w3cschool-Python3 爬虫抓取、深度/机器学习类
https://www.w3cschool.cn/python3/python3-enbl2pw9.html
(1) requests安装
在cmd中,使用如下指令安装requests:
pip install requests- 1
或者:
easy_install requests- 1
(2) 简单实例
requests库的基础方法如下:

requests中文文档:http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
requests库的开发者为我们提供了详细的中文教程,查询起来很方便。本文不会对其所有内容进行讲解,摘取其部分使用到的内容,进行实战说明。
首先,让我们看下requests.get()方法,它用于向服务器发起GET请求,不了解GET请求没有关系。我们可以这样理解:get的中文意思是得到、抓住,那这个requests.get()方法就是从服务器得到、抓住数据,也就是获取数据。让我们看一个例子(以 www.gitbook.cn为例)来加深理解:
# -*- coding:UTF-8 -*-
import requests
if __name__ == '__main__':
target = 'http://gitbook.cn/'
req = requests.get(url=target)
print(req.text)(3)Beautiful Soup
爬虫的第一步,获取整个网页的 HTML 信息,我们已经完成。接下来就是爬虫的第二步,解析 HTML 信息,提取我们感兴趣的内容。对于本小节的实战,我们感兴趣的内容就是文章的正文。提取的方法有很多,例如使用正则表达式、Xpath、Beautiful Soup 等。对于初学者而言,最容易理解,并且使用简单的方法就是使用 Beautiful Soup 提取感兴趣内容。
Beautiful Soup 的安装方法和 requests 一样,使用如下指令安装(也是二选一):
- pip install beautifulsoup4
- easy_install beautifulsoup4
一个强大的第三方库,都会有一个详细的官方文档。我们很幸运,Beautiful Soup 也是有中文的官方文档:http://beautifulsoup.readthedocs.io/zh_CN/latest/
同理,我会根据实战需求,讲解 Beautiful Soup 库的部分使用方法,更详细的内容,请查看官方文档。
知道这个信息,我们就可以使用 Beautiful Soup 提取我们想要的内容了,编写代码如下:
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://www.biqukan.com/1_1094/5403177.html'
req = requests.get(url = target)
html = req.text
bf = BeautifulSoup(html)
texts = bf.find_all('div', class_ = 'showtxt')
print(texts)Python3爬虫图片抓取
我截取了Fiddler的抓包信息,可以看到Requests Headers里又很多参数,有Accept、Accept-Encoding、Accept-Language、DPR、User-Agent、Viewport-Width、accept-version、Referer、x-unsplash-client、authorization、Connection、Host。它们都是什么意思呢?
专业的解释能说的太多,我挑重点:
