拿到那么就是一个普通的网页,如果出现403类的错误代码可以在requests.get()方法里 ...
- 使用webmagic爬虫对百度百科进行简单的爬取
分析要爬取的网页源码: 1.打开要分析的网页,查看源代码,找到要爬取的内容: (选择网页里的一部分右击审查元素也行) 2.导入jar包,这个就直接去网上下吧: 3.写爬虫: package com.g ...
- web scraper——简单的爬取数据【二】
web scraper——安装[一] 在上文中我们已经安装好了web scraper现在我们来进行简单的爬取,就来爬取百度的实时热点吧. http://top.baidu.com/buzz?b=1&a ...
- Centos7 中 Node.js安装简单方法
最近,我一直对学习Node.js比较感兴趣.下面是小编给大家带来的Centos7 中 Node.js安装简单方法,在此记录一下,方便自己也方便大家,一起看看吧! 安装node.js 登陆Centos ...
- 创建node.js一个简单的应用实例
在node.exe所在目录下,创建一个叫 server.js 的文件,并写入以下代码: //使用 require 指令来载入 http 模块 var http = require("http ...
- Node.js 实现简单小说爬虫
最近因为剧荒,老大追了爱奇艺的一部网剧,由丁墨的同名小说<美人为馅>改编,目前已经放出两季,虽然整部剧槽点满满,但是老大看得不亦乐乎,并且在看完第二季之后跟我要小说资源,直接要奔原著去看结 ...
- 用node.js实现简单的web服务器
node.js实现web服务器还是比较简单的,我了解node.js是从<node入门>开始的,如果你不了解node.js也可以看看! 我根据那书一步一步的练习完了,也的确大概了解了node ...
随机推荐
- 深入分析 JDK8 中 HashMap 的原理、实现和优化
HashMap 可以说是使用频率最高的处理键值映射的数据结构,它不保证插入顺序,允许插入 null 的键和值.本文采用 JDK8 中的源码,深入分析 HashMap 的原理.实现和优化.首发于微信公众 ...
- 51nod 1433【数学】
思路: 不晓得阿,n%9==0即n数值各个位加起来要%9==0: 如果知道这个,那么%90==0就是末尾多个0就好了,那么后面就是随便搞吧: #include <stdio.h> #inc ...
- 高级开发不得不懂的Redis Cluster数据分片机制
Redis 集群简介 Redis Cluster 是 Redis 的分布式解决方案,在 3.0 版本正式推出,有效地解决了 Redis 分布式方面的需求. Redis Cluster 一般由多个节点组 ...
- SpringBoot的配置文件加载顺序以及如何获取jar包里的资源路径
一.读取配置文件的四种方式 这四种配置文件放置方式的读取优先级依次递减,具体可以查看官方文档. 1.1jar包同级目录下的config文件夹里的配置文件 其实我以前就见过这种方式了,只是不知道怎么做的 ...
- 51Nod 1092 回文字符串
最开始毫无头绪,然后参照了一位dalao的博客,思路是一个正序的字符串将其逆序,然后求最长公共子序列(LCS),emm也属于动态规划. #include <iostream> #inclu ...
- Travelling HDU - 3001
Travelling HDU - 3001 方法:3进制状态压缩dp(更好的方法是预处理出每个状态数字对应的y数组,然后用刷表,时间复杂度可以少一个n) #include<cstdio> ...
- queue+模拟 Codeforces Round #304 (Div. 2) C. Soldier and Cards
题目传送门 /* 题意:两堆牌,每次拿出上面的牌做比较,大的一方收走两张牌,直到一方没有牌 queue容器:模拟上述过程,当次数达到最大值时判断为-1 */ #include <cstdio&g ...
- 1-16使用try-catch捕捉异常
处理异常 可以使用try-catch-处理异常,例如之前的程序可以使用try-catch-处理 package com.monkey1024.exception; import java.io.Fil ...
- Java并发——结合CountDownLatch源码、Semaphore源码及ReentrantLock源码来看AQS原理
前言: 如果说J.U.C包下的核心是什么?那我想答案只有一个就是AQS.那么AQS是什么呢?接下来让我们一起揭开AQS的神秘面纱 AQS是什么? AQS是AbstractQueuedSynchroni ...
- hdu1513 Palindrome
思路: dp+滚动数组. 实现: #include <iostream> #include <cstdio> #include <string> #include ...