手把手教大家如何用scrapy爬虫框架爬取王者荣耀官网英雄资料
之前被两个关系很好的朋友拉入了王者荣耀的大坑,奈何技术太差,就想着做一个英雄的随查手册,这样就可以边打边查了。菜归菜,至少得说明咱打王者的态度是没得说的,对吧?大神不喜勿喷!!!感谢!!废话不多说,开始上干货
一 .需要准备的工具
vscoede,安装好的scrapy框架,浏览器,PhantomJS无界面浏览器(或者chromedriver)
二 . 预期目标
爬取王者荣耀官网上77位英雄的ID,名字,皮肤名字,生存能力,攻击伤害,技能效果,上手难度(这四项均是百分制),技能信息,技能加点,铭文建议,推荐出装,英雄故事
三 . 制作过程
1.通过命令行创建scrapy文件夹,并且用vscode打开
2.创建基本流程
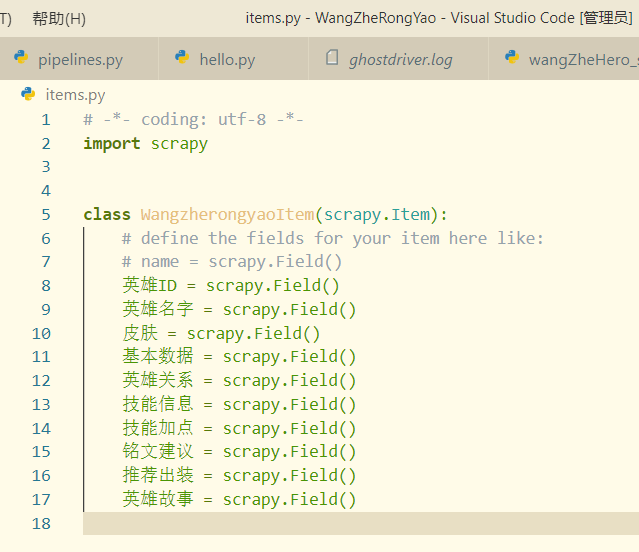
items文件
pipeline(管道)文件:
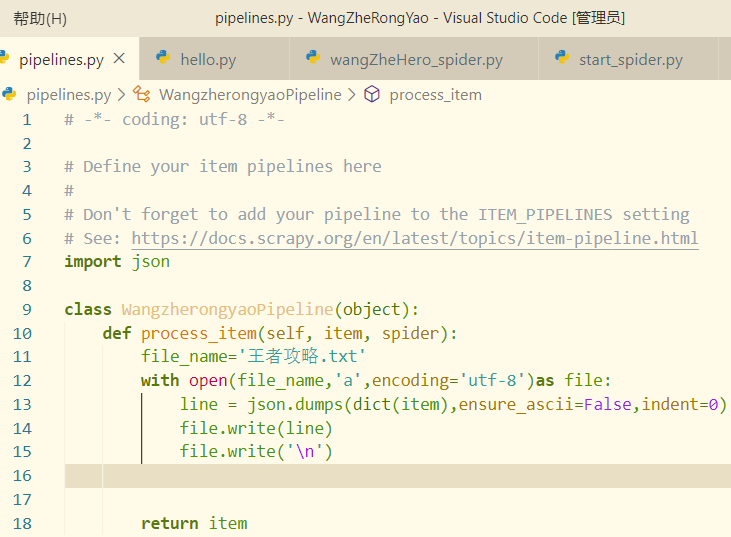
这里为了将python中的dict对象按照一定的格式写入文件,这里采用了json模块,关于这个问题,可以参考我的另一篇博文:
python如何将字典格式化写入文件当中:https://www.cnblogs.com/RosemaryJie/p/12449764.html
