SK-learn实现k近邻算法【准确率随k值的变化】-------莺尾花种类预测
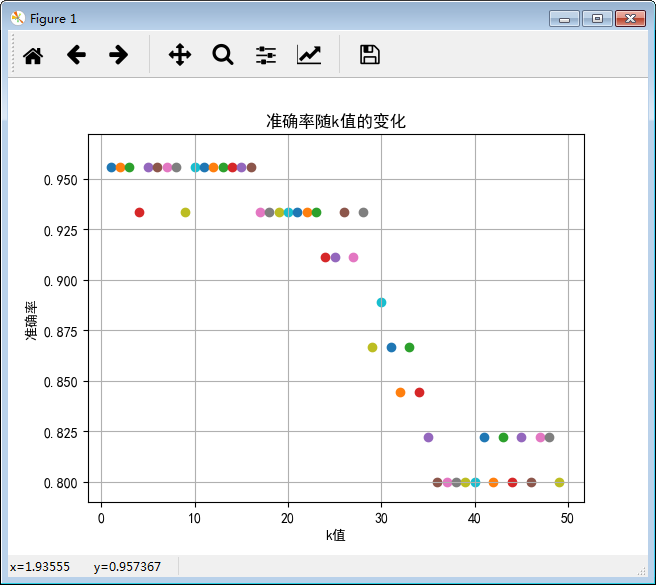
代码详解:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
from pylab import mpl # 设置显示中文字体
mpl.rcParams["font.sans-serif"] = ["SimHei"]
# 设置正常显示符号
mpl.rcParams["axes.unicode_minus"] = False
#读取数据
iris = load_iris() #分出训练集和测试集
x_train,x_test,y_train,y_test = train_test_split(iris.data,iris.target,test_size=0.3,random_state=22) #数据标准化,防止异常点的影响
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test) #创建画布
plt.figure()
plt.title("准确率随k值的变化")
#打开交互
plt.ion()
#网格
plt.grid()
#x轴和y轴标注
plt.ylabel("准确率")
plt.xlabel("k值") #循环k的取值从1到50
for k in range(1,50):
# plt.cla()
#定义一个k分类算法对象
estimator = KNeighborsClassifier(n_neighbors=k)
#训练
estimator.fit(x_train,y_train) #用测试集测试准确率
y_predict = estimator.predict(x_test)
score = estimator.score(x_test, y_test)
#画散点图
plt.scatter(k,score)
plt.pause(0.1) print("预测结果为:",y_predict)
print("对比真实值和预测值:",y_test)
print("准确率:",score) #关闭交互模式,并最后显示图像
plt.ioff()
plt.show()
SK-learn实现k近邻算法【准确率随k值的变化】-------莺尾花种类预测的更多相关文章
- 1.K近邻算法
(一)K近邻算法基础 K近邻(KNN)算法优点 思想极度简单 应用数学知识少(近乎为0) 效果好 可以解释机器学习算法使用过程中的很多细节问题 更完整的刻画机器学习应用的流程 图解K近邻算法 上图是以 ...
- Python3入门机器学习 - k近邻算法
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代 ...
- 02-16 k近邻算法
目录 k近邻算法 一.k近邻算法学习目标 二.k近邻算法引入 三.k近邻算法详解 3.1 k近邻算法三要素 3.1.1 k值的选择 3.1.2 最近邻算法 3.1.3 距离度量的方式 3.1.4 分类 ...
- k近邻算法(KNN)
k近邻算法(KNN) 定义:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别. from sklearn.model_selection ...
- R语言学习笔记—K近邻算法
K近邻算法(KNN)是指一个样本如果在特征空间中的K个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性.即每个样本都可以用它最接近的k个邻居来代表.KNN算法适 ...
- 机器学习(四) 分类算法--K近邻算法 KNN (上)
一.K近邻算法基础 KNN------- K近邻算法--------K-Nearest Neighbors 思想极度简单 应用数学知识少 (近乎为零) 效果好(缺点?) 可以解释机器学习算法使用过程中 ...
- 机器学习(1)——K近邻算法
KNN的函数写法 import numpy as np from math import sqrt from collections import Counter def KNN_classify(k ...
- python 机器学习(二)分类算法-k近邻算法
一.什么是K近邻算法? 定义: 如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别. 来源: KNN算法最早是由Cover和Hart提 ...
- GridSearchCV网格搜索得到最佳超参数, 在K近邻算法中的应用
最近在学习机器学习中的K近邻算法, KNeighborsClassifier 看似简单实则里面有很多的参数配置, 这些参数直接影响到预测的准确率. 很自然的问题就是如何找到最优参数配置? 这就需要用到 ...
随机推荐
- 打造Worktile敏捷开发管理工具的思与惑
从2019年初,我们团队准备开发一款适合研发团队使用的敏捷开发管理工具,那时候我们也在思考,到底什么样的工具才算是优秀的研发管理工具,研发管理的场景.方法和流派有很多,市面上关于研发管理工具的产品也是 ...
- EntityFramework Core 3.x添加查询提示(NOLOCK)
前言 前几天看到有园友写了一篇关于添加NOLOCK查询提示的博文<https://www.cnblogs.com/weihanli/p/12623934.html>,这里呢,我将介绍另外一 ...
- 搬运工 Logstash
1,Logstash 简介 Logstash是一个开源数据收集引擎,具有实时管道功能.Logstash可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地. 通俗的说,就是搬运工 ...
- Sublime Text 2 Install Package Debug
本文转载自CSDN空间freshlover的博客<Sublime Text 无法使用Package Control或插件安装失败的解决方法>,转载请注明出处,谢谢! Sublime Tex ...
- CSS盒子模型(boeder)+浮动(float)+定位(position)
盒子的上下层:margin--background-color--background-image--padding--content--border(最外层) 计算一个盒子宽 = 内容的宽(wid ...
- A AK的距离
时间限制 : - MS 空间限制 : - KB 评测说明 : 1s,128m 问题描述 同学们总想AK.于是何老板给出一个由大写字母构成的字符串,他想你帮忙找出其中距离最远的一对'A'和'K'. ...
- C语言:static关键字用法
参考博客:https://blog.csdn.net/guotianqing/article/details/79828100 看个例子: #include <stdio.h> void ...
- .NET Core项目部署到Linux(Centos7)(五)Centos 7安装.NET Core环境
目录 1.前言 2.环境和软件的准备 3.创建.NET Core API项目 4.VMware Workstation虚拟机及Centos 7安装 5.Centos 7安装.NET Core环境 6. ...
- Jenkins构建项目后发送钉钉消息推送
前言 钉钉是我们日常工作的沟通工具,在Jenkins构建持续集成项目配合钉钉机器人的功能,可以让我们在持续集成测试环节快速接收到测试结果的消息推送. 一:新建一个钉钉群,选择自定义机器人 二:添加机器 ...
- Android 圆形图片库 CircleImageView
高仿微信朋友圈 10s 视频裁剪 引语 晚上好,我是猫咪,我的公众号「程序媛猫咪」会推荐 GitHub 上好玩的项目,挖掘开源的价值,欢迎关注我. <Android 图片裁剪库 uCrop> ...