postgres SQL编译过程
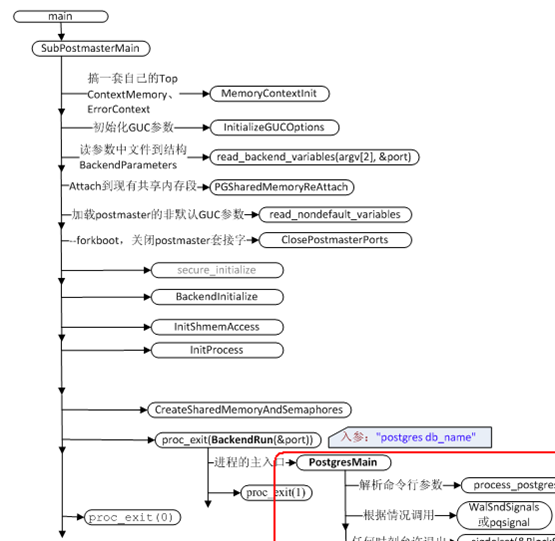

PG启动首先完成主进程和后台进程的启动,启动时完成数据库文件的打开,共享内存的建立等。接着,所有SQL都会启动1个单独的进程处理SQL的执行过程。
新的进程首先是进行自身的初始化,最主要的是初始化内存上下文,准备好SQL处理过程。
进入PostgresMain后,解析客户端命令行参数dbname;做文件、存储、缓存的初始化;设置合适的信号处理句柄;调用InitPostgres方法给portgres服务进程做相关初始化,这个方法里初始化了relcache和catcache,初始化了执行查询计划的portal的管理器,填充本进程PGPROC结构相关部分成员等。进入无限循环,检查并处理任何请求或者最近收到的信号。然后再接着循环。
循环一直在ReadCommand。 进入无限循环后,切换到内存上下文"MessageContext"并清理干净该内存上下文;读取客户端命令;根据客户端各种命令分别进行处理。

客户端发起请求,pg服务器为该请求启动一个postgres访问进程为该客户端通过访问,建立了连接。这个postgres访问进程进入无限循环,等待客户端请求并为其通过服务,直到进程终止,连接断口。
当客户端给服务器端发出查询SQL后,建立连接时已经启动且进入无限循环的服务器端的postgres服务进程处理步骤如下:
(1)调用MemoryContextSwitchTo切换内存上下文到"MessageContext"。
(2)调用MemoryContextResetAndDeleteChildren清理上次为相同连接服务时"MessageContext"内存上下文里遗留的对象。
(3)调用ReadCommand读取客户端的请求。
(4)根据客户端请求判断要提供何种服务,进入相应分支。
从源码的角度分析sql编译过程:
对于一个简单SQL查询,主要的处理过程是先调用start_xact_command方法开启一个事务,再用pg_parse_query方法用词法语法解析工具把查询命令解析为解析树parsetree,根据需要调用PushActiveSnapshot方法搞一个快照,调用pg_analyze_and_rewrite方法分析、根据规则重写解析树为查询树querytree,调用pg_plan_queries方法把查询树转换到执行计划树plantree,在调用相应方法创建portal和在postal中执行执行计划树并给客户端发回结果。然后退出当前事务,清理内存。
src/backend/parser下,scan.l为词法定义,gram.y为语法定义。
postgres SQL编译过程的更多相关文章
- Hive SQL 编译过程
转自:http://www.open-open.com/lib/view/open1400644430159.html Hive跟Impala貌似都是公司或者研究所常用的系统,前者更稳定点,实现方式是 ...
- Hive SQL编译过程(转)
转自:https://www.cnblogs.com/zhzhang/p/5691997.html Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用.美团数据仓库也是基于Hive ...
- 【转】Hive SQL的编译过程
Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用.美团数据仓库也是基于Hive搭建,每天执行近万次的Hive ETL计算流程,负责每天数百GB的数据存储和分析.Hive的稳定性和 ...