- User-Agent:这里面存放浏览器的信息。可以看到上图的参数值,它表示我是通过Windows的Chrome浏览器,访问的这个服务器。如果我们不设置这个参数,用Python程序直接发送GET请求,服务器接受到的User-Agent信息就会是一个包含python字样的User-Agent。如果后台设计者验证这个User-Agent参数是否合法,不让带Python字样的User-Agent访问,这样就起到了反爬虫的作用。这是一个最简单的,最常用的反爬虫手段。
- Referer:这个参数也可以用于反爬虫,它表示这个请求是从哪发出的。可以看到我们通过浏览器访问网站,这个请求是从https://unsplash.com/,这个地址发出的。如果后台设计者,验证这个参数,对于不是从这个地址跳转过来的请求一律禁止访问,这样就也起到了反爬虫的作用。
- authorization:这个参数是基于AAA模型中的身份验证信息允许访问一种资源的行为。在我们用浏览器访问的时候,服务器会为访问者分配这个用户ID。如果后台设计者,验证这个参数,对于没有用户ID的请求一律禁止访问,这样就又起到了反爬虫的作用。
Unsplash是根据哪个参数反爬虫的呢?根据我的测试,是authorization。我们只要通过程序手动添加这个参数,然后再发送GET请求,就可以顺利访问了。怎么什么设置呢?还是requests.get()方法,我们只需要添加headers参数即可。编写代码如下:
# -*- coding:UTF-8 -*-
import requests
if __name__ == '__main__':
target = 'http://unsplash.com/napi/feeds/home'
headers = {'authorization':'your Client-ID'}
req = requests.get(url=target, headers=headers, verify=False)
print(req.text)Python3爬取房价信息并分析
开发工具
Python版本:3.6.4
相关模块:openpyxl模块;requests模块;bs4模块;pyecharts模块;以及一些python自带的模块。
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
pyecharts模块安装可参考:
Python简单分析微信好友
原理简介
需求:
根据输入的城市名获取该城市的房价信息;
对获得的数据进行简单的分析。
目标网站:
链家网(https://dl.lianjia.com/)
目标数据(图中圈出的):

实现思路:
很基础的爬虫,不需要任何分析。直接请求需要的网页地址,然后利用bs4模块解析请求返回的数据并获取所需的信息即可。
然后再对这些信息进行简单的分析。
其中信息保存到Excel中,分析时读取即可。
具体实现细节详见相关文件中的源代码。
数据爬取演示
在cmd窗口运行Spider.py文件后根据提示输入相关的信息即可。
视频演示如下:
数据分析
以北京为例:
北京房价(元/平方):
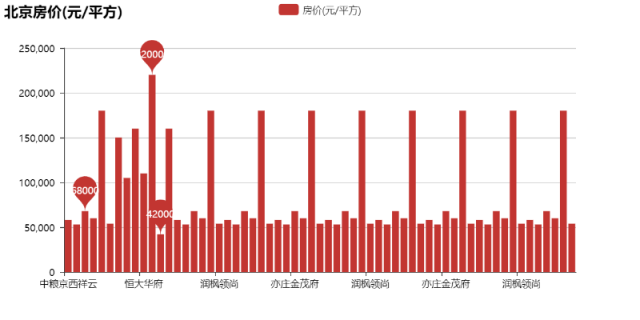
北京房价(万元/套起):

emmmm,算了,不分析了吧。
深度/机器学习类
预测NBA比赛结果
主要思路
(1)数据选取
获取数据的链接为:
https://www.basketball-reference.com/
获取的数据内容为:
每支队伍平均每场比赛的表现统计;
每支队伍的对手平均每场比赛的表现统计;
综合统计数据;
2016-2017年NBA常规赛以及季后赛的每场比赛的比赛数据;
2017-2018年NBA的常规赛以及季后赛的比赛安排。
