RDD(七)——依赖
概述
RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
示例代码如下:
def main(args: Array[String]): Unit = {
val sc: SparkContext = new SparkContext(new SparkConf()
.setMaster("local[*]").setAppName("spark"))
val f: RDD[(String, Int)] = sc.parallelize(Array("hello,spark", "hello,scala", "hello,world"))
.flatMap(_.split(" "))
.map((_, 1))
print(f.toDebugString)//查看依赖信息
println(f.dependencies)//查看依赖类型
}
它的依赖信息如下:
(8) MapPartitionsRDD[2] at map at Lineage.scala:11 []
| MapPartitionsRDD[1] at flatMap at Lineage.scala:10 []
| ParallelCollectionRDD[0] at parallelize at Lineage.scala:9 []
从上往下,依次是RDD的转换过程。通过这些信息,当链条中的任意一个RDD的部分分区数据丢失时,它可以根据这些信息重新进行运算,恢复丢失的分区数据。
窄依赖、宽依赖
窄依赖指的是每一个父RDD的Partition最多被子RDD的一个Partition使用。窄依赖我们形象的比喻为独生子女。
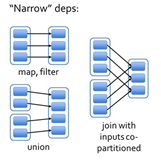
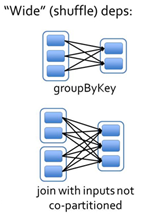
宽依赖指的是多个子RDD的Partition会依赖同一个父RDD的Partition,会引起shuffle.宽依赖我们形象的比喻为超生
任务划分
RDD任务切分分为:Application、Job、Stage和Task
1)Application:初始化一个SparkContext即生成一个ApplicationMaster
2)Job:一个Action算子就会生成一个Job
3)Stage:根据RDD之间的依赖关系的不同将Job划分成不同的Stage,遇到一个宽依赖(shuffle)则划分一个Stage。
4)task:一个RDD有多个分区,一个分区在一个executor尚的执行就可以算作一个task
对于窄依赖,partition的转换处理在Stage中完成计算。对于宽依赖,由于有Shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算,因此宽依赖是划分Stage的依据。
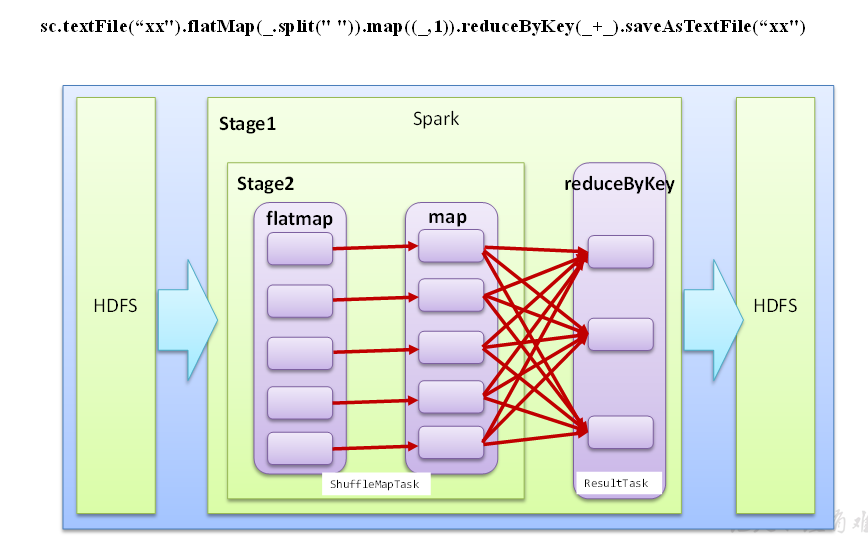
阶段划分过程如下:
首先无论如何要有一个阶段,这是一个总体的阶段。然后再看中间有多少个shuffle过程,遇到一个shuffle,则切分出一个阶段。
textFile方法从HDFS文件系统读取数据;flatMap,map方法均没有shuffle过程,不能形成阶段;reduceByKey有shuffle过程,可以形成阶段。总共有两个阶段。
RDD(七)——依赖的更多相关文章
- Spark RDD概念学习系列之RDD的依赖关系(宽依赖和窄依赖)(三)
RDD的依赖关系? RDD和它依赖的parent RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency). 1)窄依赖指的是每 ...