- Hive SQL的编译过程
文章转自:http://tech.meituan.com/hive-sql-to-mapreduce.html Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用.美团数据仓库也是 ...
- 转:Hive SQL的编译过程
Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用.美团数据仓库也是基于Hive搭建,每天执行近万次的Hive ETL计算流程,负责每天数百GB的数据存储和分析.Hive的稳定性和 ...
- Hive SQL的编译过程[转载自https://tech.meituan.com/hive-sql-to-mapreduce.html]
https://tech.meituan.com/hive-sql-to-mapreduce.html Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用.美团数据仓库也是基于Hi ...
- Hive SQL的底层编译过程详解
本文结构采用宏观着眼,微观入手,从整体到细节的方式剖析 Hive SQL 底层原理.第一节先介绍 Hive 底层的整体执行流程,然后第二节介绍执行流程中的 SQL 编译成 MapReduce 的过程, ...
- 对MySql查询缓存及SQL Server过程缓存的理解及总结
一.MySql的Query Cache 1.Query Cache MySQL Query Cache是用来缓存我们所执行的SELECT语句以及该语句的结果集.MySql在实现Query Cache的 ...
- Spark源码的编译过程详细解读(各版本)
说在前面的话 重新试多几次.编译过程中会出现下载某个包的时间太久,这是由于连接网站的过程中会出现假死,按ctrl+c,重新运行编译命令. 如果出现缺少了某个文件的情况,则要先清理maven(使用命 ...
随机推荐
- Java-得到类的包
package com.tj; public class MyClass2 { public static void main(String[] args) { Class cls = java.la ...
- 分离焦虑OR责任焦虑
这里是用小孩上幼儿园的事说分离焦虑,转念到成人身上就是责任焦虑. 这周小孩开始上幼儿园了,他很害怕家长离开,我能做的也不多,只是很肯定的告诉他,爸爸就在停车场,下学就来接你,然后从各个 ...
- PHP读取xlsx Excel 文件
<?php require_once 'simplexlsx.class.php'; if ( $xlsx = SimpleXLSX::parse('pricelist.xlsx') ) { p ...
- Leetcode 396.旋转函数
旋转函数 给定一个长度为 n 的整数数组 A . 假设 Bk 是数组 A 顺时针旋转 k 个位置后的数组,我们定义 A 的"旋转函数" F 为: F(k) = 0 * Bk[0] ...
- [BZOJ2393] Cirno的完美算数教室(dfs+容斥原理)
传送门 先通过dfs预处理出来所有只有2和9的数,也就大概2000多个. 想在[L,R]中找到是这些数的倍数的数,可以通过容斥原理 那么如果a % b == 0,那么便可以把 a 去掉,因为 b 的倍 ...
- Mountaineers
Mountaineers 时间限制: 3 Sec 内存限制: 128 MB 题目描述 The Chilean Andes have become increasingly popular as a ...
- SPOJ 4060 A game with probability
博弈论+dp+概率 提交链接- 题意不是很好懂 Ai 表示剩 i 个石头. A 先手的获胜概率. Bi 表示剩 i 个石头. B先手的获胜概率. 如果想选,对于 Ai: 有 p 的概率进入 Bi−1 ...
- Error处理: “非法字符: \65279”的解决办法
将eclipse项目转为maven项目的时候,编译时遇到 “非法字符: \65279”的报错. 出错内容是: *.java:1: 非法字符: \65279 [javac] package com ...
- php——离线执行任务
<?php//设置忽略是否关闭终端窗口ignore_user_abort(true);ini_set('max_execution_time', '0');//采集页面函数,看不懂执行百度cur ...
- golang sort包 排序
[]float64: ls := sort.Float64Slice{ 1.1, 4.4, 5.5, 3.3, 2.2, } fmt.Println(ls) //[1.1 4.4 5.5 3.3 2. ...