(2)建模思路
主要利用数据内容的前四项来评估球队的战斗力。
利用数据内容的第五项也就是比赛安排来预测每场比赛的获胜队伍。
利用方式为:
数据内容的前三项以及根据数据内容的第四项计算的Elo等级分作为每支队伍的特征向量。
Elo等级分介绍(相关文件中有):

为方便起见,假设获胜方提高的Elo等级分与失败方降低的Elo等级分数值相等。
另外,为了体现主场优势,主场队伍的Elo等级分在原有基础上增加100。
(3)代码流程
数据初始化;
计算每支队伍的Elo等级分(初始值1600);
基于数据内容前三项和Elo等级分建立2016-2017年常规赛和季后赛中每场比赛的数据集;
使用sklearn中的LogisticRegression函数建立回归模型;
利用训练好的模型对17-18年常规赛和季后赛的比赛结果进行预测;
将预测结果保存到17-18Result.CSV文件中。
开发工具
Python版本:3.5.4
相关模块:pandas模块、numpy模块、sklearn模块以及一些Python自带的模块。
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
使用演示
在cmd窗口运行Analysis_NBA_Data.py文件即可:
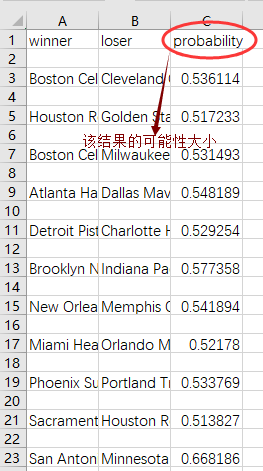
结果:
更多
文章的初衷是为了让公众号推送的关于Python的小项目涉及的应用领域更加丰富多彩。从而激发部分Python初学者的学习热情,仅此而已。
这篇文章的技术含量并不高,模型简单,数据处理方式也比较随意。。。
可以优化的地方大概包括:
增加训练数据(如多利用几年数据);
优化训练模型(如sklearn中其他机器学习方法或者利用深度学习框架搭建相应的网络进行模型训练)。
Python3简单分析高考数据
开发工具
Python版本:3.6.4
相关模块:pyecharts模块;以及一些Python自带的模块。
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
pyecharts模块的安装可参考:
安装Python并添加到环境变量,pip安装需要的相关模块即可。
额外说明:
pyecharts模块安装时请依次执行以下命令:
pip install echarts-countries-pypkg
pip install echarts-china-provinces-pypkg
pip install echarts-china-cities-pypkg
pip install pyecharts
若安装过程中出现:
'utf-8' codec can't decode byte 0xb6
或者类似的编码错误提示。
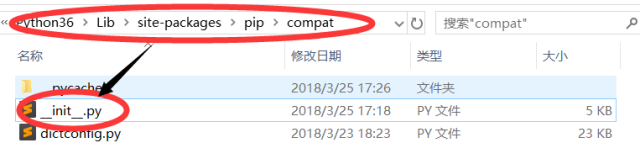
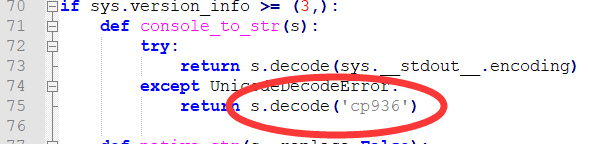
可尝试修改Python安装文件夹下如下图所示路径下的__init__.py文件的第75行代码:
修改为下图所示内容:
“一本正经的分析”
开始分析
首先让我们来看看从恢复高考(1977年)开始高考报名、最终录取的总人数走势吧:
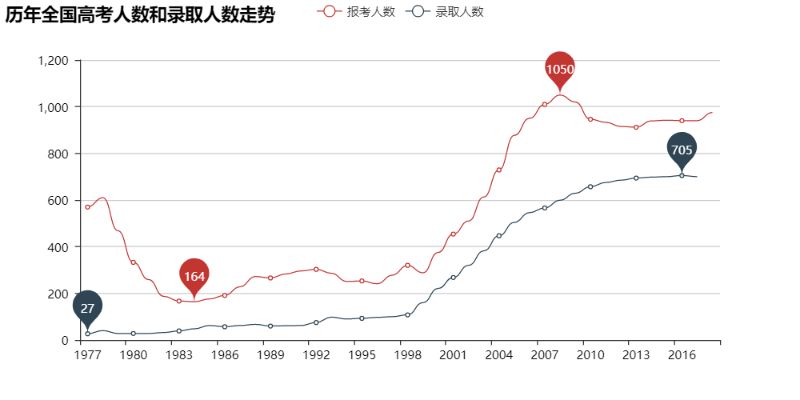
T_T看来学生党确实是越来越多了。
不过这样似乎并不能很直观地看出每年的录取比例?Ok,让我们直观地看看吧:
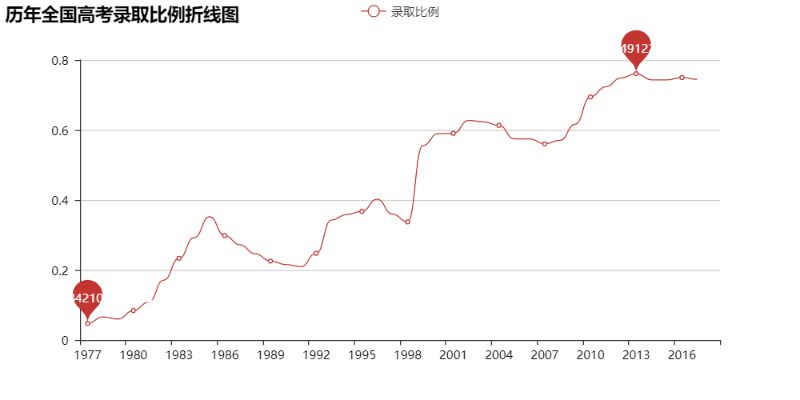
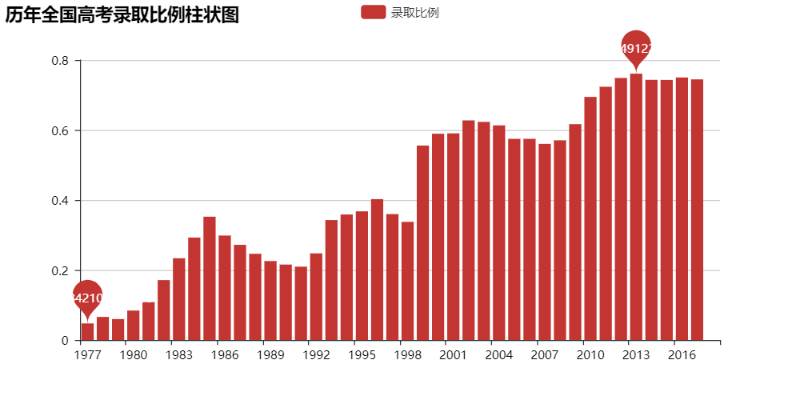
看来上大学越来越“容易”之说不是空穴来风的,总录取比例高的可怕~~~
那么各省的情况呢?
