STL中关于全排列next_permutation以及prev_permutation的用法
这两个函数都包含在algorithm库中。STL提供了两个用来计算排列组合关系的算法,分别是next_permutation和prev_permutation。
一、函数原型
首先我们来看看这两个函数的函数原型:
- next_permutation:
template< class BidirIt >bool next_permutation( BidirIt first, BidirIt last );
template< class BidirIt, class Compare >bool next_permutation( BidirIt first, BidirIt last, Compare comp );
- prev_permutation:
template< class BidirIt >bool prev_permutation( BidirIt first, BidirIt last);
template< class BidirIt, class Compare >bool prev_permutation( BidirIt first, BidirIt last, Compare comp);
1.参数
first,end ——重新排序的元素范围
comp —— 自定义比较函数
顾名思义,next_permutation就是求下一个排列组合,而prev_permutation就是求上一个排列组合。首先我们必须了解什么是“下一个”排列组合,什么是“前一个”排列组合。考虑由三个字符所组成的序列{a,b,c}。
那么按照字典序排升序他们一共有下面这几种排列方式:
- abc
- acb
- bac
- bca
- cab
- cba
如果给定排列方式P,令P为{acb},那么next_permutation即求P+1也就是{bac},prev_permutation也就是求P-1即为{abc}。当然也可以自定义谓词函数进行自定义的“下一个排列组合”。
二、代码演示
下面是示范代码:
#include <bits/stdc++.h>
using namespace std; int main(){
int a[] = {,,};
do{
for(int i = ; i < ; i++) cout << a[i] << ' ';
cout << endl;
}while(next_permutation(a,a+)); cout << endl;
do{
for(int i = ; i < ; i++) cout << a[i] << ' ';
cout << endl;
}while(prev_permutation(a,a+));
return ;
}
预计上面代码的运行结果应该是输出两组1,2,3的排列组合方式,共12行,但实际运行结果如下:
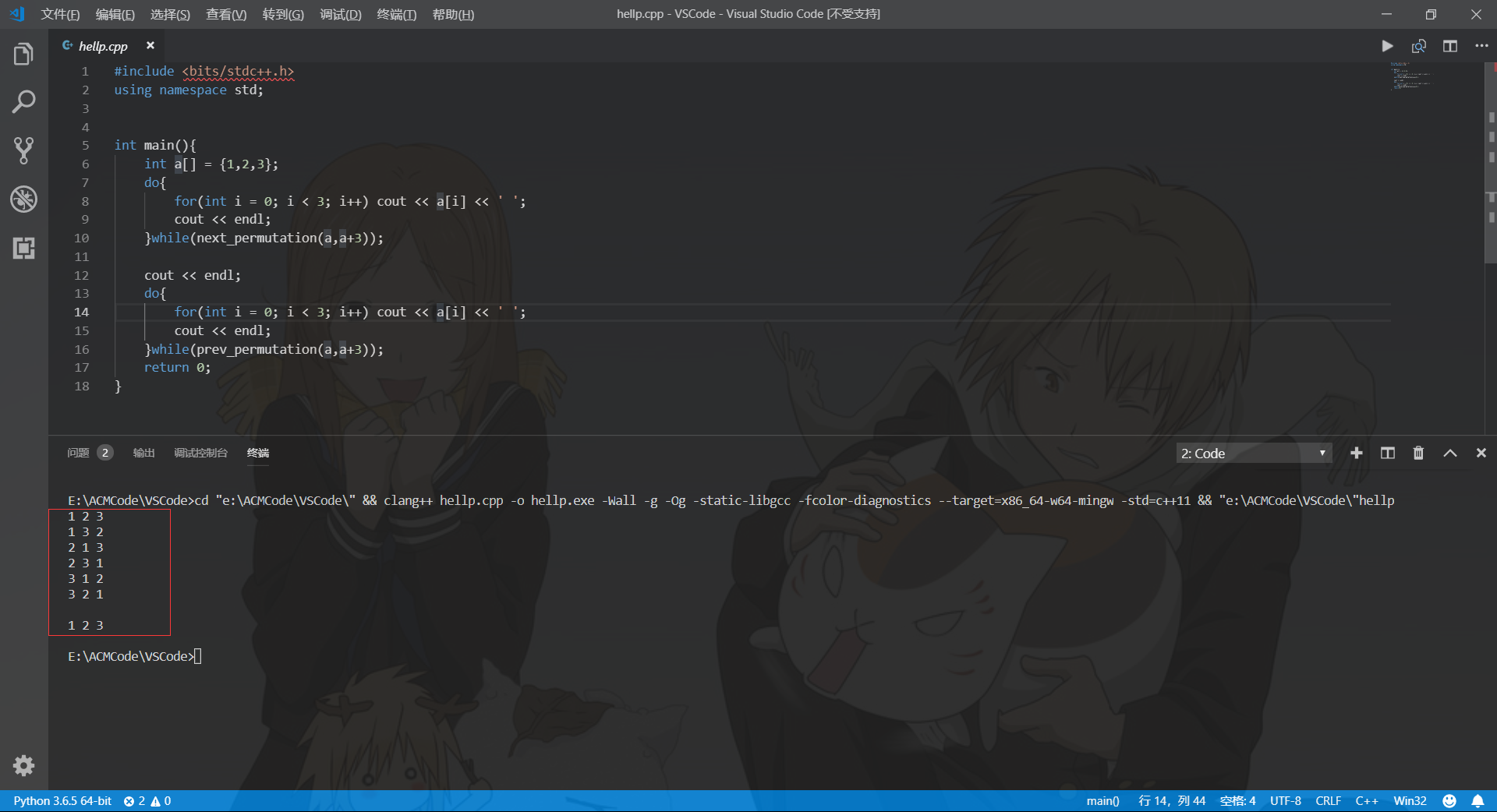
Why?