在写入文件的过程中,如果出现乱码的问题,请参考:
python编码的原理以及写入文件中乱码的问题:https://www.cnblogs.com/RosemaryJie/p/12364099.html
middleware文件:
配置浏览器User-Agent
如何配置请参考:
python基于scrapy框架的反爬虫机制破解之User-Agent伪装:https://www.cnblogs.com/RosemaryJie/p/12336662.html
写好这些文件之后一定要记得在settings文件中进行配置
3.页面分析(以孙尚香 香香为例)
导入的库:

技能加点部分:
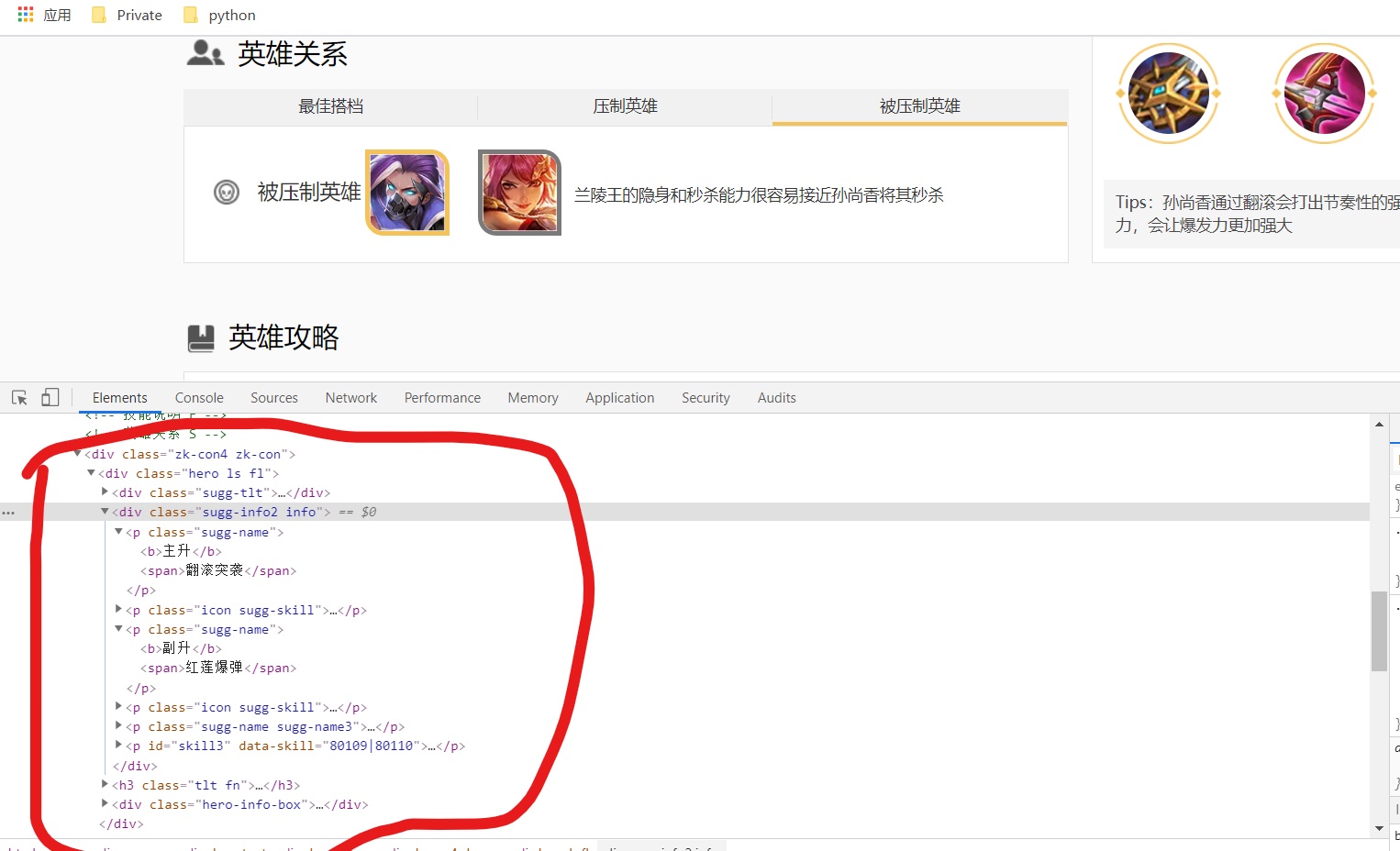
浏览器所显示出来的XHTML文档部分(检查者工具):
网页源代码:

可以明显看到,检查者工具和网页源代码中关于技能加点部分的源代码是不一样的。这时候我们可以采用selenium模块驱动模拟浏览器来获得我们所需要XHTML文本内容(也就是检查者工具里所呈现出的)
为了此篇博客的简介,具体相关内容在这里不再赘述,感兴趣的同学可以移步参考此篇博文:
爬虫如何使用phantomjs无头浏览器解决网页源代码经过渲染的问题(以scrapy框架为例):https://www.cnblogs.com/RosemaryJie/p/12454190.html
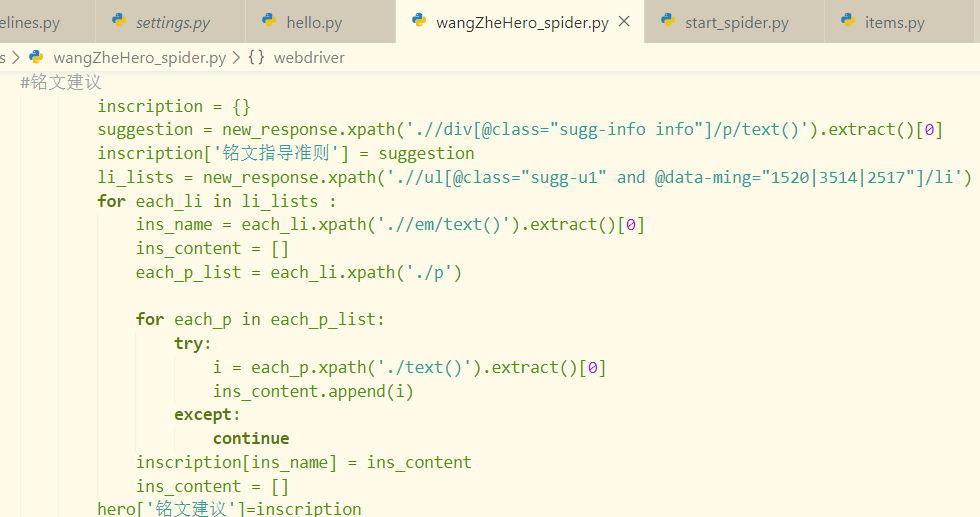
这里采用的方法是重新用所获得XHTML文本构建一个新的HtmlResponse对象

解决了浏览器渲染问题之后,剩下的问题就很简单了,常规xpath提取信息而已,在这里就直接上原码了


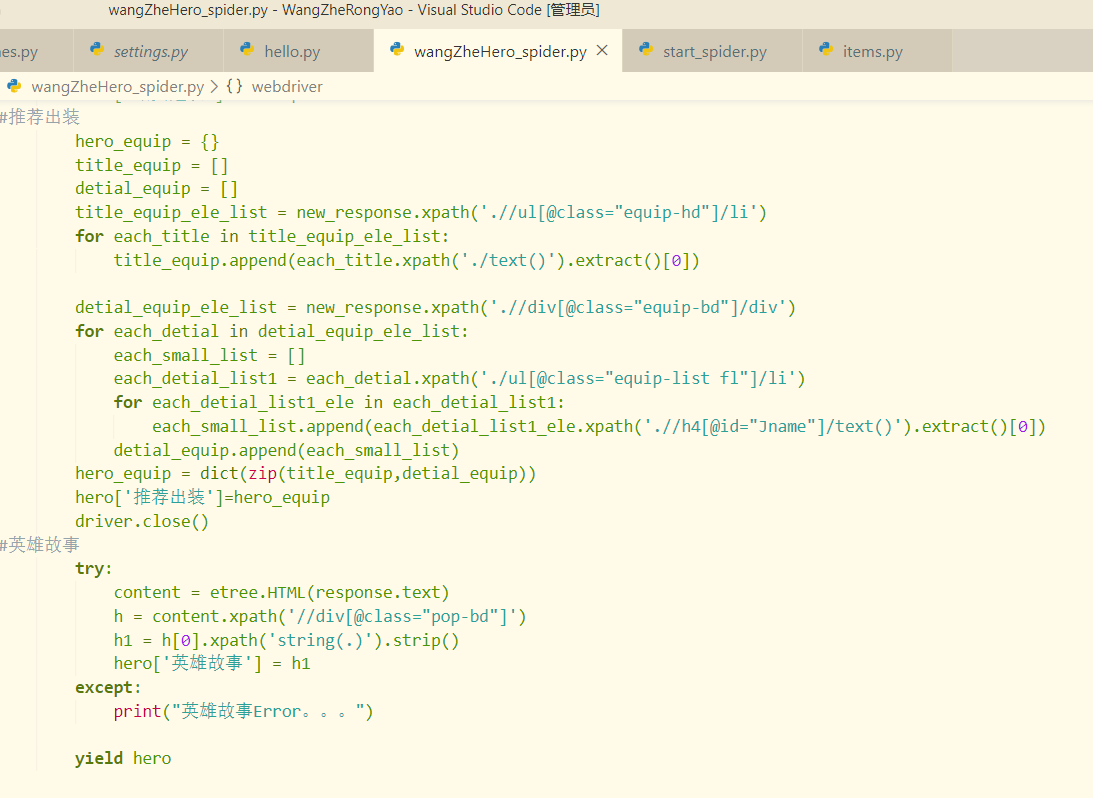


4.运行爬虫即可
至此,一个实用又装逼的爬虫程序就此大功告成
四 .效果图:


在做这个爬虫程序的时候,作为小白,也遇到了不少的坑,也算积攒了些许经验。如果有喜欢王者的同好碰到问题的话,也欢迎在评论区留言交流,我也会尽我所能地帮大家大家做一些解答。
码字不易,点个赞再走呗!
手把手教大家如何用scrapy爬虫框架爬取王者荣耀官网英雄资料的更多相关文章
- 手把手教你如何新建scrapy爬虫框架的第一个项目(上)
前几天给大家分享了如何在Windows下创建网络爬虫虚拟环境及如何安装Scrapy,还有Scrapy安装过程中常见的问题总结及其对应的解决方法,感兴趣的小伙伴可以戳链接进去查看.关于Scrapy的介绍 ...
- 手把手教你如何新建scrapy爬虫框架的第一个项目(下)
前几天小编带大家学会了如何在Scrapy框架下创建属于自己的第一个爬虫项目(上),今天我们进一步深入的了解Scrapy爬虫项目创建,这里以伯乐在线网站的所有文章页为例进行说明. 在我们创建好Scrap ...
- scrapy爬虫框架爬取招聘网站
目录结构 BossFace.py文件中代码: # -*- coding: utf-8 -*-import scrapyfrom ..items import BossfaceItemimport js ...
- python爬虫---爬取王者荣耀全部皮肤图片
代码: import requests json_headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win ...
- 手把手教你写电商爬虫-第三课 实战尚妆网AJAX请求处理和内容提取
版权声明:本文为博主原创文章,未经博主允许不得转载. 系列教程: 手把手教你写电商爬虫-第一课 找个软柿子捏捏 手把手教你写电商爬虫-第二课 实战尚妆网分页商品采集爬虫 看完两篇,相信大家已经从开始的 ...