由于各省高考最终录取人数的统计标准不一样,有些是只统计本科,有些是都统计的,为了避免统计标准不一而带来的不公平对比,我们只分析各省的高考报考人数。
从2010年开始到今年(2018年)各省份高考考生数量的分布图如下:
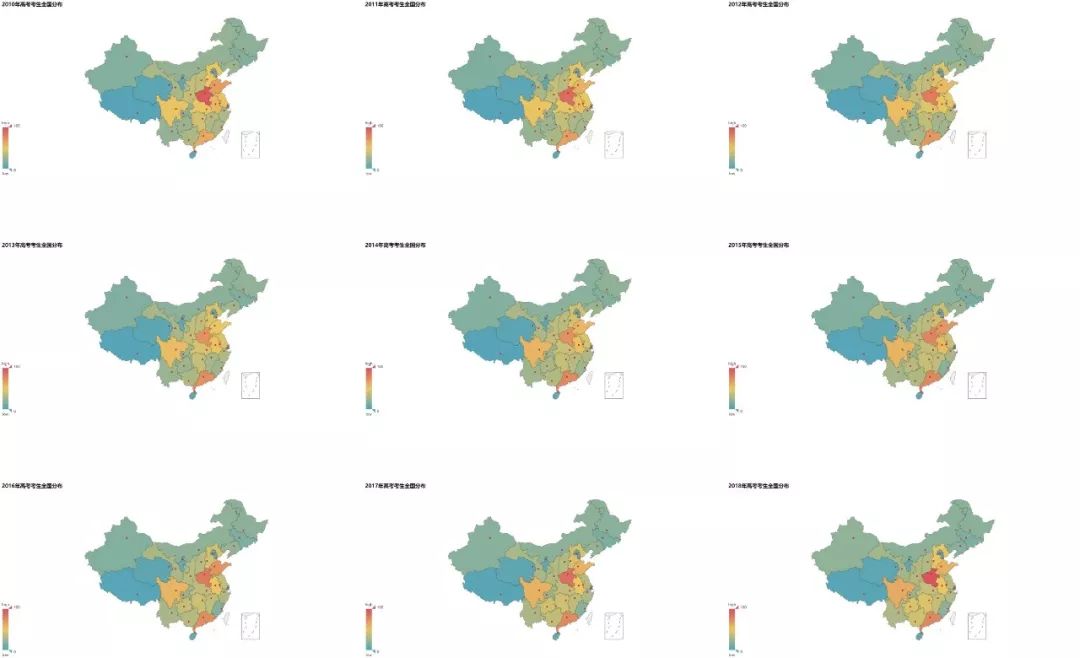
T_T河南的高考考生人数真是一枝独秀。
那么各省的大学数量又是如何分布的呢?以公办本科大学数量作为统计标准,其分布图大概是这样的:
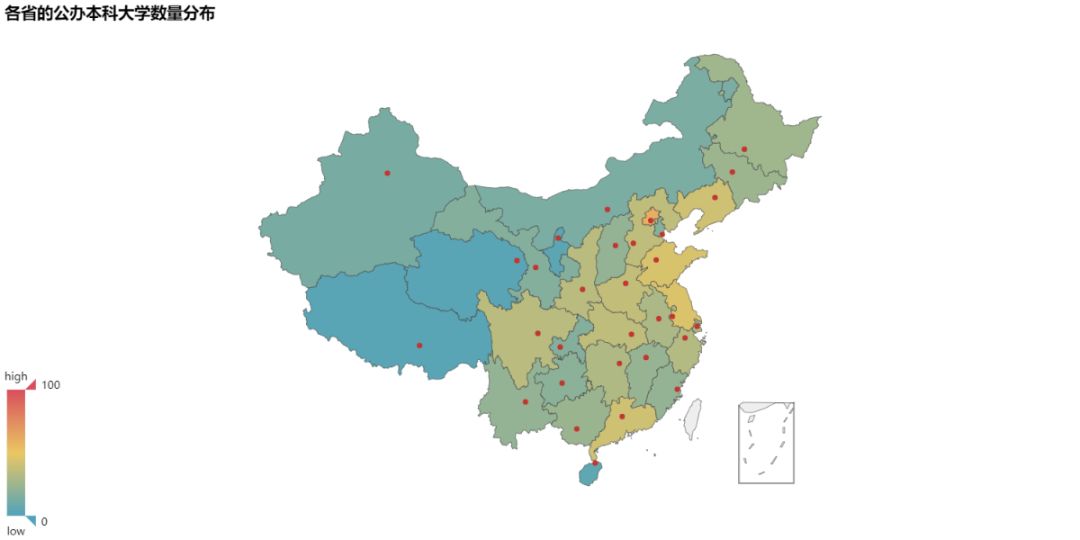
Emmm。北京和江苏分别位居第一和第二名。想想也是必然T_T
那么985&211高校的分布又如何呢?