我们试着输出第一个循环后a数组的排列方式,结果会得到1 2 3,这是因为当next_permutation去找下一个排列组合P+1,找到则排列为下一个排列组合返回true,否则数组变成字典序最小的排列组合(即为重置排列)并返回false,prev_permutation也同理。
三、手动实现
我们先想想如何实现next_permutation,prev_permutation 的原理与之类似。根据字典序,如果排列为正序既从小到大排列,是一组排列组合中最小的排列方式,而逆序既从大到小排列,则是一组排列组合中最大的排列方式。
在n个元素的排列全排列中,从给定排列P 求解下一排列P+1 ,假设两个排列组合有前k位是相同的,那么我们只需要在后面n-k个元素的排列 P(n-k)中求得下一个排列即可。既然我们需要的是后面 n-k位的排列,那么直接从后向前考察。
例如排列 1 2 3 4 5,这是一个正序排列,因此全排列中最小的排列,记为P.
现在要求P+1,设P1=P+1,P1是 1 2 3 5 4. 可以发现P1的前三位和P的前三位完全相同,唯一不同的是后两位顺序颠倒,最后两位从正序的 4 5 变成了逆序的 5 4.
接着求P1+1.设P2 = P1+1,P2是 1 2 4 3 5. 因为最后两位已经是逆序,不可能有字典序更大的排列,因此必须考虑更多的位,在后3个元素中,3 5 4 显然不是逆序,所以存在字典序更大的排列方式,我们由此确定了n-k=3
现在要在 3 5 4 中求得下一个排列,3 5 4 不是一个逆序,是因为 3 后面有元素大于3 。所以我们要在大于3的数字中选择最小的那个和3交换,保证得到最小的首位元素。选择将3和4进行交换,而不是3 和 5,这样得到的首位元素是4. 现在我们得到了排列 4 5 3 。
显然,4 5 3 并不是我们想要的下一个排列,下一个排列是 4 3 5. 观察区别,不难看出,首位元素一定是4,但是5 3 这个子排列是一个逆序排列。将逆序排列反向后,得到的正序排列是所能形成的最小排列,因此,4 3 5 是4 为首位元素所能形成最小排列,而前3 位没有变化,故我们得到了下一排列P2.
另外,大于3的最小元素,即4 ,也是第一个大于3的元素,因为 5 4 是个逆序排列。
对于可重集排列 1 2 3 5 4 3 2 1也同理,首先找到第一个非逆序元素,这里是3,然后从后向前寻找第一个大于3的元素,这里是4,交换,得到 4 5 3 3 2 1 的子排列,然后反向,即可得到下一排列。如果没有找到第一个非逆序元素,那么说明该排列已经是最大排列。
代码:
template<class T>
bool next_permutation(T begin, T end){
T i = end;
if (begin == end || begin == --i) return false; while(){
T i1 = i,i2;
if (*--i < *i1) { //找第k位
for(i2 = end; *i >= *i2; i2--);//从后往前找到逆序中大于*i的元素的最小元素
iter_swap(i, i2);
reverse(i1, end);////将尾部的逆序变成正序
return true;
}
if (i == begin) {
reverse(begin, end);
return false;
}
}
}
prev_permutation的代码实现也类似,这里不再给出,各位可以自行尝试。
四、复杂度分析
最多n/2次交换,n为区间长度,平均每次调用使用了3次比较和1.5次交换,时间复杂度为O(n)。
STL中关于全排列next_permutation以及prev_permutation的用法的更多相关文章
- STL中的全排列实现
permutation: 在遇到全排列问题时,在数据量较小的情况下可以使用dfs的做法求得全排列,同时我们也知道在STL中存在函数next_permutation和prev_permutation,这 ...