- RDD的依赖关系
RDD的依赖关系 Rdd之间的依赖关系通过rdd中的getDependencies来进行表示, 在提交job后,会通过在DAGShuduler.submitStage-->getMissingP ...
- Spark RDD概念学习系列之rdd的依赖关系彻底解密(十九)
本期内容: 1.RDD依赖关系的本质内幕 2.依赖关系下的数据流视图 3.经典的RDD依赖关系解析 4.RDD依赖关系源码内幕 1.RDD依赖关系的本质内幕 由于RDD是粗粒度的操作数据集,每个Tra ...
- Spark核心RDD、什么是RDD、RDD的属性、创建RDD、RDD的依赖以及缓存、
1:什么是Spark的RDD??? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行 ...
- 021 RDD的依赖关系,以及造成的stage的划分
一:RDD的依赖关系 1.在代码中观察 val data = Array(1, 2, 3, 4, 5) val distData = sc.parallelize(data) val resultRD ...
- Spark RDD 窄依赖研究
1.. 简介 spark从RDD依赖上来说分为窄依赖和宽依赖. 其中可以这样区分是哪种依赖:当父RDD的一个partition被子RDD的多个partitions引用到的时候则说明是宽依赖,否则为窄依 ...
- sparkRDD:第4节 RDD的依赖关系;第5节 RDD的缓存机制;第6节 DAG的生成
4. RDD的依赖关系 6.1 RDD的依赖 RDD和它依赖的父RDD的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency ...
- Spark RDD 宽窄依赖
RDD 宽窄依赖 RDD之间有一系列的依赖关系, 可分为窄依赖和宽依赖 窄依赖 从 RDD 的 parition 角度来看 父 RRD 的 parition 和 子 RDD 的 parition 之间 ...
- 【Spark】RDD的依赖关系和缓存相关知识点
文章目录 RDD的依赖关系 宽依赖 窄依赖 血统 RDD缓存 概述 缓存方式 RDD的依赖关系 RDD和它依赖的父RDD的关系有两种不同的类型,即窄依赖(narrow dependency) 和宽依赖 ...
随机推荐
- 2pc和3pc区别
2pc和3pc区别 3pc背景: 2pc协议在协调者和执行者同时宕机时(协调者和执行者不同时宕机时,都能确定事务状态),选出协调者之后 无法确定事务状态,会等待宕机者恢复才会继续执行(无法利用定 ...
- Maven:A cycle was detected in the build path of project 'xxx'. The cycle consists of projects {xx}
以下这个错误是在Eclipse中导入多个相互依赖的工程时出现的“循环依赖问题”:A cycle was detected in the build path of project 'xxx'. The ...
- Delphi7 流操作_压缩
unit Unit1; interface uses Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms ...
- 【mac相关bash文件】
mac 下 关于 .bashrc 和 .bash_profile 1.首先.bashrc 可能自带的系统里没有这个文件. 2.bash_profile 里边一半放的是PATH相关. 3. .bash ...
- UML-迭代2:更多模式
1.之前的初始阶段+细化阶段中的迭代1讲述的是广泛使用的基本分析和对象设计技术.而迭代2中,案例研究只强调: 对象设计和模式: 1).基本对象设计(基于职责和GRASP) 2).使用模式来创建稳固的设 ...
- Pytorch学习--编程实战:猫和狗二分类
Pytorch学习系列(一)至(四)均摘自<深度学习框架PyTorch入门与实践>陈云 目录: 1.程序的主要功能 2.文件组织架构 3. 关于`__init__.py` 4.数据处理 5 ...
- git push报错! [rejected] master -> master (non-fast-forward) error: failed to push some refs to 'https://gitee.com/XXX.git
git pull origin master --allow-unrelated-histories //把远程仓库和本地同步,消除差异 git add . git commit -m"X ...
- @Data与@ConfigurationProperties 简化配置属性数据
参考地址:https://www.cnblogs.com/FraserYu/p/11261916.html 在编写项目代码时,我们要求更灵活的配置,更好的模块化整合.在 Spring Boot 项 ...
- idtcp实现文件下载和上传
unit Unit1; interface uses Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms ...
- 吴裕雄--天生自然Linux操作系统:Linux 远程登录
Linux一般作为服务器使用,而服务器一般放在机房,你不可能在机房操作你的Linux服务器. 这时我们就需要远程登录到Linux服务器来管理维护系统. Linux系统中是通过ssh服务实现的远程登录功 ...