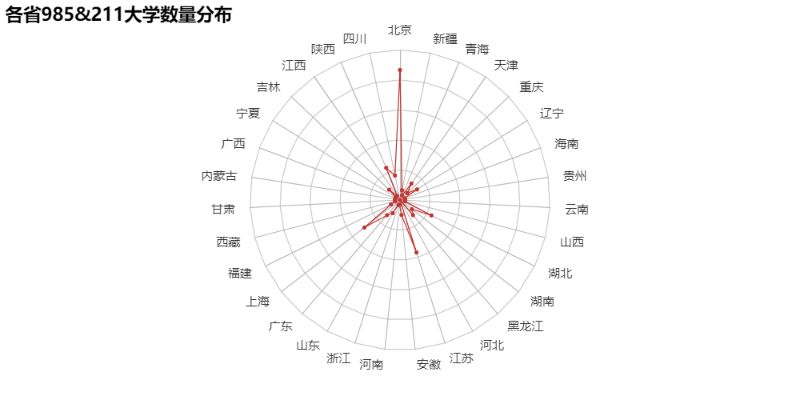
“那就这样吧,再爱都曲终人散了。”看到这个默默不说话了。
以省份为x轴,年份为y轴,该年该省报考的考生人数为z轴来更直观地看看各省每年的高考考生数量变化情况吧:
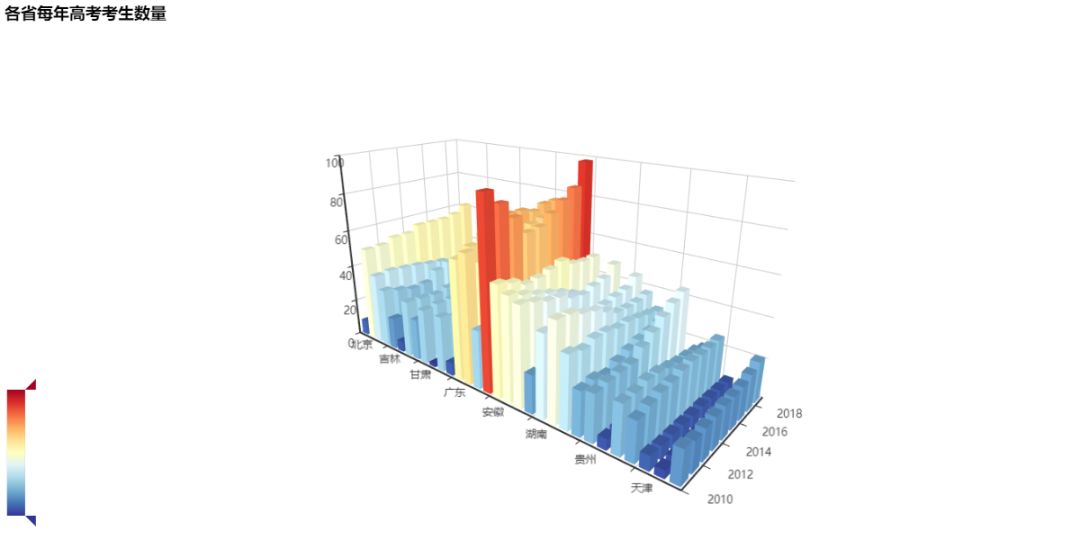
上图中省份的顺序是这样的:
北京、四川、陕西、江西、吉林、宁夏、广西、内蒙古、甘肃、西藏、福建、上海、广东、山东、浙江、河南、安徽、江苏、河北、黑龙江、湖南、湖北、山西、云南、贵州、海南、辽宁、重庆、天津、青海、新疆,台湾因为没有数据,所以没有加入。
T_T河南的高考考生数量真的恐怖。
Emmm,因为可用的数据不多,再分析下去大概就是花式的做图游戏了,想想还是算了吧。至于个人观点,还是不发表为好。毕竟,大家的“哈姆雷特”都不一样。
Python识别垃圾邮件
开发工具
Python版本:3.6.4
相关模块:scikit-learn模块;jieba模块;numpy模块;以及一些Python自带的模块。
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
逐步实现
(1)划分数据集
网上用于垃圾邮件识别的数据集大多是英文邮件,所以为了表示诚意,我花了点时间找了一份中文邮件的数据集。数据集划分如下:
训练数据集:
7063封正常邮件(data/normal文件夹下);
7775封垃圾邮件(data/spam文件夹下)。
测试数据集:
共392封邮件(data/test文件夹下)。
(2)创建词典
数据集里的邮件内容一般是这样的:

首先,我们利用正则表达式过滤掉非中文字符,然后再用jieba分词库对语句进行分词,并清除一些停用词,最后再利用上述结果创建词典,词典格式为:
{"词1": 词1词频, "词2": 词2词频...}
这些内容的具体实现均在"utils.py"文件中体现,在主程序中(train.py)调用即可:

最终结果保存在"results.pkl"文件内。
大功告成了么?当然没有!!!