- STL中_Rb_tree的探索
我们知道STL中我们常用的set与multiset和map与multimap都是基于红黑树.本文介绍了它们的在STL中的底层数据结构_Rb_tree的直接用法与部分函数.难点主要是_Rb_tree的各 ...
- c++ STL中的next_permutation
default (1) template <class BidirectionalIterator> bool next_permutation (BidirectionalIterato ...
- hdu1027 Ignatius and the Princess II (全排列 & STL中的神器)
转载请注明出处:http://blog.csdn.net/u012860063 题目链接:http://acm.hdu.edu.cn/showproblem.php? pid=1027 Ignatiu ...
- STL中的next_permutation
给定一个数组a[N],求下一个数组. 2 1 3 4 2 1 4 3 2 3 1 4 2 3 4 1 ..... 在STL中就有这个函数: 1.参数是(数组的第一个元素,数组的末尾),注意这是前闭后开 ...
- 枚举所有排列-STL中的next_permutation
枚举排列的常见方法有两种 一种是递归枚举 另一种是STL中的next_permutation //枚举所有排列的另一种方法就是从字典序最小排列开始,不停的调用"求下一个排列"的过程 ...
- STL中的所有算法(70个)
STL中的所有算法(70个)----9种类型(略有修改by crazyhacking) 参考自: http://www.cppblog.com/mzty/archive/2007/03/14/1981 ...
- STL中的算法
STL中的所有算法(70个) 参考自:http://www.cppblog.com/mzty/archive/2007/03/14/19819.htmlhttp://hi.baidu.com/ding ...
- 嵊州D2T2 八月惊魂 全排列 next_permutation()
嵊州D2T2 八月惊魂 这是一个远古时期的秘密,至今已无人关心. 这个世界的每个时代可以和一个 1 ∼ n 的排列一一对应. 时代越早,所对应的排列字典序就越小. 我们知道,公爵已经是 m 个时代前的 ...
随机推荐
- Spring AOP JDK动态代理与CGLib动态代理区别
静态代理与动态代理 静态代理 代理模式 (1)代理模式是常用设计模式的一种,我们在软件设计时常用的代理一般是指静态代理,也就是在代码中显式指定的代理. (2)静态代理由 业务实现类.业务代理类 两部分 ...
- 用友java后端开发面经
面的是深圳的友金锁 3月28号 早上十点 之前来学校宣讲加笔试(笔试做的很菜) 以为凉了,27号被捞起来了,现在看来面了也有点凉 视频面试 时间:19分钟左右 面试官人不错 1 自我介绍 2 自我介绍 ...
- tensorflow学习笔记——多线程输入数据处理框架
之前我们学习使用TensorFlow对图像数据进行预处理的方法.虽然使用这些图像数据预处理的方法可以减少无关因素对图像识别模型效果的影响,但这些复杂的预处理过程也会减慢整个训练过程.为了避免图像预处理 ...
- 【程序人生】从湖北省最早的四位java高级工程师之一到出家为僧所引发的深思
从我刚上大学接触程序员这个职业开始,到如今我从事了七年多程序员,这期间我和我的不少小伙伴接受了太多的负面信息,在成长的道路上也真了交了不少的情商税.这些负面信息中,有一件就是我大学班主任 ...
- Java 8 为什么会引入lambda 表达式?
Java 8 为什么会引入lambda ? 在Java8出现之前,如果你想传递一段代码到另一个方法里是很不方便的.你几乎不可能将代码块到处传递,因为Java是一个面向对象的语言,因此你要构建一个属于某 ...
- Freemarker提供了3种加载模板目录的方法
Freemarker提供了3种加载模板目录的方法 原创 2016年08月24日 14:50:13 标签: freemarker / Configuration 8197 Freemarker提供了3种 ...
- python+jinja2实现接口数据批量生成工具
在做接口测试的时候,我们经常会遇到一种情况就是要对接口的参数进行各种可能的校验,手动修改很麻烦,尤其是那些接口参数有几十个甚至更多的,有没有一种方法可以批量的对指定参数做生成处理呢. 答案是肯定的! ...
- HDU 1847
题意略. 思路:又忘了dp,搜索这种暴力方法了.... #include<bits/stdc++.h> using namespace std; ; bool sg[maxn]; int ...
- Python之函数(一)定义函数以及传参
定义函数以及传参 函数的定义 def 函数名(): 函数体 例子: def func():#def关键字--定义 func函数名--和变量定义规则一样 ()必须要写格式 :声明 语句结束 s=[1,2 ...
- 2019icpc南京网络赛_F_Greedy Sequence
题意 题意不明,队友告诉我对于每个\(i\),所在下标\(p[i]\),在\([p[i]-k,p[i]+k]\)中找到小于\(i\)的最大数\(x\),然后\(ans[i]=ans[x]+1\)即可. ...