使用webmagic爬虫对百度百科进行简单的爬取
分析要爬取的网页源码:
1、打开要分析的网页,查看源代码,找到要爬取的内容:
(选择网页里的一部分右击审查元素也行)

2、导入jar包,这个就直接去网上下吧;
3、写爬虫:
package com.gb.pachong;
import java.sql.SQLException;
import com.gb.util.AddNum;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
public class BaikePaChong implements PageProcessor
{
private static String key;
public static String res=null;
// 抓取网站的相关配置,包括编码、重试次数、抓取间隔
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000);
public void run(String key)
{
this.key = key;
//addUrl就是种子url,Page对象就是当前获取的页面,getUrl()可以获得当前url,addTargetRequests()就是把链接放入等待爬取,getHtml()获得页面的html元素
//启动爬虫
Spider.create(new BaikePaChong()).addUrl("https://baike.baidu.com/item/" + key).thread(5).run();
}
@Override
public Site getSite()
{
return site;
}
@Override
public void process(Page page)
{
//获取页面内容
res = page.getHtml().xpath("//meta[@name='description']/@content").toString();
//把包含数据添加到数据库的方法的类实例化成对象
AddNum addNum=new AddNum();
try
{
//数据添加进数据库
addNum.store(key, res);
}
catch (SQLException e)
{
e.printStackTrace();
}
}
public void search(String string)
{
BaikePaChong baikePaChong = new BaikePaChong();
baikePaChong.run(string);
}
public String getRes()
{
return res;
}
}
4、上面只是简单的爬取,可以仿照这样的方法进行一些别样的扩展使用。
5、Xpath可以在这里直接复制:
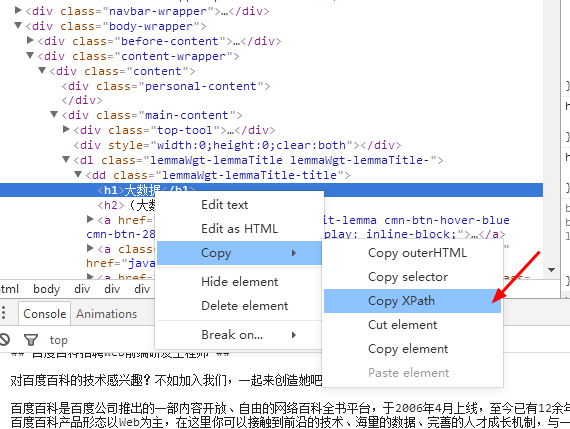
使用webmagic爬虫对百度百科进行简单的爬取的更多相关文章
- Python爬虫学习(5): 简单的爬取
学习了urllib,urlib2以及正则表达式之后就可以做一些简单的抓取以及处理工作.为了抓取方便,这里选择糗事百科的网页作为抓取对象. 1. 获取数据: In [293]: url = " ...
- 爬虫系列(六) 用urllib和re爬取百度贴吧
这篇文章我们将使用 urllib 和 re 模块爬取百度贴吧,并使用三种文件格式存储数据,下面先贴上最终的效果图 1.网页分析 (1)准备工作 首先我们使用 Chrome 浏览器打开 百度贴吧,在输入 ...
- 爬虫系列(十一) 用requests和xpath爬取豆瓣电影评论
这篇文章,我们继续利用 requests 和 xpath 爬取豆瓣电影的短评,下面还是先贴上效果图: 1.网页分析 (1)翻页 我们还是使用 Chrome 浏览器打开豆瓣电影中某一部电影的评论进行分析 ...
- web scraper——简单的爬取数据【二】
web scraper——安装[一] 在上文中我们已经安装好了web scraper现在我们来进行简单的爬取,就来爬取百度的实时热点吧. http://top.baidu.com/buzz?b=1&a ...
- 爬虫系列(十) 用requests和xpath爬取豆瓣电影
这篇文章我们将使用 requests 和 xpath 爬取豆瓣电影 Top250,下面先贴上最终的效果图: 1.网页分析 (1)分析 URL 规律 我们首先使用 Chrome 浏览器打开 豆瓣电影 T ...
- 爬虫概念与编程学习之如何爬取视频网站页面(用HttpClient)(二)
先看,前一期博客,理清好思路. 爬虫概念与编程学习之如何爬取网页源代码(一) 不多说,直接上代码. 编写代码 运行 <!DOCTYPE html><html><head& ...
- Python爬虫入门教程:豆瓣Top电影爬取
基本开发环境 Python 3.6 Pycharm 相关模块的使用 requests parsel csv 安装Python并添加到环境变量,pip安装需要的相关模块即可. 爬虫基本思路 一. ...
- 爬虫入门(三)——动态网页爬取:爬取pexel上的图片
Pexel上有大量精美的图片,没事总想看看有什么好看的自己保存到电脑里可能会很有用 但是一个一个保存当然太麻烦了 所以不如我们写个爬虫吧(๑•̀ㅂ•́)و✧ 一开始学习爬虫的时候希望爬取pexel上的 ...
- Python爬虫之简单的爬取百度贴吧数据
首先要使用的第类库有 urllib下的request 以及urllib下的parse 以及 time包 random包 之后我们定义一个名叫BaiduSpider类用来爬取信息 属性有 url: ...
随机推荐
- Scania SDP3 2.38.2.37.0 Download, Install, Activate: Confirmed
Download: Scania Diagnos & Programmer SDP3 2.38.2.37.0 free version and tested version SDP3 2.38 ...
- OO前三次作业分析
一,第一次作业分析 度量分析: 第一次的oo作业按照常理来说是不应该有这么多的圈复杂度,但是由于第一次写的时候,完全不了解java的相关知识,按照c语言的方式来写,完全的根据指导书的逻辑,先写好了正确 ...
- 每天五分钟,玩转Docker。
Docker技术在国内如火如荼的流行了起来,我当然也想要赶上这时髦的技术啦.下面,我将重新拾起一年多未用的Docker,继续我的云计算之路. Day 1 学习Docker,先从Docker的命令行工 ...
- python (创建虚拟环境)
Python python 介绍 Python是一门计算机编程语言.是一种面向对象的动态类型语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越来越多被用于独立的 ...
- oracle控制台命令
sqlplus /nolog -- 无密码登陆 sqlplus "/as sysdba" -- 以管理员身份登录 shutdown immediate; --关闭数据库 sel ...
- idea安装了Mybaits Plugin插件后,启动不起来了
之前安装了一些插件,谁知道重启完了之后,直接启动不起来了,报错信息如下: cannot load project fatal error initializing plugin com.seven7. ...
- Git系列:第七篇-Maven项目下提交时忽略不必要的文件或文件夹
用.gitignore文件来进行忽略不必要的文件或文件夹 在开发中我们要提交的内容大都是src里的全部文件(java文件).gitignore(忽略文件)pom.xml(maven配置文件)----- ...
- php hash_file
string hash_file ( string $algo , string $filename [, bool $raw_output = FALSE ] ) 参数¶ algo 要使用的哈希算法 ...
- Mysql相关存储函数,函数,游标
https://www.cnblogs.com/zhanglei93/p/6437867.html >>>>请进入
- Python学习过程中各个难点---函数篇
对于函数,我一直分不清局部变量与全局变量,今天又好好研究了下,终于搞清楚了. 例子: 其次对于global这个关键字我也是一知半解的状态,之前整个人都是懵懵的,现在搞明白了 匿名函数: 匿名函数使用关 ...