现在的词典里有52113个词,显然太多了,有些词只出现了一两次,后续特征提取的时候一直空占着一个维度显然是不明智的做法。因此,我们只保留词频最高的4000个词作为最终创建的词典:

最终结果保存在"wordsDict.pkl"文件内。
(3)特征提取
词典准备好之后,我们就可以把每封信的内容转换为词向量了,显然其维度为4000,每一维代表一个高频词在该封信中出现的频率,最后,我们将这些词向量合并为一个大的特征向量矩阵,其大小为:
(7063+7775)×4000
即前7063行为正常邮件的特征向量,其余为垃圾邮件的特征向量。
上述内容的具体实现仍然在"utils.py"文件中体现,在主程序中调用如下:
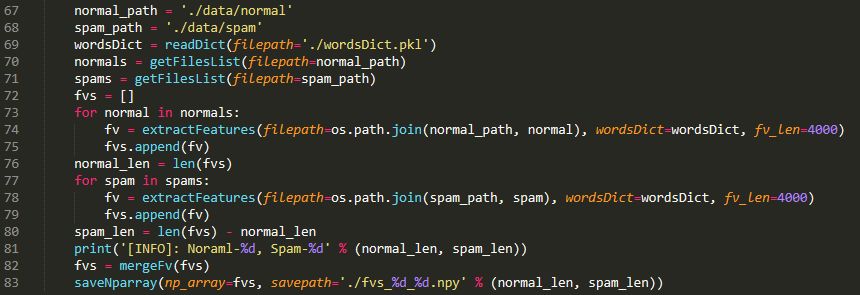
最终结果保存在"fvs_%d_%d.npy"文件内,其中第一个格式符代表正常邮件的数量,第二个格式符代表垃圾邮件的数量。
(4)训练分类器
我们使用scikit-learn机器学习库来训练分类器,模型选择朴素贝叶斯分类器和SVM(支持向量机):
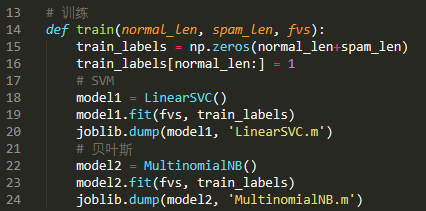
(5)性能测试
利用测试数据集对模型进行测试:
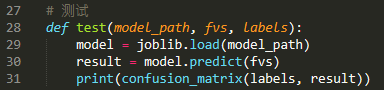
结果如下:


可以发现两个模型的性能是差不多的(SVM略胜于朴素贝叶斯),但SVM更倾向于向垃圾邮件的判定。
That's all~
完整源代码请参见相关文件。
Python实时监控CPU使用率
开发工具
测试系统:Win10和Ubuntu
Python版本:3.5+
相关模块:matplotlib模块;psutil模块。
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
注意:
Ubuntu自带的Python不包含TK模块,需要使用:
sudo apt-get install python3-tk
命令自行安装。
参考文档
psutil文档:
https://psutil.readthedocs.io/en/latest/
matplotlib文档:
https://matplotlib.org/users/index.html
具体实现过程详见相关文件中的源代码。
最近都是比较简单的脚本,没什么原理思路T_T
使用演示
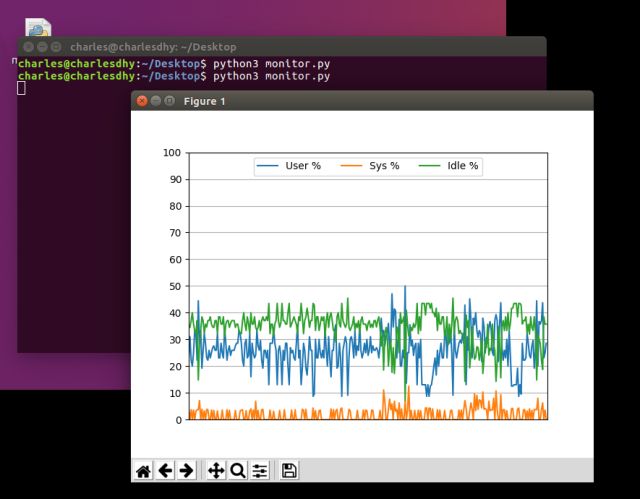
在cmd窗口运行monitor.py文件即可。
运行截图:
(1)Ubuntu
(2)Windows10

Python3制作简单的滑雪游戏
原理介绍
游戏规则:
玩家通过“AD”键或者“←→”操控前进中的滑雪者,努力避开路上的树,尽量捡到路上的小旗。