- Scrapy爬虫笔记 - 爬取知乎
cookie是一种本地存储机制,cookie是存储在本地的 session其实就是将用户信息用户名.密码等)加密成一串字符串,返回给浏览器,以后浏览器每次请求都带着这个sessionId 状态码一般是 ...
- 【网络爬虫】【python】网络爬虫(五):scrapy爬虫初探——爬取网页及选择器
在上一篇文章的末尾,我们创建了一个scrapy框架的爬虫项目test,现在来运行下一个简单的爬虫,看看scrapy爬取的过程是怎样的. 一.爬虫类编写(spider.py) from scrapy.s ...
- 如何用python爬虫从爬取一章小说到爬取全站小说
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取http ...
- python-scrapy爬虫框架爬取拉勾网招聘信息
本文实例为爬取拉勾网上的python相关的职位信息, 这些信息在职位详情页上, 如职位名, 薪资, 公司名等等. 分析思路 分析查询结果页 在拉勾网搜索框中搜索'python'关键字, 在浏览器地址栏 ...
随机推荐
- Docker学习笔记_10 docker应用 - 部署TOMCAT服务
选择基镜像 基镜像使用dokcer hub官方提供的tomcat8 alpine当前最新版本,https://hub.docker.com/_/tomcat/ docker pull tomcat:8 ...
- MyBatis基本使用步骤
MyBatis是一个数据持久层(ORM)框架.把实体 类和SQL语句之间建立了映射关系,是一种半自 动化的ORM实现.MyBATIS需要开发人员自己来写sql语句,这可以增加了程序的灵活性,在一定程度 ...
- CSAPC08台湾邀请赛_T1_skyline
题目链接:CSAPC08台湾邀请赛_T1_skyline 题目描述 一座山的山稜线由许多片段的45度斜坡构成,每一个片段不是上坡就是下坡. / / * / / * / // / // / 在我 ...
- 中国的规模优势,有望帮助AI芯片后来者居上?
芯片一直是个神奇的东西,表面上看是电脑.笔记本.智能手机改变了世界,其实,真正改变世界的硬件内核是芯片,芯片相关的技术才是科技界最实用.最浪漫的基础技术,也正因如此,谁掌握了芯片基础技术,谁就能立于 ...
- android中SeekBar拖动进度条的使用及事件监听
下面和大家分享一下android中SeekBar拖动进度条的使用,以及事件监听.拖动进度条的事件监听需要实现SeekBar.OnSeekBarChangeListener接口,调用SeekBar的se ...
- 5——PHP逻辑运算符&&唯一的三元运算符
*/ * Copyright (c) 2016,烟台大学计算机与控制工程学院 * All rights reserved. * 文件名:text.cpp * 作者:常轩 * 微信公众号:Worldhe ...
- XML的相关基础知识分享(二)
前面我们讲了一下XML相关的基础知识(一),下面我们在加深一下,看一下XML高级方面. 一.命名空间 1.命名冲突 XML命名空间提供避免元素冲突的方法. 命名冲突:在XML中,元素名称是由开发者定义 ...
- Ubutun18.04安装Python3.7.6
最近因为环境问题,简单记录下Python3.7的安装过程: 下载地址:http://python.org/ftp/python/3.7.6/Python-3.7.6.tgz 编译安装步骤: sudo ...
- 基于google earth engine的中等分辨率全国水质反演
我写博客的工作不像论文,假大空,我们直接上干货,之所以取一个这么大的名字,当然是我们能做到的... 不多说,我们对全国水体进行水质参数反演,不用MODIS,太粗,我们直接用哨兵,这样就可以直接做到大型 ...
- 二叉堆的BuildHeap操作
优先队列(二叉堆)BuildHeap操作 \(BuildHeap(H)\)操作把\(N\)个关键字作为输入并把它们放入空堆中.显然,这可以使用\(N\)个相继的\(Insert\)操作来完成.由于每个 ...