如果碰到树,则得分减50,如果捡到小旗子,则得分加10。
逐步实现:
Step1:定义精灵类
由于游戏涉及到碰撞检测(滑雪者与树和小旗之间的碰撞),因此我们定义两个精灵类,分别用于代表滑雪者和障碍物(即树和小旗):
其中,滑雪者在前进过程中应当拥有向左,向右偏移的能力,并且在偏移时滑雪者向前的速度应当减慢才更加合乎常理,这样才能供玩家操作。同时,滑雪者应当拥有不同的姿态来表现自己滑行时的状态:
直线:

左偏一点:

左偏很多:
右偏一点:

右偏很多:

另外,尽管滑雪者的左右移动通过移动滑雪者本身实现,但是滑雪者的向前移动是通过移动障碍物实现的。
Step2:随机创建障碍物
现在我们需要定义一个随机创建障碍物的函数,以便在游戏主循环中调用:
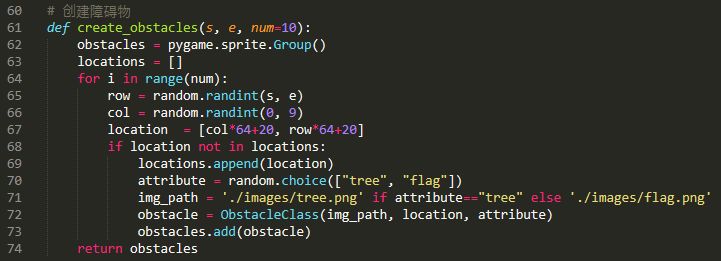
Step3:游戏主循环
首先我们初始化一些参数:
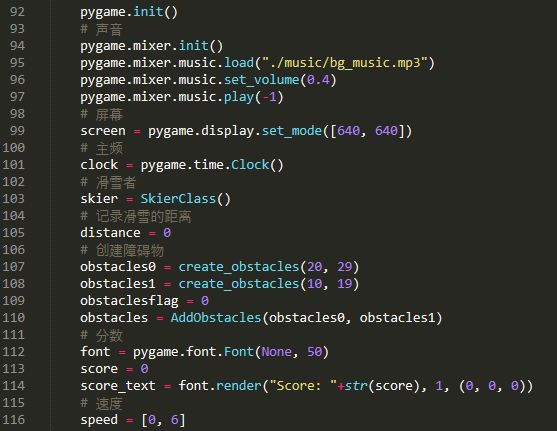
其中障碍物创建两次的目的是便于画面衔接。
然后我们就可以定义主循环了:
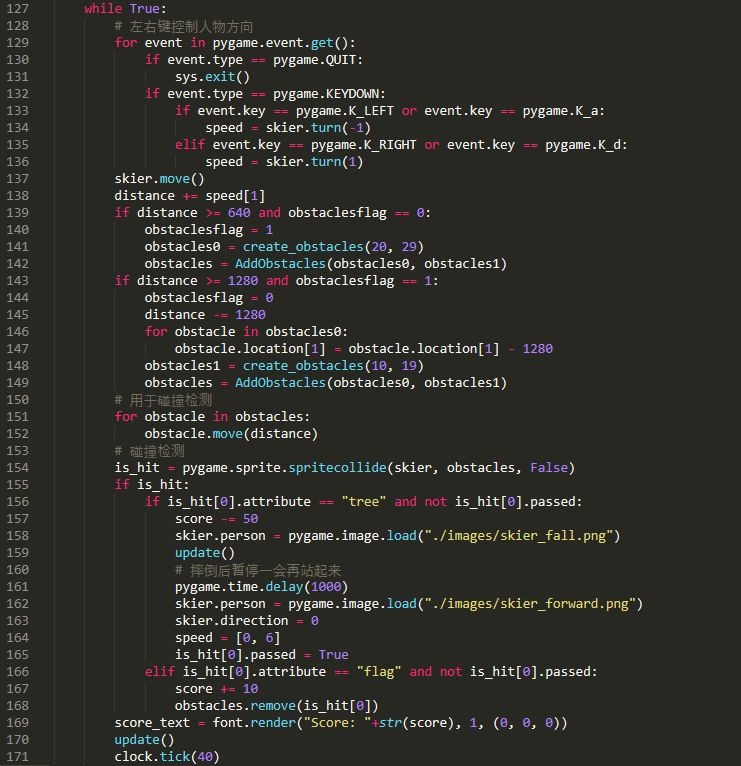
主循环的内容包括:
事件监听、障碍物的更新、碰撞检测以及分数的展示等内容,总之还是很容易实现的。
Step4:其他
开始、结束界面这些,就靠大家自己发挥了,我就写了一个简单的开始界面:
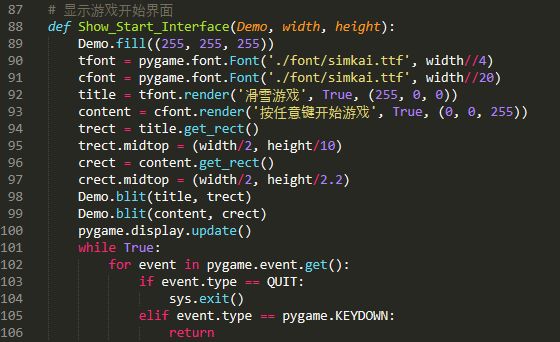
效果:

All Done!
w3cschool-Python3 爬虫抓取、深度/机器学习类的更多相关文章
- 笔趣看小说Python3爬虫抓取
笔趣看小说Python3爬虫抓取 获取HTML信息 解析HTML信息 整合代码 获取HTML信息 # -*- coding:UTF-8 -*- import requests if __name__ ...
- 使用Python3爬虫抓取网页来下载小说
很多时候想看小说但是在网页上找不到资源,即使找到了资源也没有提供下载,小说当然是下载下来用手机看才爽快啦! 于是程序员的思维出来了,不能下载我就直接用爬虫把各个章节爬下来,存入一个txt文件中,这样, ...
- 关于Python3爬虫抓取网页Unicode
import urllib.requestresponse = urllib.request.urlopen('http://www.baidu.com')html = response.read() ...
- python3爬虫抓取智联招聘职位信息代码
上代码,有问题欢迎留言指出. # -*- coding: utf-8 -*- """ Created on Tue Aug 7 20:41:09 2018 @author ...
- Python3简单爬虫抓取网页图片
现在网上有很多python2写的爬虫抓取网页图片的实例,但不适用新手(新手都使用python3环境,不兼容python2), 所以我用Python3的语法写了一个简单抓取网页图片的实例,希望能够帮助到 ...
- 爬虫技术 -- 进阶学习(七)简单爬虫抓取示例(附c#代码)
这是我的第一个爬虫代码...算是一份测试版的代码.大牛大神别喷... 通过给定一个初始的地址startPiont然后对网页进行捕捉,然后通过正则表达式对网址进行匹配. List<string&g ...
- Node.js爬虫抓取数据 -- HTML 实体编码处理办法
cheerio DOM化并解析的时候 1.假如使用了 .text()方法,则一般不会有html实体编码的问题出现 2.如果使用了 .html()方法,则很多情况下(多数是非英文的时候)都会出现,这时, ...
- python 爬虫抓取心得
quanwei9958 转自 python 爬虫抓取心得分享 urllib.quote('要编码的字符串') 如果你要在url请求里面放入中文,对相应的中文进行编码的话,可以用: urllib.quo ...
- 爬虫技术(四)-- 简单爬虫抓取示例(附c#代码)
这是我的第一个爬虫代码...算是一份测试版的代码.大牛大神别喷... 通过给定一个初始的地址startPiont然后对网页进行捕捉,然后通过正则表达式对网址进行匹配. List<string&g ...
- 如何利用Python网络爬虫抓取微信朋友圈的动态(上)
今天小编给大家分享一下如何利用Python网络爬虫抓取微信朋友圈的动态信息,实际上如果单独的去爬取朋友圈的话,难度会非常大,因为微信没有提供向网易云音乐这样的API接口,所以很容易找不到门.不过不要慌 ...
随机推荐
- 0.3 preface
Preface 此书的目的是双重的: 1. 介绍多个领域的背景材料,让学生更好地理解和学习: 2. 详细讲解量子计算和量子信息领域的重要结论,既可以作为学生通识教育的一部分,又可以作为独立研究的前奏. ...
- 鸿蒙NEXT开发案例:转盘
[1]引言(完整代码在最后面) 在鸿蒙NEXT系统中,开发一个有趣且实用的转盘应用不仅可以提升用户体验,还能展示鸿蒙系统的强大功能.本文将详细介绍如何使用鸿蒙NEXT系统开发一个转盘应用,涵盖从组件定 ...
- 国密SSL证书,为政务数据安全保驾护航
随着数字化转型的加速,政务信息化建设已成为提升政府服务效率和质量的关键.近期,国家相关部门发布了<互联网政务应用安全管理规定>,为政务应用的安全管理提供了明确的规范和要求.该规定自2024 ...
- HarmonyOS-Chat聊天室|纯血鸿蒙Next5 api12聊天app|ArkUI仿微信
自研原生鸿蒙NEXT5.0 API12 ArkTS仿微信app聊天模板HarmonyOSChat. harmony-wechat原创重磅实战纯血鸿蒙OS ArkUI+ArkTs仿微信App聊天实例.包 ...
- 软件逆向之OD
OD全称OllyDbg ,是一种具有可视化界面的 32 位汇编-分析调试器.和IDA不同之处在于可以动态调试软件功能,可以有效的去分析程序构成. 以下软件讲解均以吾爱破解中的OD进行讲解.软件下载 打 ...
- golang之项目部署
介绍 Go 语言可以使用内置命令行工具 go build 编译生成可执行文件.自 Go1.5 版本开始实现自举后,交叉编译也很方便,只需使用 GOOS.GOARCH 环境变量指定目标平台和架构. 部署 ...
- Nginx HttpHeader增加几个关键的安全选项
针对像德勤这样的专业渗透测试(Pentest)的场景中,为了确保网站的安全性并通过严格的安全审查,需要为这些安全头配置更细致.专业的参数. 以下是对每个选项的建议以及设置值的详细说明: 1. Stri ...
- NET 6 中新增的LINQ 方法
.NET 6 中添加了许多 LINQ 方法. 下表中列出的大多数新方法在 System.Linq.Queryable 类型中具有等效方法. 欢迎关注 如果你刻意练习某件事情请超过10000小时,那么你 ...
- 【相邻不同型贪心】LeetCode767 重构字符串
题解 通常直接思考最佳策略是十分困难的,我们不妨思考每一种情况需要如何处理: 整个字符串只有一种字符 若字符串长度为 \(1\),那么字符串本身即为答案: 若字符串长度大于等于 \(2\),那么不存在 ...
- Redis应用—2.在列表数据里的应用
大纲 1.基于数据库 + 缓存双写的分享贴功能 2.查询分享贴列表缓存时的延迟构建 3.分页列表惰性缓存方案如何节约内存 4.用户分享贴列表数据按页缓存实现精准过期控制 5.用户分享贴列表的分页缓存的 ...